 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchLattice: Latticed Representation for Sketch Manipulation
Aug 26, 2021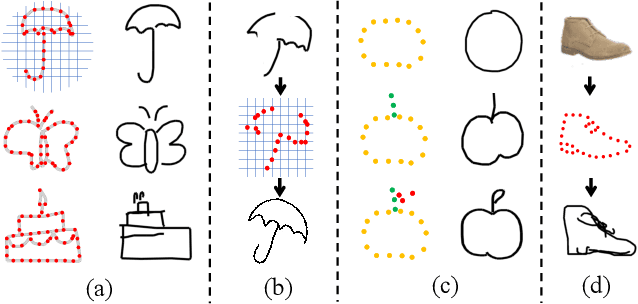

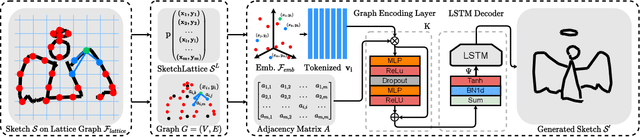
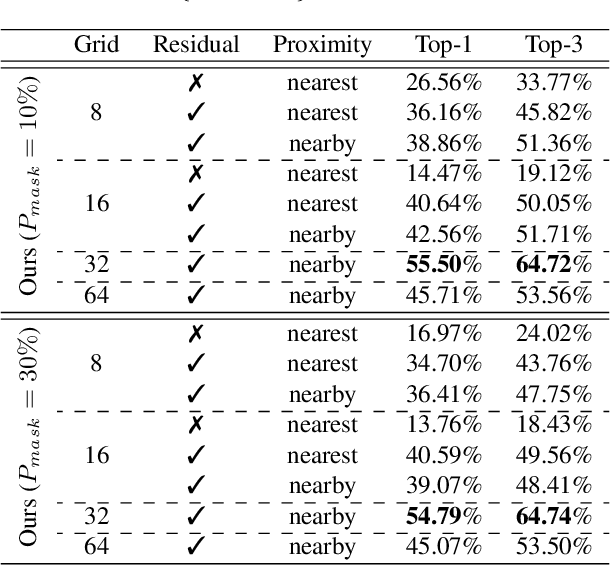
The key challenge in designing a sketch representation lies with handling the abstract and iconic nature of sketches. Existing work predominantly utilizes either, (i) a pixelative format that treats sketches as natural images employing off-the-shelf CNN-based networks, or (ii) an elaborately designed vector format that leverages the structural information of drawing orders using sequential RNN-based methods. While the pixelative format lacks intuitive exploitation of structural cues, sketches in vector format are absent in most cases limiting their practical usage. Hence, in this paper, we propose a lattice structured sketch representation that not only removes the bottleneck of requiring vector data but also preserves the structural cues that vector data provides. Essentially, sketch lattice is a set of points sampled from the pixelative format of the sketch using a lattice graph. We show that our lattice structure is particularly amenable to structural changes that largely benefits sketch abstraction modeling for generation tasks. Our lattice representation could be effectively encoded using a graph model, that uses significantly fewer model parameters (13.5 times lesser) than existing state-of-the-art. Extensive experiments demonstrate the effectiveness of sketch lattice for sketch manipulation, including sketch healing and image-to-sketch synthesis.
Disentangled Lifespan Face Synthesis
Aug 13, 2021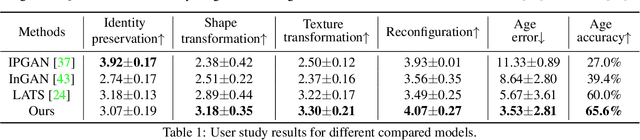
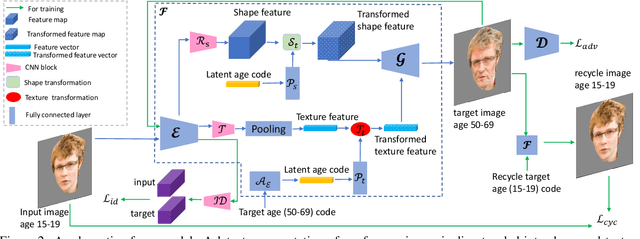
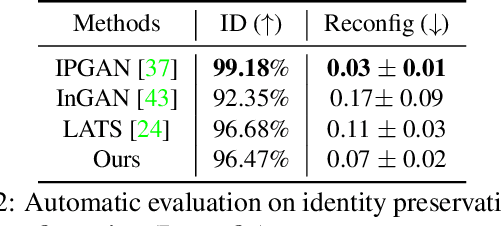

A lifespan face synthesis (LFS) model aims to generate a set of photo-realistic face images of a person's whole life, given only one snapshot as reference. The generated face image given a target age code is expected to be age-sensitive reflected by bio-plausible transformations of shape and texture, while being identity preserving. This is extremely challenging because the shape and texture characteristics of a face undergo separate and highly nonlinear transformations w.r.t. age. Most recent LFS models are based on generative adversarial networks (GANs) whereby age code conditional transformations are applied to a latent face representation. They benefit greatly from the recent advancements of GANs. However, without explicitly disentangling their latent representations into the texture, shape and identity factors, they are fundamentally limited in modeling the nonlinear age-related transformation on texture and shape whilst preserving identity. In this work, a novel LFS model is proposed to disentangle the key face characteristics including shape, texture and identity so that the unique shape and texture age transformations can be modeled effectively. This is achieved by extracting shape, texture and identity features separately from an encoder. Critically, two transformation modules, one conditional convolution based and the other channel attention based, are designed for modeling the nonlinear shape and texture feature transformations respectively. This is to accommodate their rather distinct aging processes and ensure that our synthesized images are both age-sensitive and identity preserving. Extensive experiments show that our LFS model is clearly superior to the state-of-the-art alternatives. Codes and demo are available on our project website: \url{https://senhe.github.io/projects/iccv_2021_lifespan_face}.
Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer
Aug 12, 2021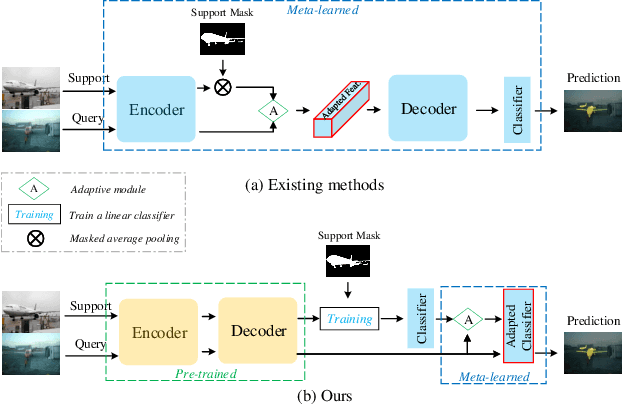
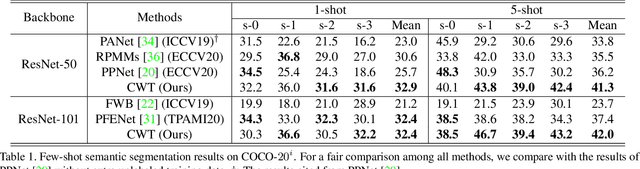

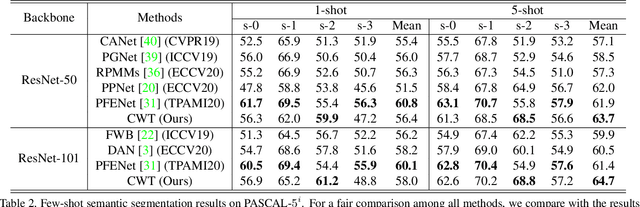
A few-shot semantic segmentation model is typically composed of a CNN encoder, a CNN decoder and a simple classifier (separating foreground and background pixels). Most existing methods meta-learn all three model components for fast adaptation to a new class. However, given that as few as a single support set image is available, effective model adaption of all three components to the new class is extremely challenging. In this work we propose to simplify the meta-learning task by focusing solely on the simplest component, the classifier, whilst leaving the encoder and decoder to pre-training. We hypothesize that if we pre-train an off-the-shelf segmentation model over a set of diverse training classes with sufficient annotations, the encoder and decoder can capture rich discriminative features applicable for any unseen classes, rendering the subsequent meta-learning stage unnecessary. For the classifier meta-learning, we introduce a Classifier Weight Transformer (CWT) designed to dynamically adapt the supportset trained classifier's weights to each query image in an inductive way. Extensive experiments on two standard benchmarks show that despite its simplicity, our method outperforms the state-of-the-art alternatives, often by a large margin.Code is available on https://github.com/zhiheLu/CWT-for-FSS.
Text is Text, No Matter What: Unifying Text Recognition using Knowledge Distillation
Jul 27, 2021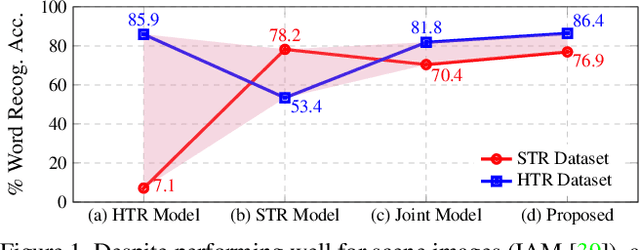

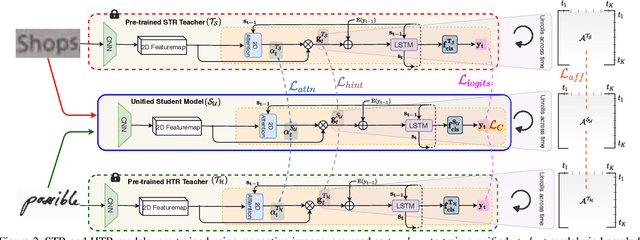
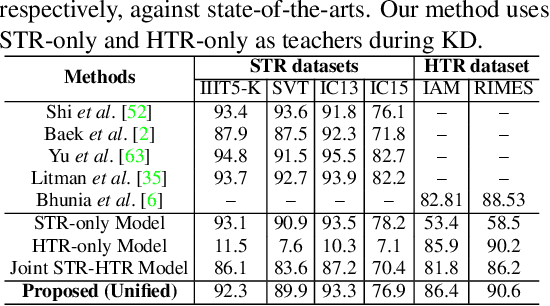
Text recognition remains a fundamental and extensively researched topic in computer vision, largely owing to its wide array of commercial applications. The challenging nature of the very problem however dictated a fragmentation of research efforts: Scene Text Recognition (STR) that deals with text in everyday scenes, and Handwriting Text Recognition (HTR) that tackles hand-written text. In this paper, for the first time, we argue for their unification -- we aim for a single model that can compete favourably with two separate state-of-the-art STR and HTR models. We first show that cross-utilisation of STR and HTR models trigger significant performance drops due to differences in their inherent challenges. We then tackle their union by introducing a knowledge distillation (KD) based framework. This is however non-trivial, largely due to the variable-length and sequential nature of text sequences, which renders off-the-shelf KD techniques that mostly works with global fixed-length data inadequate. For that, we propose three distillation losses all of which are specifically designed to cope with the aforementioned unique characteristics of text recognition. Empirical evidence suggests that our proposed unified model performs on par with individual models, even surpassing them in certain cases. Ablative studies demonstrate that naive baselines such as a two-stage framework, and domain adaption/generalisation alternatives do not work as well, further verifying the appropriateness of our design.
Joint Visual Semantic Reasoning: Multi-Stage Decoder for Text Recognition
Jul 27, 2021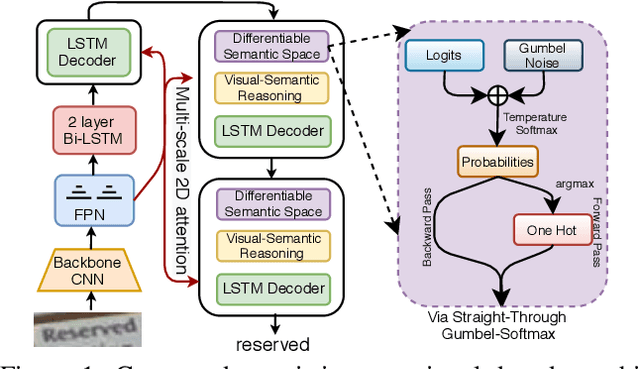
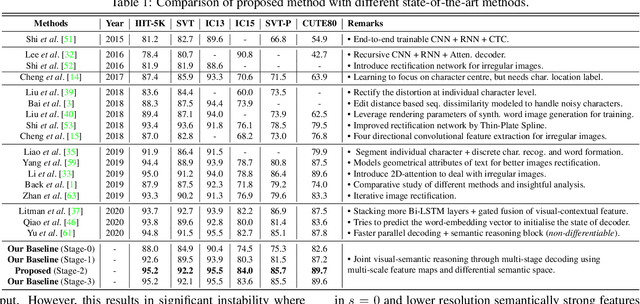
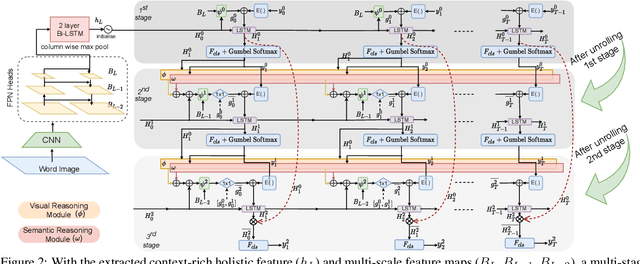
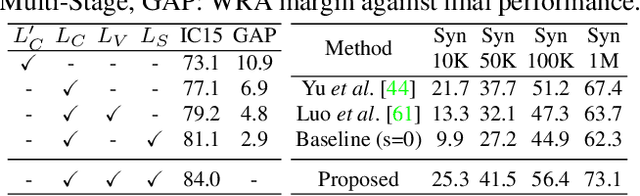
Although text recognition has significantly evolved over the years, state-of-the-art (SOTA) models still struggle in the wild scenarios due to complex backgrounds, varying fonts, uncontrolled illuminations, distortions and other artefacts. This is because such models solely depend on visual information for text recognition, thus lacking semantic reasoning capabilities. In this paper, we argue that semantic information offers a complementary role in addition to visual only. More specifically, we additionally utilize semantic information by proposing a multi-stage multi-scale attentional decoder that performs joint visual-semantic reasoning. Our novelty lies in the intuition that for text recognition, the prediction should be refined in a stage-wise manner. Therefore our key contribution is in designing a stage-wise unrolling attentional decoder where non-differentiability, invoked by discretely predicted character labels, needs to be bypassed for end-to-end training. While the first stage predicts using visual features, subsequent stages refine on top of it using joint visual-semantic information. Additionally, we introduce multi-scale 2D attention along with dense and residual connections between different stages to deal with varying scales of character sizes, for better performance and faster convergence during training. Experimental results show our approach to outperform existing SOTA methods by a considerable margin.
Towards the Unseen: Iterative Text Recognition by Distilling from Errors
Jul 26, 2021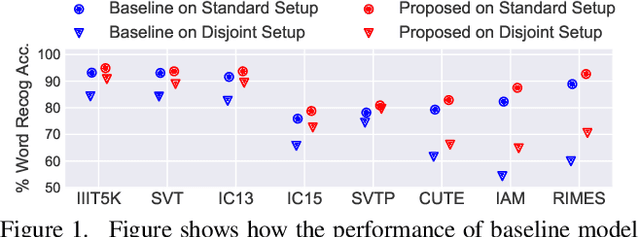
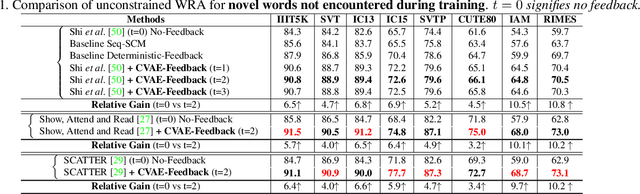
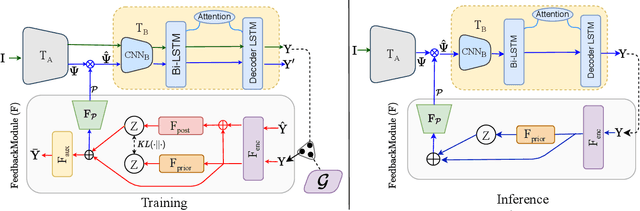

Visual text recognition is undoubtedly one of the most extensively researched topics in computer vision. Great progress have been made to date, with the latest models starting to focus on the more practical "in-the-wild" setting. However, a salient problem still hinders practical deployment -- prior arts mostly struggle with recognising unseen (or rarely seen) character sequences. In this paper, we put forward a novel framework to specifically tackle this "unseen" problem. Our framework is iterative in nature, in that it utilises predicted knowledge of character sequences from a previous iteration, to augment the main network in improving the next prediction. Key to our success is a unique cross-modal variational autoencoder to act as a feedback module, which is trained with the presence of textual error distribution data. This module importantly translate a discrete predicted character space, to a continuous affine transformation parameter space used to condition the visual feature map at next iteration. Experiments on common datasets have shown competitive performance over state-of-the-arts under the conventional setting. Most importantly, under the new disjoint setup where train-test labels are mutually exclusive, ours offers the best performance thus showcasing the capability of generalising onto unseen words.
Towards Unsupervised Sketch-based Image Retrieval
May 18, 2021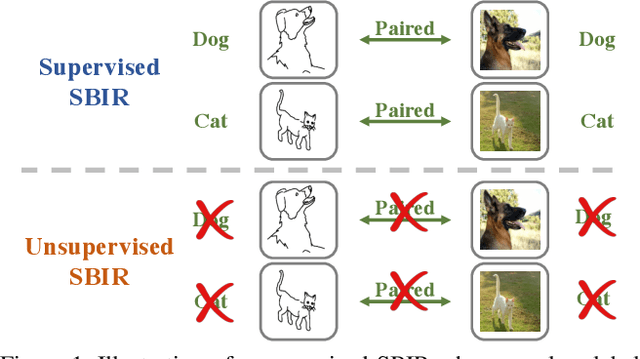
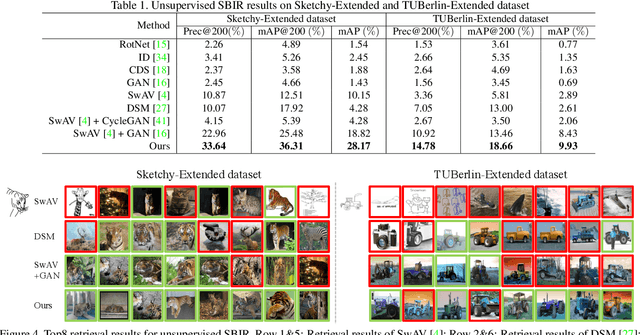


Current supervised sketch-based image retrieval (SBIR) methods achieve excellent performance. However, the cost of data collection and labeling imposes an intractable barrier to practical deployment of real applications. In this paper, we present the first attempt at unsupervised SBIR to remove the labeling cost (category annotations and sketch-photo pairings) that is conventionally needed for training. Existing single-domain unsupervised representation learning methods perform poorly in this application, due to the unique cross-domain (sketch and photo) nature of the problem. We therefore introduce a novel framework that simultaneously performs unsupervised representation learning and sketch-photo domain alignment. Technically this is underpinned by exploiting joint distribution optimal transport (JDOT) to align data from different domains during representation learning, which we extend with trainable cluster prototypes and feature memory banks to further improve scalability and efficacy. Extensive experiments show that our framework achieves excellent performance in the new unsupervised setting, and performs comparably or better than state-of-the-art in the zero-shot setting.
PQA: Perceptual Question Answering
Apr 08, 2021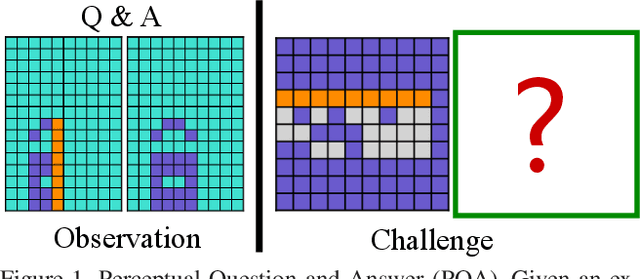

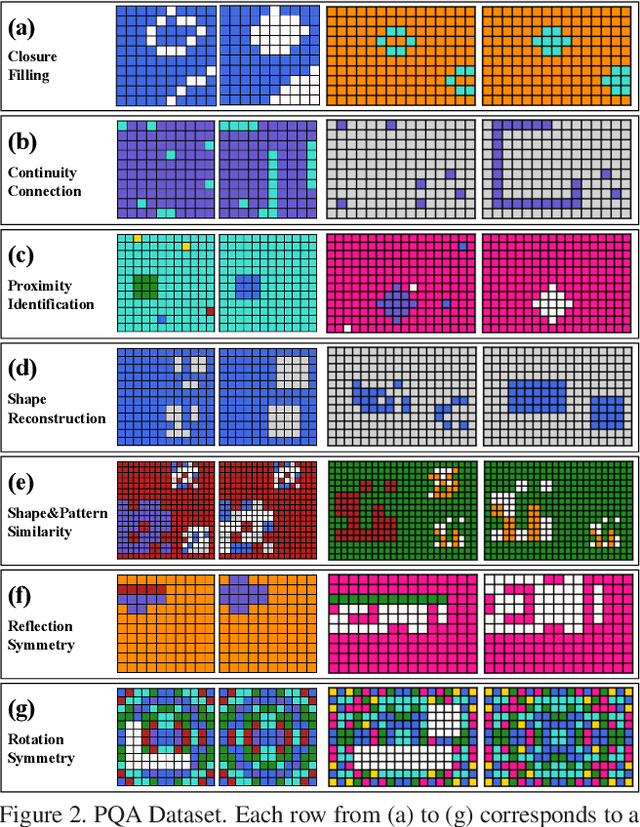
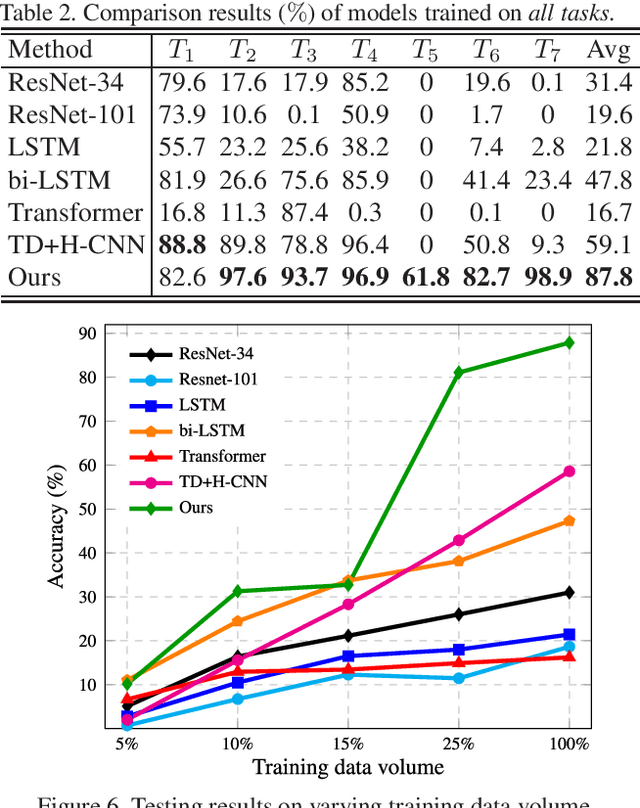
Perceptual organization remains one of the very few established theories on the human visual system. It underpinned many pre-deep seminal works on segmentation and detection, yet research has seen a rapid decline since the preferential shift to learning deep models. Of the limited attempts, most aimed at interpreting complex visual scenes using perceptual organizational rules. This has however been proven to be sub-optimal, since models were unable to effectively capture the visual complexity in real-world imagery. In this paper, we rejuvenate the study of perceptual organization, by advocating two positional changes: (i) we examine purposefully generated synthetic data, instead of complex real imagery, and (ii) we ask machines to synthesize novel perceptually-valid patterns, instead of explaining existing data. Our overall answer lies with the introduction of a novel visual challenge -- the challenge of perceptual question answering (PQA). Upon observing example perceptual question-answer pairs, the goal for PQA is to solve similar questions by generating answers entirely from scratch (see Figure 1). Our first contribution is therefore the first dataset of perceptual question-answer pairs, each generated specifically for a particular Gestalt principle. We then borrow insights from human psychology to design an agent that casts perceptual organization as a self-attention problem, where a proposed grid-to-grid mapping network directly generates answer patterns from scratch. Experiments show our agent to outperform a selection of naive and strong baselines. A human study however indicates that ours uses astronomically more data to learn when compared to an average human, necessitating future research (with or without our dataset).
MetaHTR: Towards Writer-Adaptive Handwritten Text Recognition
Apr 05, 2021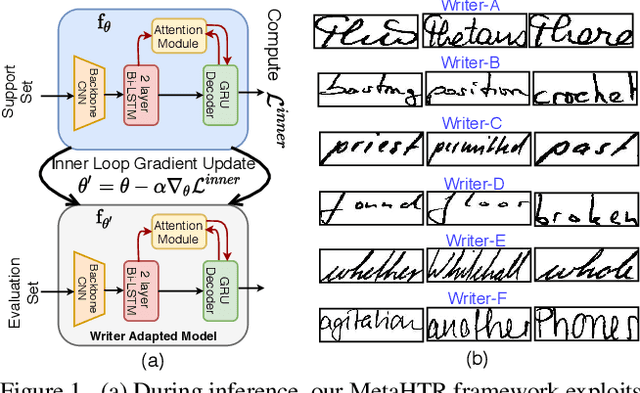


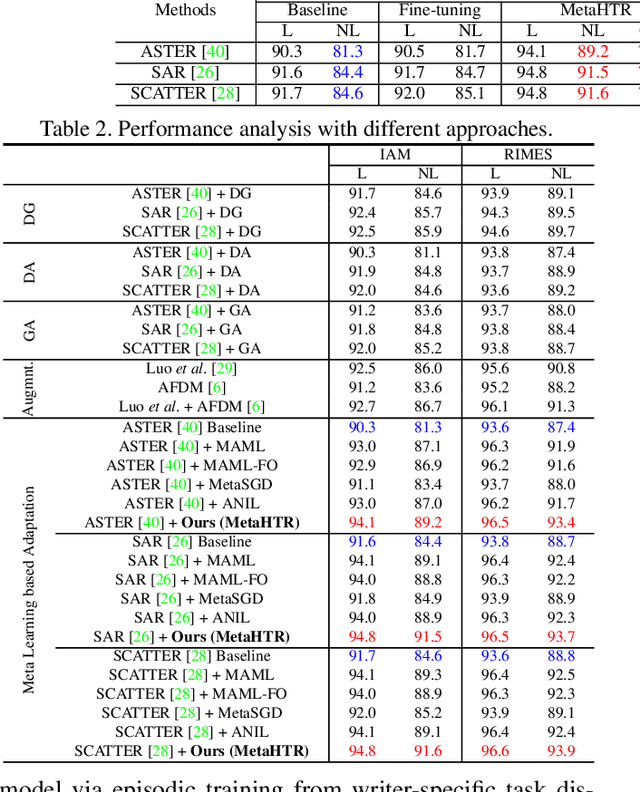
Handwritten Text Recognition (HTR) remains a challenging problem to date, largely due to the varying writing styles that exist amongst us. Prior works however generally operate with the assumption that there is a limited number of styles, most of which have already been captured by existing datasets. In this paper, we take a completely different perspective -- we work on the assumption that there is always a new style that is drastically different, and that we will only have very limited data during testing to perform adaptation. This results in a commercially viable solution -- the model has the best shot at adaptation being exposed to the new style, and the few samples nature makes it practical to implement. We achieve this via a novel meta-learning framework which exploits additional new-writer data through a support set, and outputs a writer-adapted model via single gradient step update, all during inference. We discover and leverage on the important insight that there exists few key characters per writer that exhibit relatively larger style discrepancies. For that, we additionally propose to meta-learn instance specific weights for a character-wise cross-entropy loss, which is specifically designed to work with the sequential nature of text data. Our writer-adaptive MetaHTR framework can be easily implemented on the top of most state-of-the-art HTR models. Experiments show an average performance gain of 5-7% can be obtained by observing very few new style data. We further demonstrate via a set of ablative studies the advantage of our meta design when compared with alternative adaption mechanisms.
StyleMeUp: Towards Style-Agnostic Sketch-Based Image Retrieval
Mar 31, 2021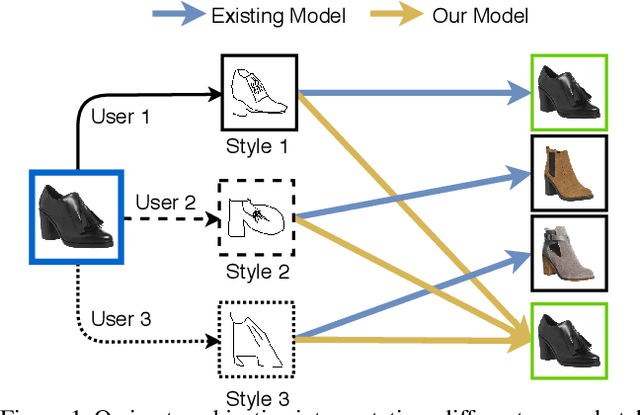
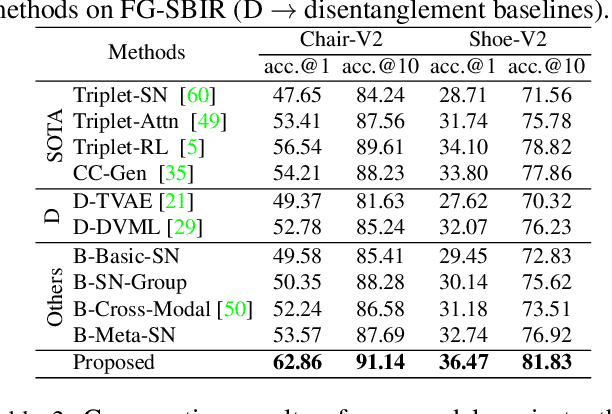
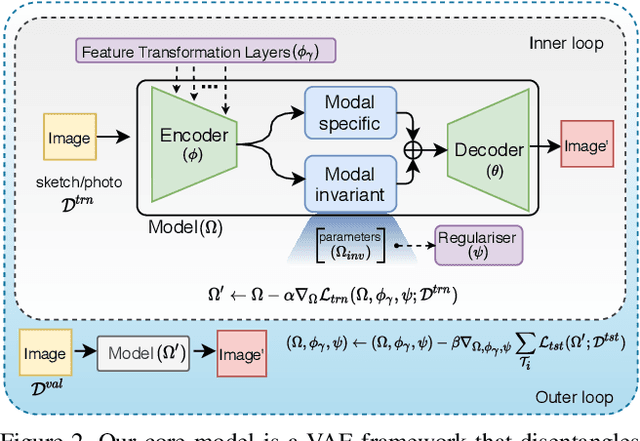
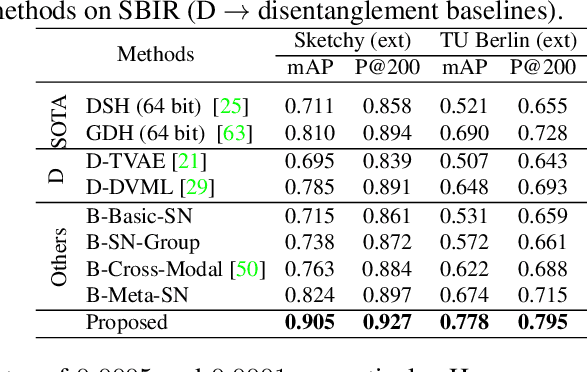
Sketch-based image retrieval (SBIR) is a cross-modal matching problem which is typically solved by learning a joint embedding space where the semantic content shared between photo and sketch modalities are preserved. However, a fundamental challenge in SBIR has been largely ignored so far, that is, sketches are drawn by humans and considerable style variations exist amongst different users. An effective SBIR model needs to explicitly account for this style diversity, crucially, to generalise to unseen user styles. To this end, a novel style-agnostic SBIR model is proposed. Different from existing models, a cross-modal variational autoencoder (VAE) is employed to explicitly disentangle each sketch into a semantic content part shared with the corresponding photo, and a style part unique to the sketcher. Importantly, to make our model dynamically adaptable to any unseen user styles, we propose to meta-train our cross-modal VAE by adding two style-adaptive components: a set of feature transformation layers to its encoder and a regulariser to the disentangled semantic content latent code. With this meta-learning framework, our model can not only disentangle the cross-modal shared semantic content for SBIR, but can adapt the disentanglement to any unseen user style as well, making the SBIR model truly style-agnostic. Extensive experiments show that our style-agnostic model yields state-of-the-art performance for both category-level and instance-level SBIR.