 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Differentiable RANSAC
Dec 26, 2022We propose the fully differentiable $\nabla$-RANSAC.It predicts the inlier probabilities of the input data points, exploits the predictions in a guided sampler, and estimates the model parameters (e.g., fundamental matrix) and its quality while propagating the gradients through the entire procedure. The random sampler in $\nabla$-RANSAC is based on a clever re-parametrization strategy, i.e.\ the Gumbel Softmax sampler, that allows propagating the gradients directly into the subsequent differentiable minimal solver. The model quality function marginalizes over the scores from all models estimated within $\nabla$-RANSAC to guide the network learning accurate and useful probabilities.$\nabla$-RANSAC is the first to unlock the end-to-end training of geometric estimation pipelines, containing feature detection, matching and RANSAC-like randomized robust estimation. As a proof of its potential, we train $\nabla$-RANSAC together with LoFTR, i.e. a recent detector-free feature matcher, to find reliable correspondences in an end-to-end manner. We test $\nabla$-RANSAC on a number of real-world datasets on fundamental and essential matrix estimation. It is superior to the state-of-the-art in terms of accuracy while being among the fastest methods. The code and trained models will be made public.
Contrastive Classification and Representation Learning with Probabilistic Interpretation
Nov 07, 2022



Cross entropy loss has served as the main objective function for classification-based tasks. Widely deployed for learning neural network classifiers, it shows both effectiveness and a probabilistic interpretation. Recently, after the success of self supervised contrastive representation learning methods, supervised contrastive methods have been proposed to learn representations and have shown superior and more robust performance, compared to solely training with cross entropy loss. However, cross entropy loss is still needed to train the final classification layer. In this work, we investigate the possibility of learning both the representation and the classifier using one objective function that combines the robustness of contrastive learning and the probabilistic interpretation of cross entropy loss. First, we revisit a previously proposed contrastive-based objective function that approximates cross entropy loss and present a simple extension to learn the classifier jointly. Second, we propose a new version of the supervised contrastive training that learns jointly the parameters of the classifier and the backbone of the network. We empirically show that our proposed objective functions show a significant improvement over the standard cross entropy loss with more training stability and robustness in various challenging settings.
Wound Severity Classification using Deep Neural Network
Apr 17, 2022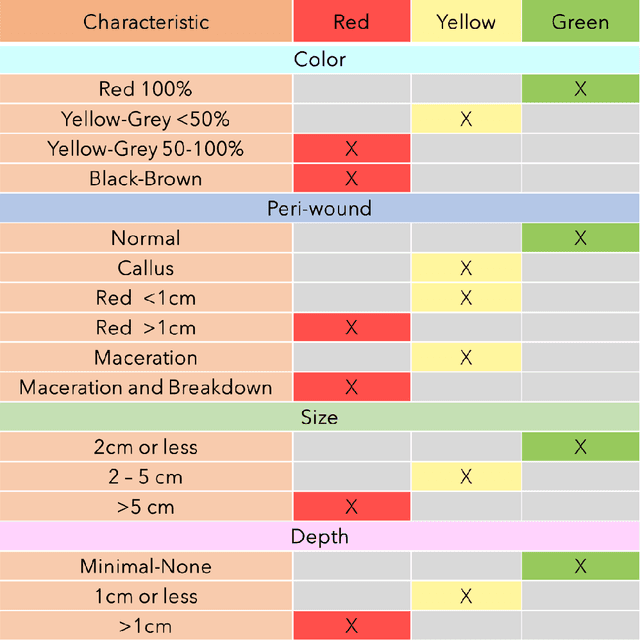
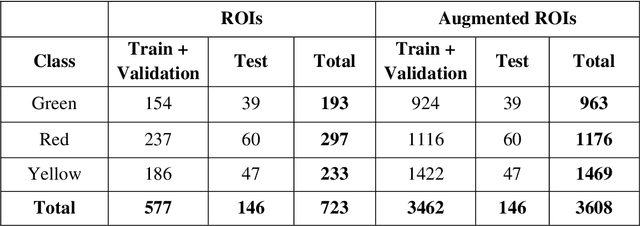
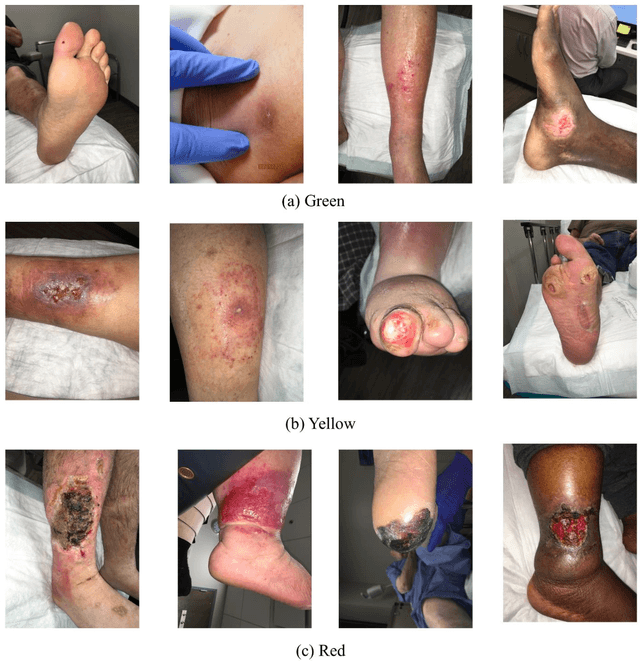
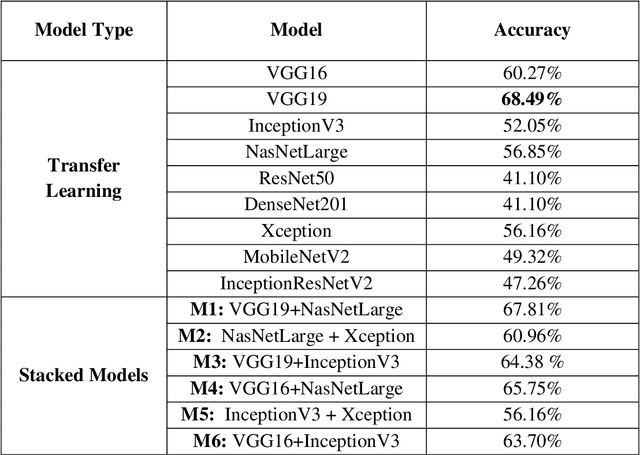
The classification of wound severity is a critical step in wound diagnosis. An effective classifier can help wound professionals categorize wound conditions more quickly and affordably, allowing them to choose the best treatment option. This study used wound photos to construct a deep neural network-based wound severity classifier that classified them into one of three classes: green, yellow, or red. The green class denotes wounds still in the early stages of healing and are most likely to recover with adequate care. Wounds in the yellow category require more attention and treatment than those in the green category. Finally, the red class denotes the most severe wounds that require prompt attention and treatment. A dataset containing different types of wound images is designed with the help of wound specialists. Nine deep learning models are used with applying the concept of transfer learning. Several stacked models are also developed by concatenating these transfer learning models. The maximum accuracy achieved on multi-class classification is 68.49%. In addition, we achieved 78.79%, 81.40%, and 77.57% accuracies on green vs. yellow, green vs. red, and yellow vs. red classifications for binary classifications.
Multi-modal Wound Classification using Wound Image and Location by Deep Neural Network
Sep 14, 2021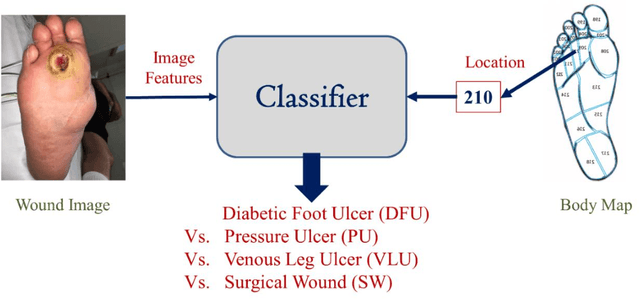
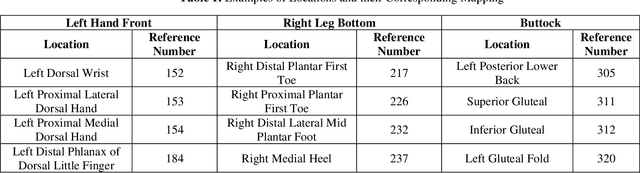
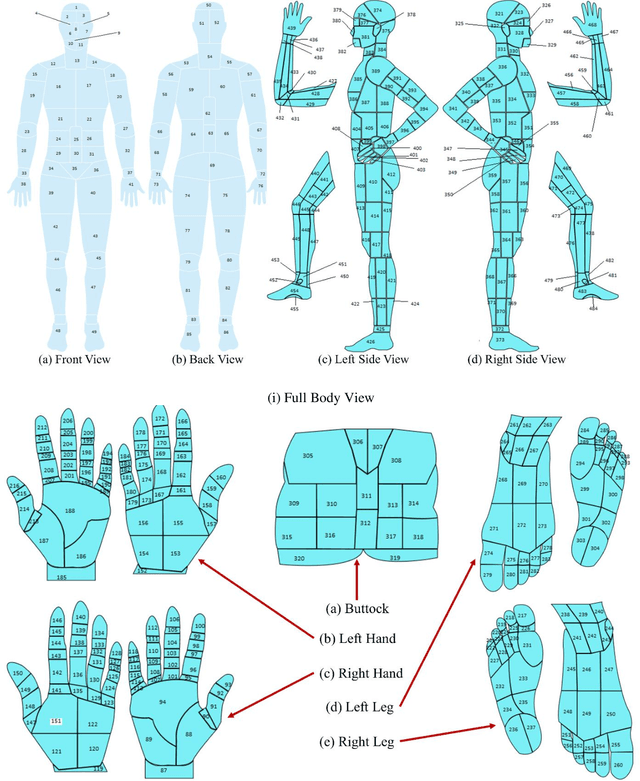
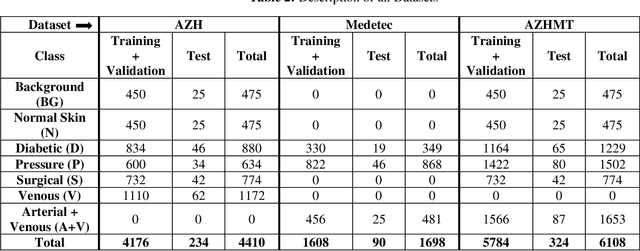
Wound classification is an essential step of wound diagnosis. An efficient classifier can assist wound specialists in classifying wound types with less financial and time costs and help them decide an optimal treatment procedure. This study developed a deep neural network-based multi-modal classifier using wound images and their corresponding locations to categorize wound images into multiple classes, including diabetic, pressure, surgical, and venous ulcers. A body map is also developed to prepare the location data, which can help wound specialists tag wound locations more efficiently. Three datasets containing images and their corresponding location information are designed with the help of wound specialists. The multi-modal network is developed by concatenating the image-based and location-based classifier's outputs with some other modifications. The maximum accuracy on mixed-class classifications (containing background and normal skin) varies from 77.33% to 100% on different experiments. The maximum accuracy on wound-class classifications (containing only diabetic, pressure, surgical, and venous) varies from 72.95% to 98.08% on different experiments. The proposed multi-modal network also shows a significant improvement in results from the previous works of literature.
Recall@k Surrogate Loss with Large Batches and Similarity Mixup
Aug 25, 2021
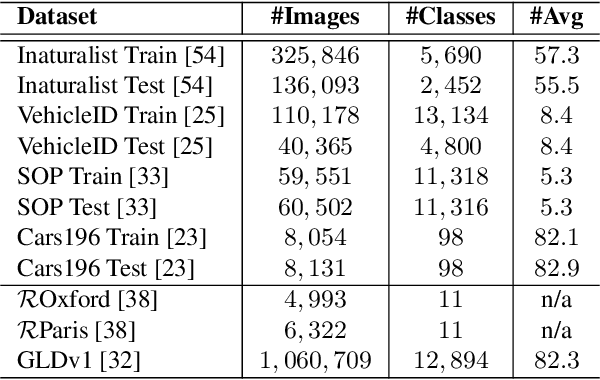
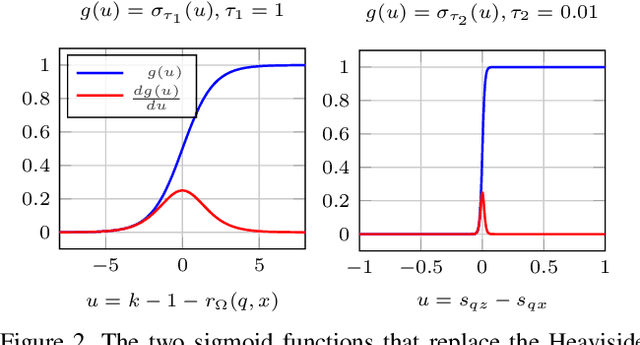
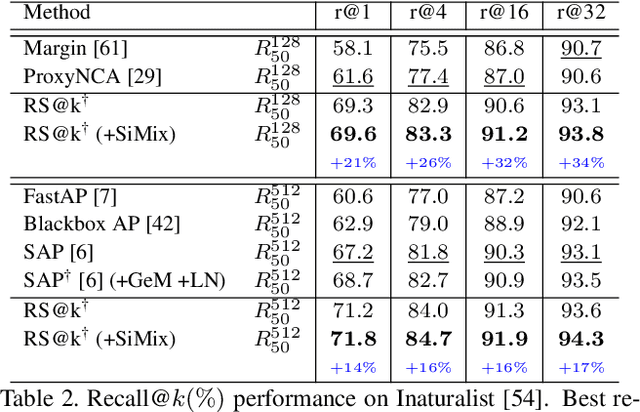
Direct optimization, by gradient descent, of an evaluation metric, is not possible when it is non-differentiable, which is the case for recall in retrieval. In this work, a differentiable surrogate loss for the recall is proposed. Using an implementation that sidesteps the hardware constraints of the GPU memory, the method trains with a very large batch size, which is essential for metrics computed on the entire retrieval database. It is assisted by an efficient mixup approach that operates on pairwise scalar similarities and virtually increases the batch size further. When used for deep metric learning, the proposed method achieves state-of-the-art results in several image retrieval benchmarks. For instance-level recognition, the method outperforms similar approaches that train using an approximation of average precision. The implementation will be made public.
FEDS -- Filtered Edit Distance Surrogate
Mar 08, 2021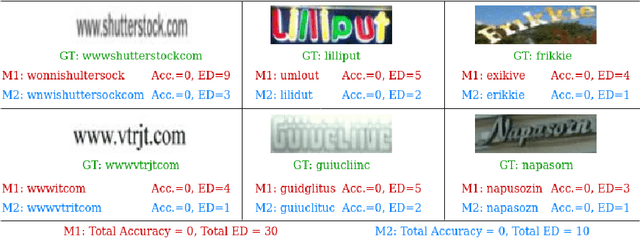
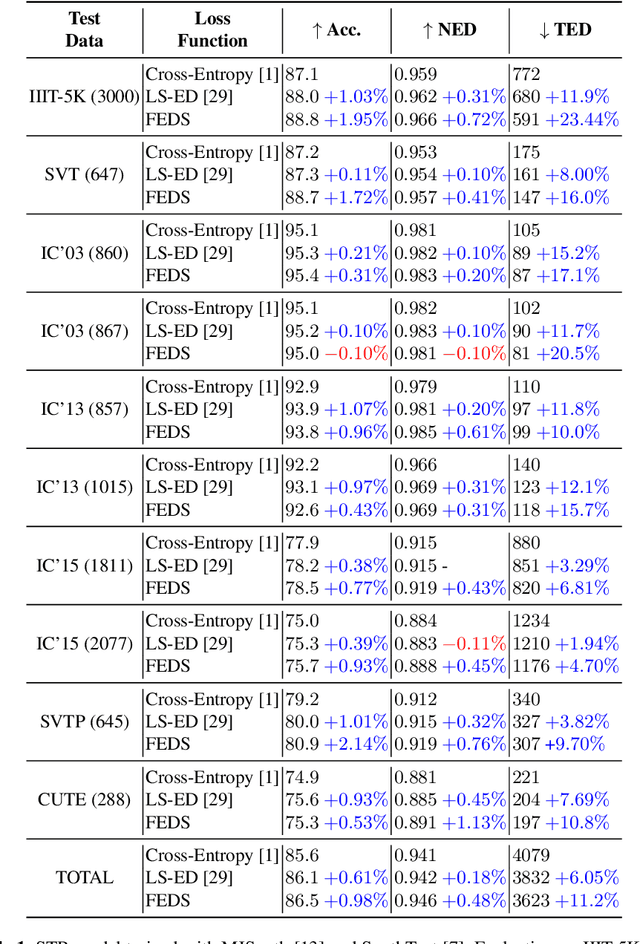
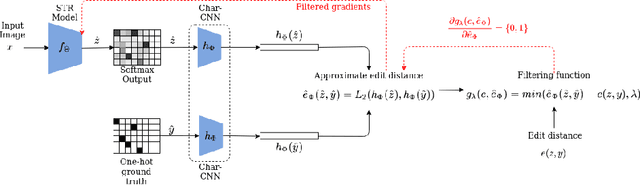
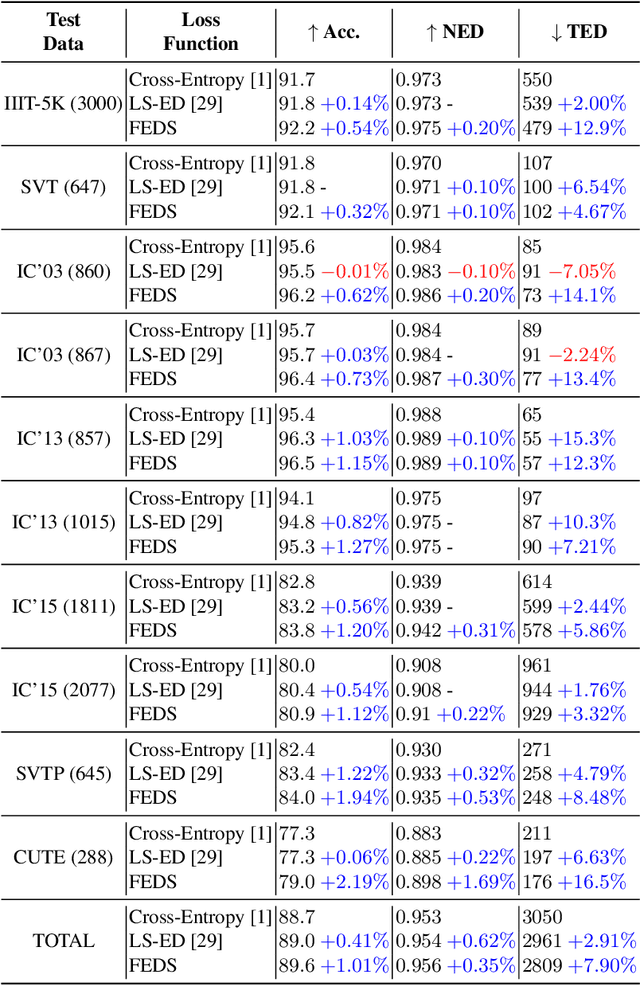
This paper proposes a procedure to robustly train a scene text recognition model using a learned surrogate of edit distance. The proposed method borrows from self-paced learning and filters out the training examples that are hard for the surrogate. The filtering is performed by judging the quality of the approximation, using a ramp function, which is piece-wise differentiable, enabling end-to-end training. Following the literature, the experiments are conducted in a post-tuning setup, where a trained scene text recognition model is tuned using the learned surrogate of edit distance. The efficacy is demonstrated by improvements on various challenging scene text datasets such as IIIT-5K, SVT, ICDAR, SVTP, and CUTE. The proposed method provides an average improvement of $11.2 \%$ on total edit distance and an error reduction of $9.5\%$ on accuracy.
Neural Network-based Acoustic Vehicle Counting
Oct 22, 2020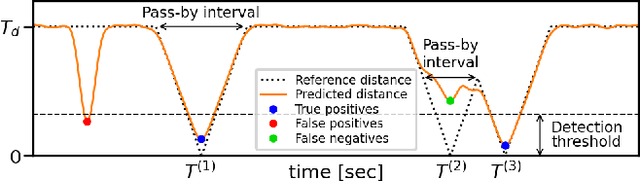

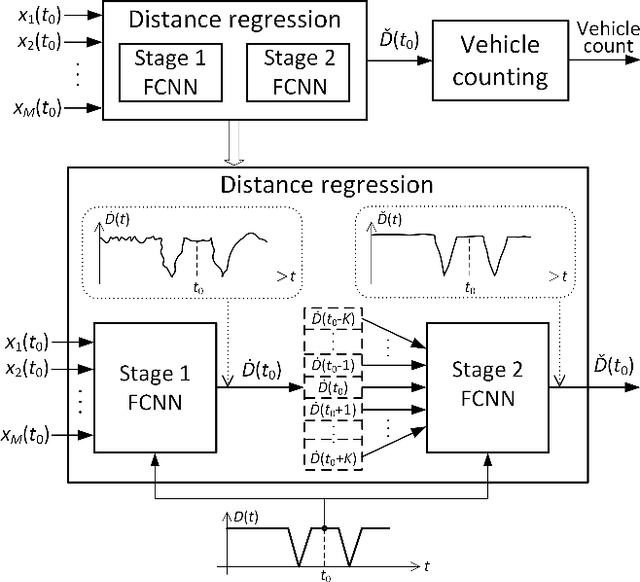
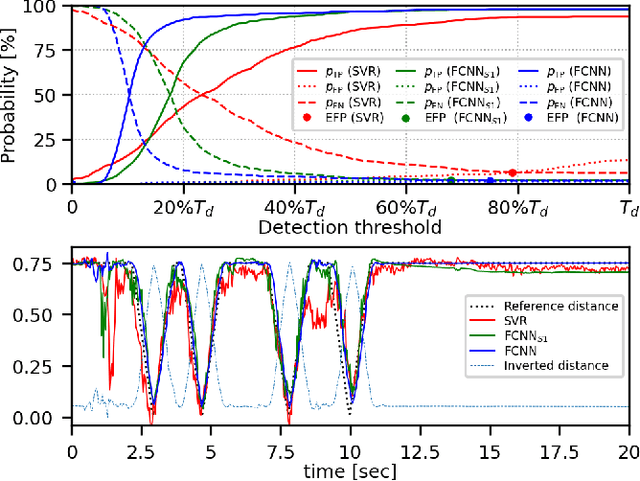
This paper addresses acoustic vehicle counting using one-channel audio. We predict the pass-by instants of vehicles from local minima of a vehicle-to-microphone distance predicted from audio. The distance is predicted via a two-stage (coarse-fine) regression, both realised using neural networks (NNs). Experiments show that the NN-based distance regression outperforms by far the previously proposed support vector regression. The $ 95\% $ confidence interval for the mean of vehicle counting error is within $[0.28\%, -0.55\%]$. Besides the minima-based counting, we propose a deep learning counting which operates on the predicted distance without detecting local minima. Results also show that removing low frequencies in features improves the counting performance.
A Mobile App for Wound Localization using Deep Learning
Sep 15, 2020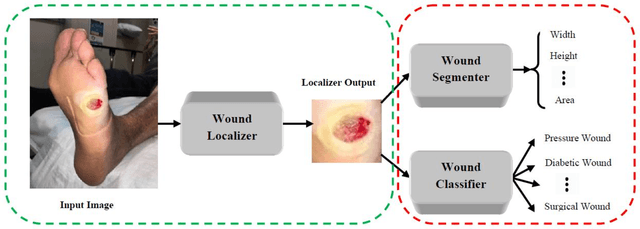
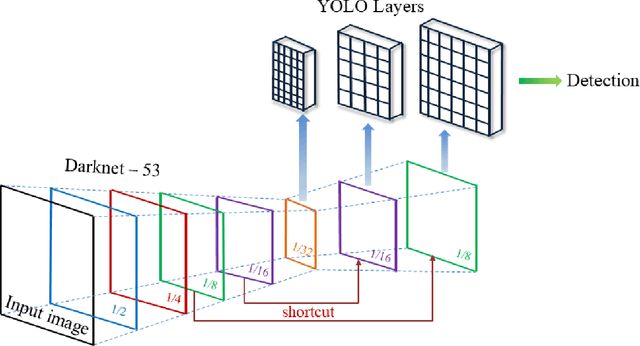
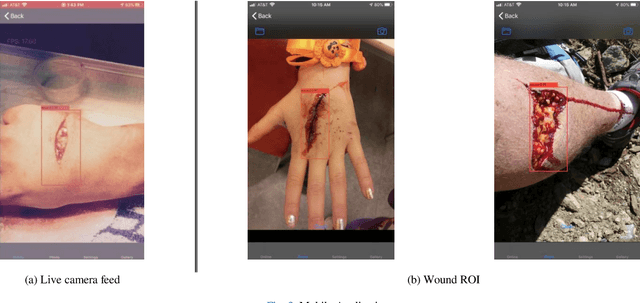
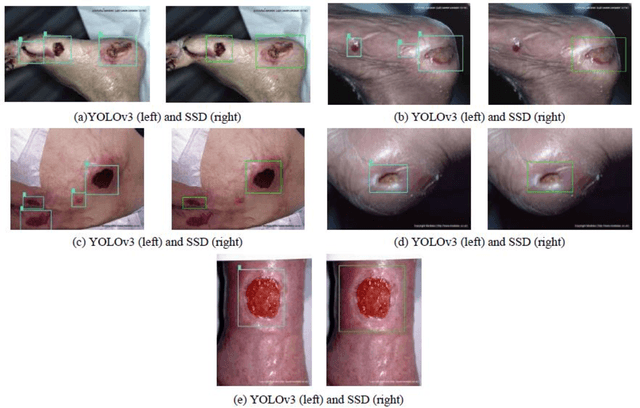
We present an automated wound localizer from 2D wound and ulcer images by using deep neural network, as the first step towards building an automated and complete wound diagnostic system. The wound localizer has been developed by using YOLOv3 model, which is then turned into an iOS mobile application. The developed localizer can detect the wound and its surrounding tissues and isolate the localized wounded region from images, which would be very helpful for future processing such as wound segmentation and classification due to the removal of unnecessary regions from wound images. For Mobile App development with video processing, a lighter version of YOLOv3 named tiny-YOLOv3 has been used. The model is trained and tested on our own image dataset in collaboration with AZH Wound and Vascular Center, Milwaukee, Wisconsin. The YOLOv3 model is compared with SSD model, showing that YOLOv3 gives a mAP value of 93.9%, which is much better than the SSD model (86.4%). The robustness and reliability of these models are also tested on a publicly available dataset named Medetec and shows a very good performance as well.
Learning Surrogates via Deep Embedding
Jul 17, 2020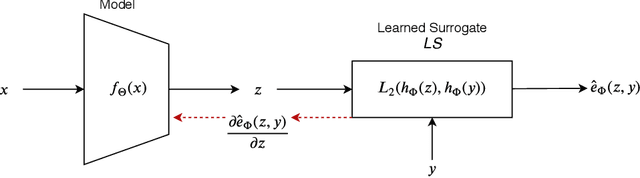
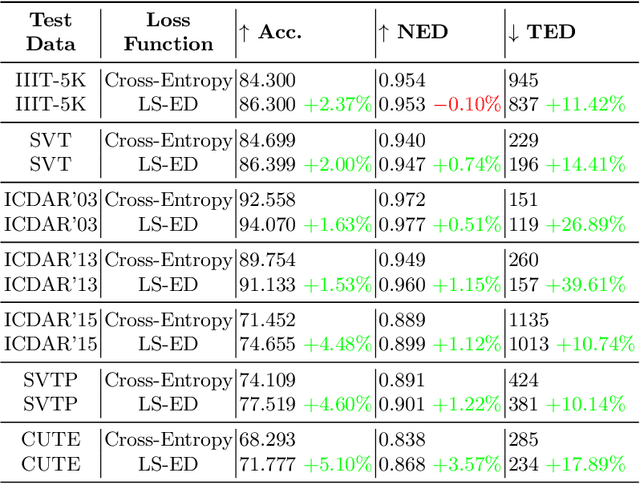
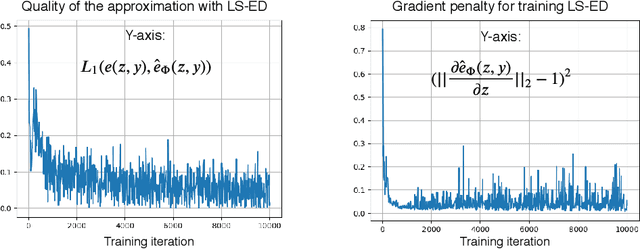
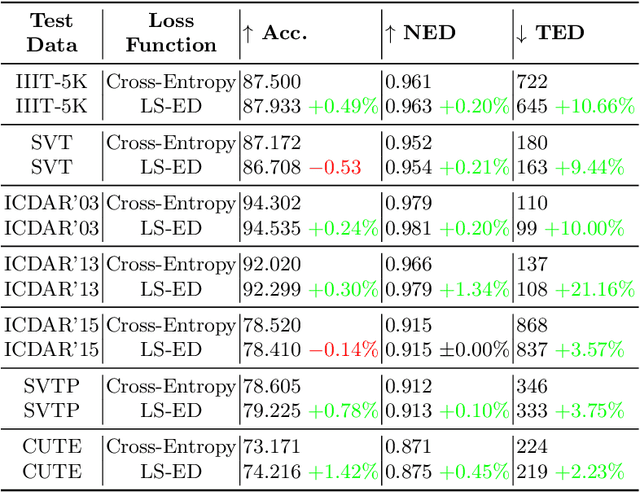
This paper proposes a technique for training a neural network by minimizing a surrogate loss that approximates the target evaluation metric, which may be non-differentiable. The surrogate is learned via a deep embedding where the Euclidean distance between the prediction and the ground truth corresponds to the value of the evaluation metric. The effectiveness of the proposed technique is demonstrated in a post-tuning setup, where a trained model is tuned using the learned surrogate. Without a significant computational overhead and any bells and whistles, improvements are demonstrated on challenging and practical tasks of scene-text recognition and detection. In the recognition task, the model is tuned using a surrogate approximating the edit distance metric and achieves up to $39\%$ relative improvement in the total edit distance. In the detection task, the surrogate approximates the intersection over union metric for rotated bounding boxes and yields up to $4.25\%$ relative improvement in the $F_{1}$ score.
Hierarchical Auto-Regressive Model for Image Compression Incorporating Object Saliency and a Deep Perceptual Loss
Feb 12, 2020



We propose a new end-to-end trainable model for lossy image compression which includes a number of novel components. This approach incorporates 1) a hierarchical auto-regressive model; 2)it also incorporates saliency in the images and focuses on reconstructing the salient regions better; 3) in addition, we empirically demonstrate that the popularly used evaluations metrics such as MS-SSIM and PSNR are inadequate for judging the performance of deep learned image compression techniques as they do not align well with human perceptual similarity. We, therefore propose an alternative metric, which is learned on perceptual similarity data specific to image compression. Our experiments show that this new metric aligns significantly better with human judgments when compared to other hand-crafted or learned metrics. The proposed compression model not only generates images that are visually better but also gives superior performance for subsequent computer vision tasks such as object detection and segmentation when compared to other engineered or learned codecs.