 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Word Decomposition Models for Abusive Language Detection
Oct 02, 2019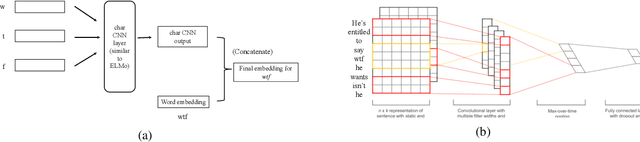
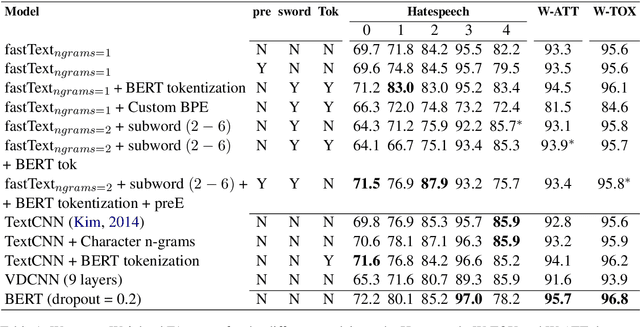
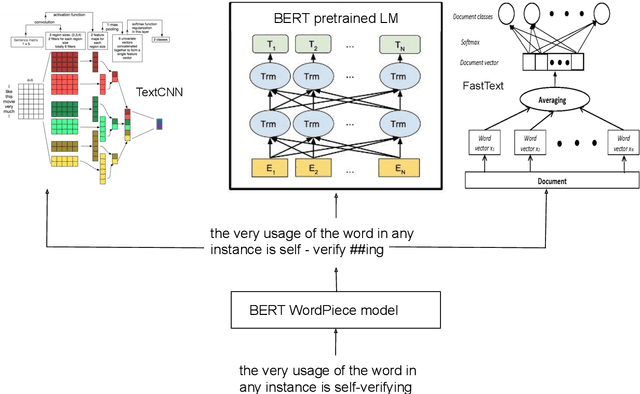
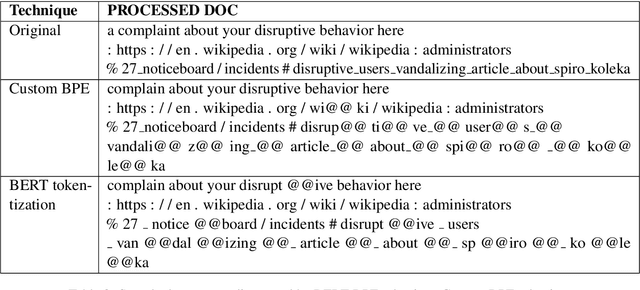
User generated text on social media often suffers from a lot of undesired characteristics including hatespeech, abusive language, insults etc. that are targeted to attack or abuse a specific group of people. Often such text is written differently compared to traditional text such as news involving either explicit mention of abusive words, obfuscated words and typological errors or implicit abuse i.e., indicating or targeting negative stereotypes. Thus, processing this text poses several robustness challenges when we apply natural language processing techniques developed for traditional text. For example, using word or token based models to process such text can treat two spelling variants of a word as two different words. Following recent work, we analyze how character, subword and byte pair encoding (BPE) models can be aid some of the challenges posed by user generated text. In our work, we analyze the effectiveness of each of the above techniques, compare and contrast various word decomposition techniques when used in combination with others. We experiment with finetuning large pretrained language models, and demonstrate their robustness to domain shift by studying Wikipedia attack, toxicity and Twitter hatespeech datasets
* Accepted at ALW Workshop at ACL2019, Florence; BERT has a WordPiece model and it enhances performance of word based models in noisy settings
Training Neural Machine Translation To Apply Terminology Constraints
Jun 03, 2019
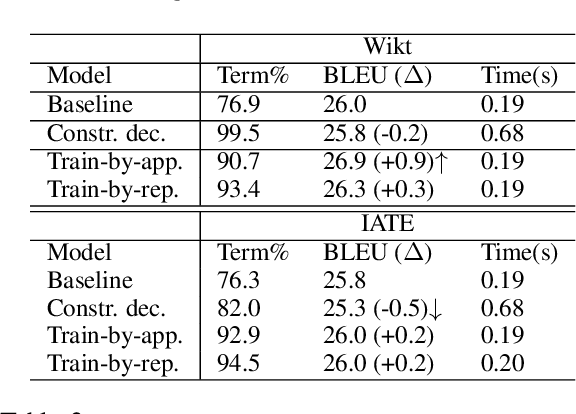

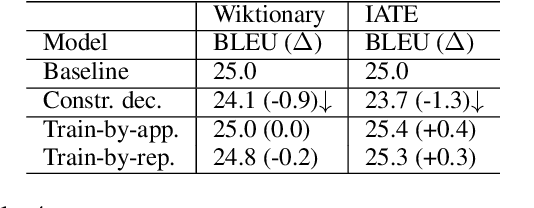
This paper proposes a novel method to inject custom terminology into neural machine translation at run time. Previous works have mainly proposed modifications to the decoding algorithm in order to constrain the output to include run-time-provided target terms. While being effective, these constrained decoding methods add, however, significant computational overhead to the inference step, and, as we show in this paper, can be brittle when tested in realistic conditions. In this paper we approach the problem by training a neural MT system to learn how to use custom terminology when provided with the input. Comparative experiments show that our method is not only more effective than a state-of-the-art implementation of constrained decoding, but is also as fast as constraint-free decoding.
Ensemble Distillation for Neural Machine Translation
Aug 08, 2017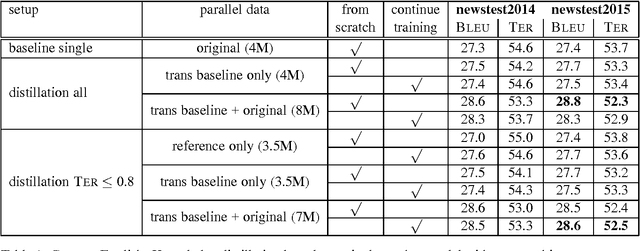
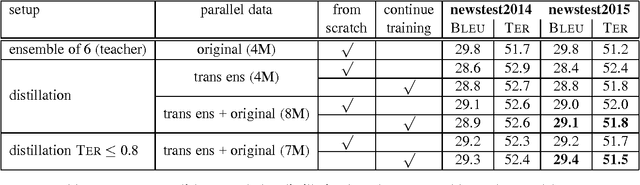
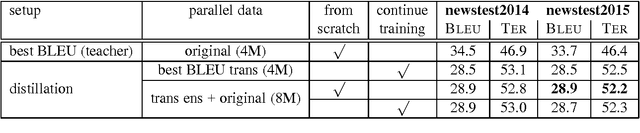
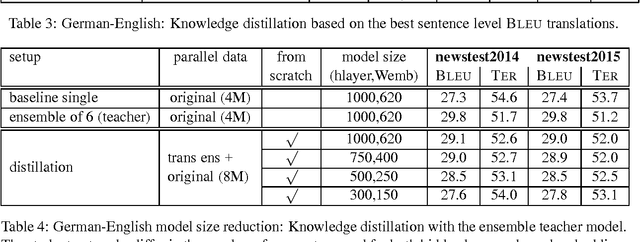
Knowledge distillation describes a method for training a student network to perform better by learning from a stronger teacher network. Translating a sentence with an Neural Machine Translation (NMT) engine is time expensive and having a smaller model speeds up this process. We demonstrate how to transfer the translation quality of an ensemble and an oracle BLEU teacher network into a single NMT system. Further, we present translation improvements from a teacher network that has the same architecture and dimensions of the student network. As the training of the student model is still expensive, we introduce a data filtering method based on the knowledge of the teacher model that not only speeds up the training, but also leads to better translation quality. Our techniques need no code change and can be easily reproduced with any NMT architecture to speed up the decoding process.
AMR Parsing using Stack-LSTMs
Aug 02, 2017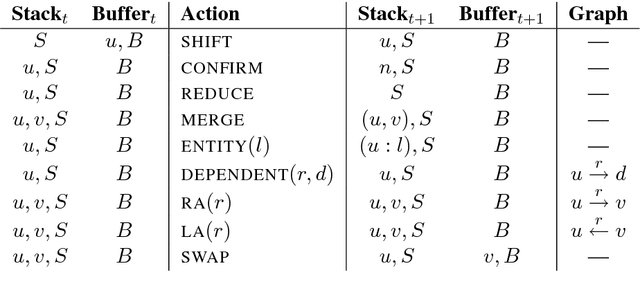
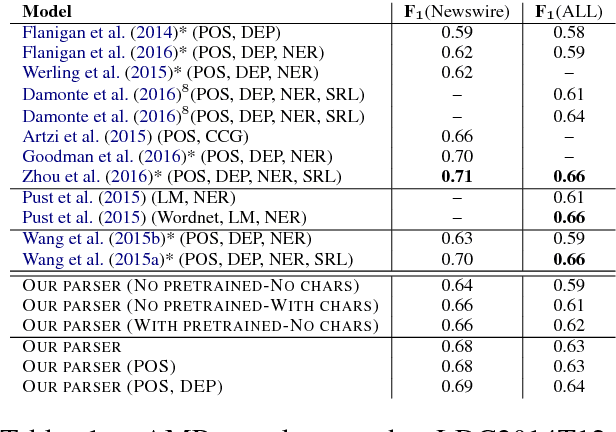

We present a transition-based AMR parser that directly generates AMR parses from plain text. We use Stack-LSTMs to represent our parser state and make decisions greedily. In our experiments, we show that our parser achieves very competitive scores on English using only AMR training data. Adding additional information, such as POS tags and dependency trees, improves the results further.
Beam Search Strategies for Neural Machine Translation
Jun 14, 2017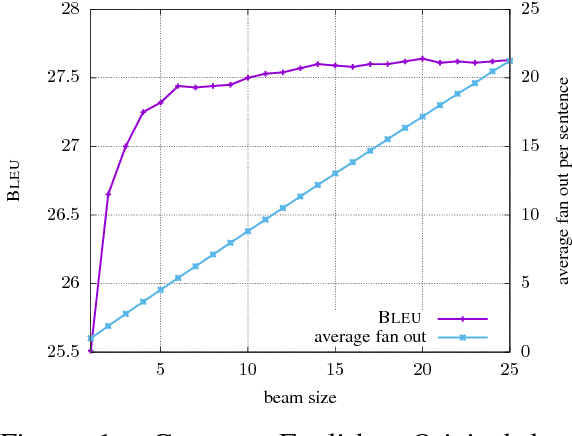
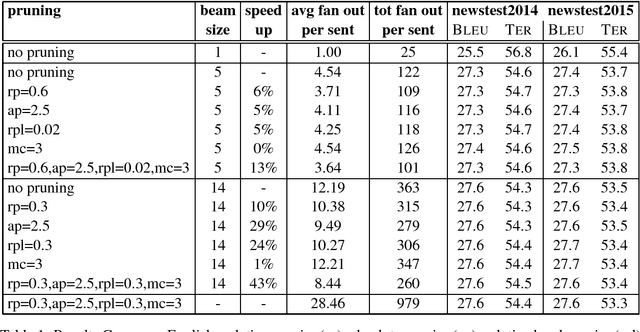
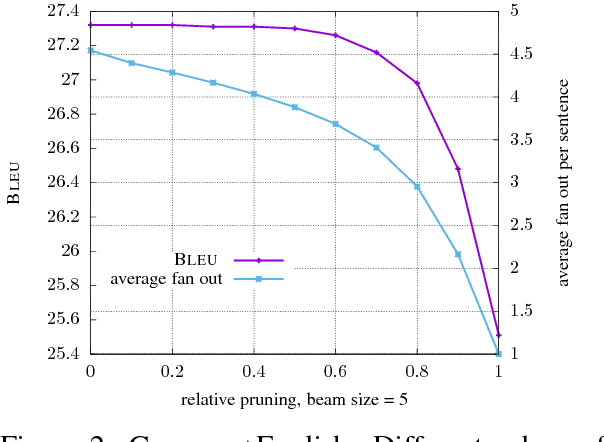
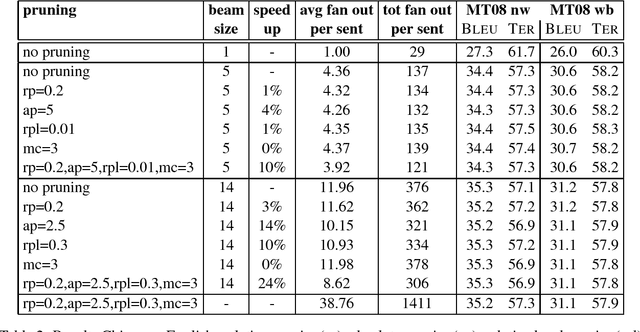
The basic concept in Neural Machine Translation (NMT) is to train a large Neural Network that maximizes the translation performance on a given parallel corpus. NMT is then using a simple left-to-right beam-search decoder to generate new translations that approximately maximize the trained conditional probability. The current beam search strategy generates the target sentence word by word from left-to- right while keeping a fixed amount of active candidates at each time step. First, this simple search is less adaptive as it also expands candidates whose scores are much worse than the current best. Secondly, it does not expand hypotheses if they are not within the best scoring candidates, even if their scores are close to the best one. The latter one can be avoided by increasing the beam size until no performance improvement can be observed. While you can reach better performance, this has the draw- back of a slower decoding speed. In this paper, we concentrate on speeding up the decoder by applying a more flexible beam search strategy whose candidate size may vary at each time step depending on the candidate scores. We speed up the original decoder by up to 43% for the two language pairs German-English and Chinese-English without losing any translation quality.
Attention-based Vocabulary Selection for NMT Decoding
Jun 12, 2017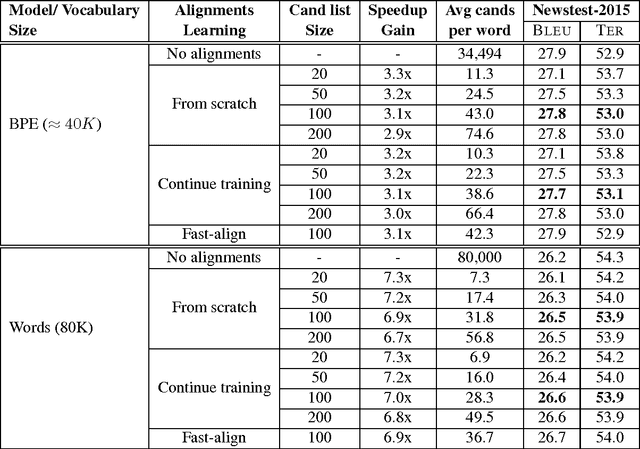
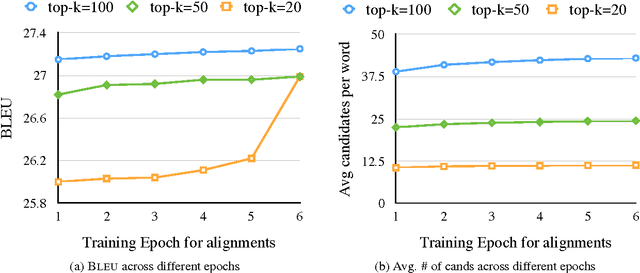
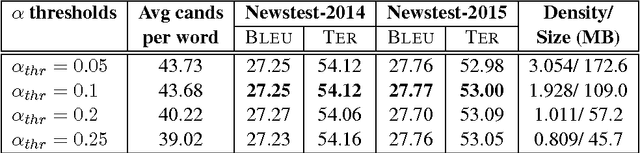
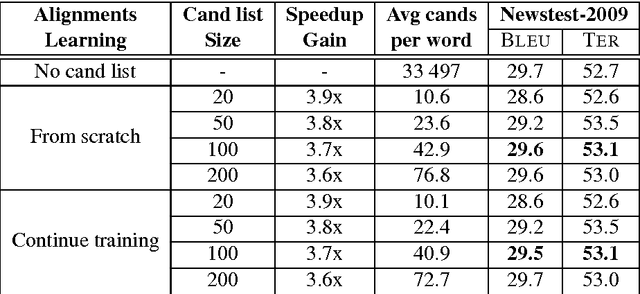
Neural Machine Translation (NMT) models usually use large target vocabulary sizes to capture most of the words in the target language. The vocabulary size is a big factor when decoding new sentences as the final softmax layer normalizes over all possible target words. To address this problem, it is widely common to restrict the target vocabulary with candidate lists based on the source sentence. Usually, the candidate lists are a combination of external word-to-word aligner, phrase table entries or most frequent words. In this work, we propose a simple and yet novel approach to learn candidate lists directly from the attention layer during NMT training. The candidate lists are highly optimized for the current NMT model and do not need any external computation of the candidate pool. We show significant decoding speedup compared with using the entire vocabulary, without losing any translation quality for two language pairs.
Fast Domain Adaptation for Neural Machine Translation
Dec 20, 2016
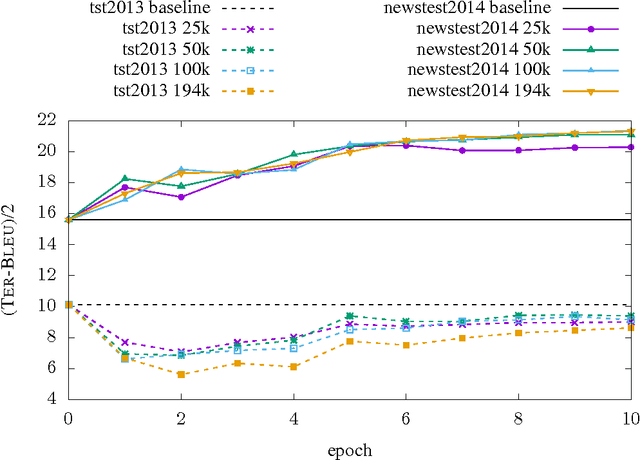
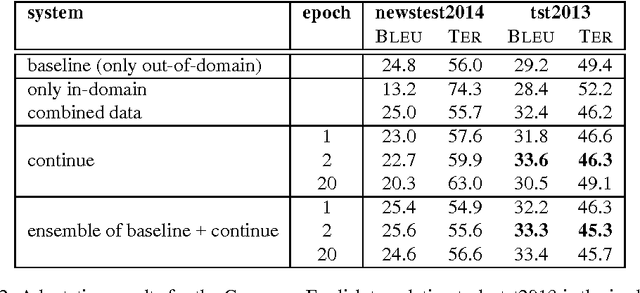
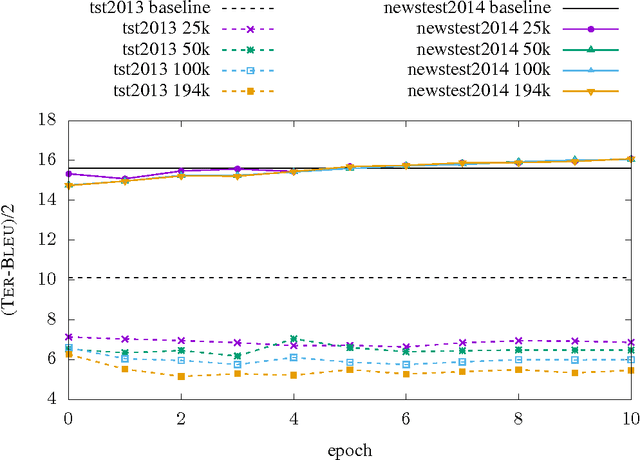
Neural Machine Translation (NMT) is a new approach for automatic translation of text from one human language into another. The basic concept in NMT is to train a large Neural Network that maximizes the translation performance on a given parallel corpus. NMT is gaining popularity in the research community because it outperformed traditional SMT approaches in several translation tasks at WMT and other evaluation tasks/benchmarks at least for some language pairs. However, many of the enhancements in SMT over the years have not been incorporated into the NMT framework. In this paper, we focus on one such enhancement namely domain adaptation. We propose an approach for adapting a NMT system to a new domain. The main idea behind domain adaptation is that the availability of large out-of-domain training data and a small in-domain training data. We report significant gains with our proposed method in both automatic metrics and a human subjective evaluation metric on two language pairs. With our adaptation method, we show large improvement on the new domain while the performance of our general domain only degrades slightly. In addition, our approach is fast enough to adapt an already trained system to a new domain within few hours without the need to retrain the NMT model on the combined data which usually takes several days/weeks depending on the volume of the data.
Temporal Attention Model for Neural Machine Translation
Aug 09, 2016
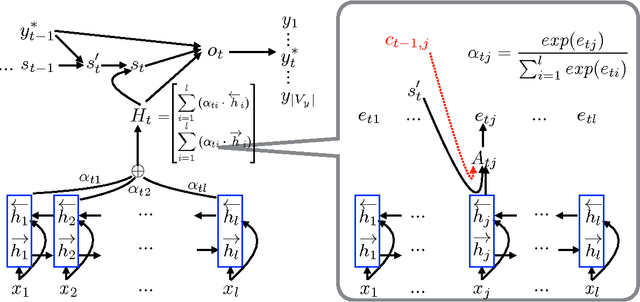
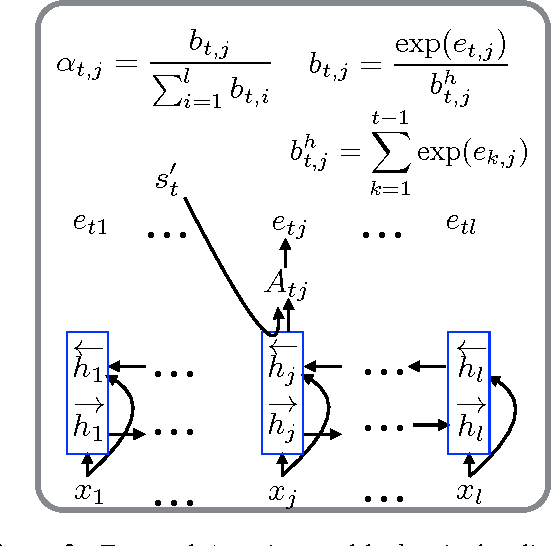
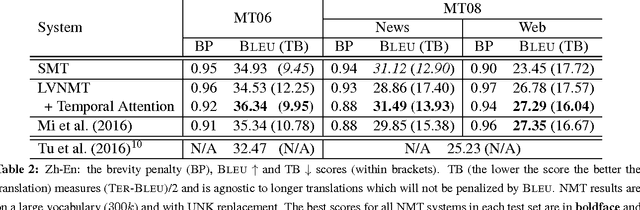
Attention-based Neural Machine Translation (NMT) models suffer from attention deficiency issues as has been observed in recent research. We propose a novel mechanism to address some of these limitations and improve the NMT attention. Specifically, our approach memorizes the alignments temporally (within each sentence) and modulates the attention with the accumulated temporal memory, as the decoder generates the candidate translation. We compare our approach against the baseline NMT model and two other related approaches that address this issue either explicitly or implicitly. Large-scale experiments on two language pairs show that our approach achieves better and robust gains over the baseline and related NMT approaches. Our model further outperforms strong SMT baselines in some settings even without using ensembles.
Zero-Resource Translation with Multi-Lingual Neural Machine Translation
Jun 13, 2016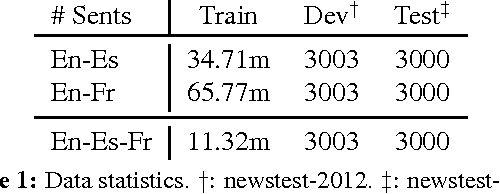
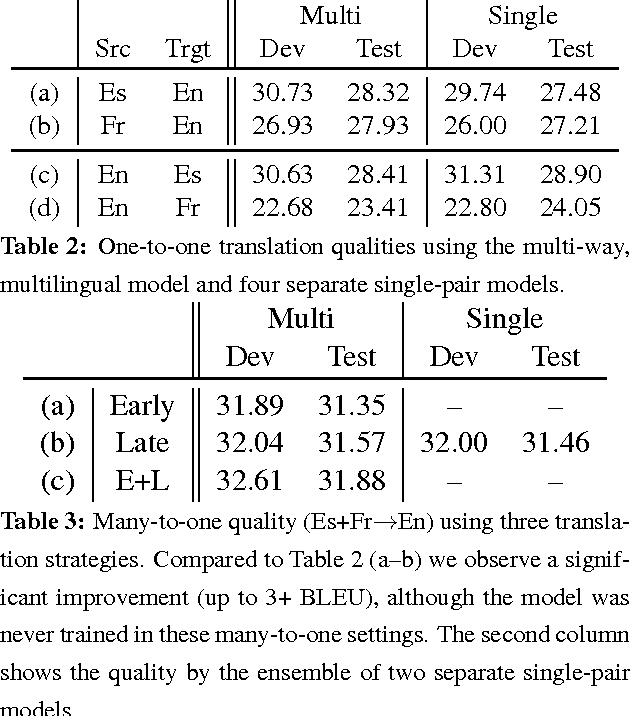
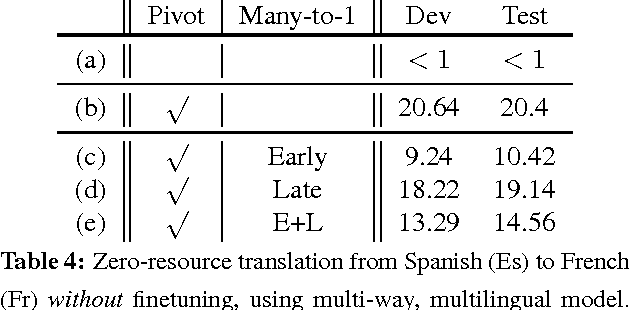
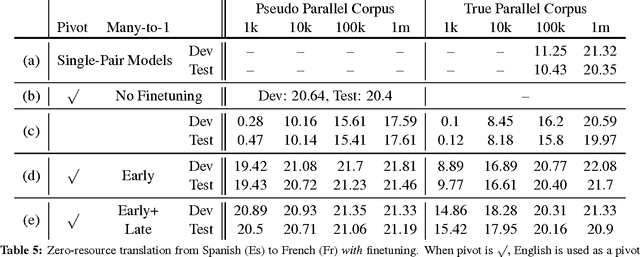
In this paper, we propose a novel finetuning algorithm for the recently introduced multi-way, mulitlingual neural machine translate that enables zero-resource machine translation. When used together with novel many-to-one translation strategies, we empirically show that this finetuning algorithm allows the multi-way, multilingual model to translate a zero-resource language pair (1) as well as a single-pair neural translation model trained with up to 1M direct parallel sentences of the same language pair and (2) better than pivot-based translation strategy, while keeping only one additional copy of attention-related parameters.