 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitation of characterizing implicit regularization by data-independent functions
Jan 28, 2022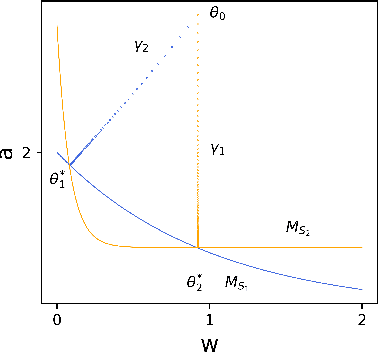
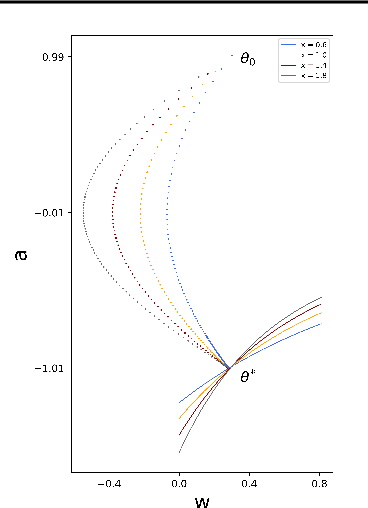
In recent years, understanding the implicit regularization of neural networks (NNs) has become a central task of deep learning theory. However, implicit regularization is in itself not completely defined and well understood. In this work, we make an attempt to mathematically define and study the implicit regularization. Importantly, we explore the limitation of a common approach of characterizing the implicit regularization by data-independent functions. We propose two dynamical mechanisms, i.e., Two-point and One-point Overlapping mechanisms, based on which we provide two recipes for producing classes of one-hidden-neuron NNs that provably cannot be fully characterized by a type of or all data-independent functions. Our results signify the profound data-dependency of implicit regularization in general, inspiring us to study in detail the data-dependency of NN implicit regularization in the future.
Overview frequency principle/spectral bias in deep learning
Jan 19, 2022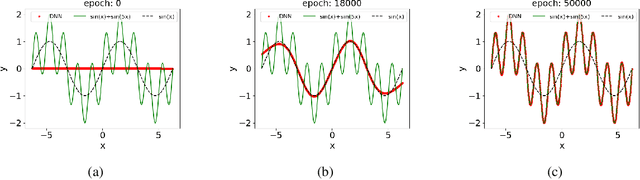
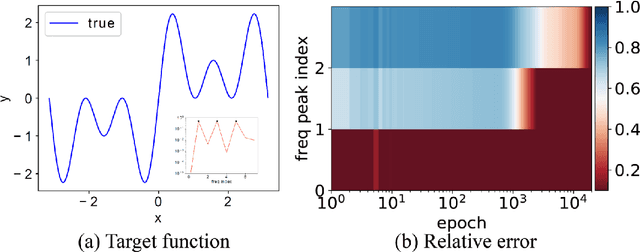


Understanding deep learning is increasingly emergent as it penetrates more and more into industry and science. In recent years, a research line from Fourier analysis sheds lights into this magical "black box" by showing a Frequency Principle (F-Principle or spectral bias) of the training behavior of deep neural networks (DNNs) -- DNNs often fit functions from low to high frequency during the training. The F-Principle is first demonstrated by one-dimensional synthetic data followed by the verification in high-dimensional real datasets. A series of works subsequently enhance the validity of the F-Principle. This low-frequency implicit bias reveals the strength of neural network in learning low-frequency functions as well as its deficiency in learning high-frequency functions. Such understanding inspires the design of DNN-based algorithms in practical problems, explains experimental phenomena emerging in various scenarios, and further advances the study of deep learning from the frequency perspective. Although incomplete, we provide an overview of F-Principle and propose some open problems for future research.
A multi-scale sampling method for accurate and robust deep neural network to predict combustion chemical kinetics
Jan 09, 2022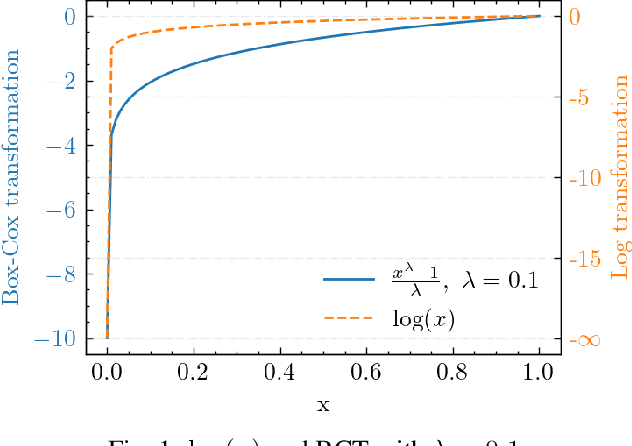
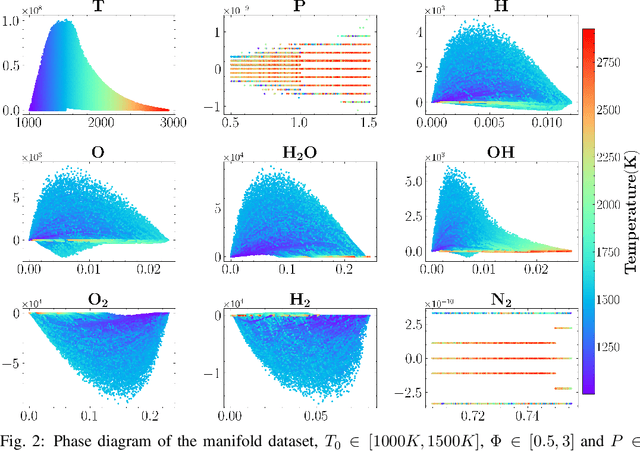
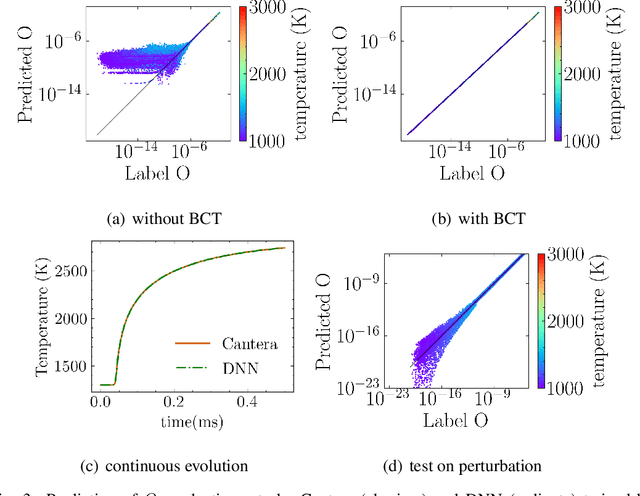
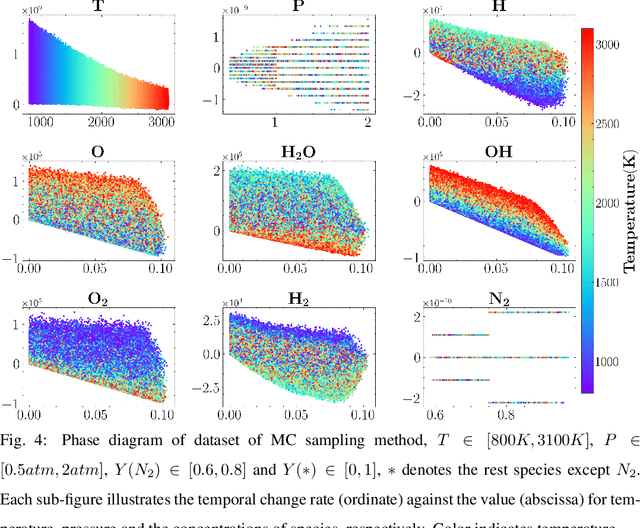
Machine learning has long been considered as a black box for predicting combustion chemical kinetics due to the extremely large number of parameters and the lack of evaluation standards and reproducibility. The current work aims to understand two basic questions regarding the deep neural network (DNN) method: what data the DNN needs and how general the DNN method can be. Sampling and preprocessing determine the DNN training dataset, further affect DNN prediction ability. The current work proposes using Box-Cox transformation (BCT) to preprocess the combustion data. In addition, this work compares different sampling methods with or without preprocessing, including the Monte Carlo method, manifold sampling, generative neural network method (cycle-GAN), and newly-proposed multi-scale sampling. Our results reveal that the DNN trained by the manifold data can capture the chemical kinetics in limited configurations but cannot remain robust toward perturbation, which is inevitable for the DNN coupled with the flow field. The Monte Carlo and cycle-GAN samplings can cover a wider phase space but fail to capture small-scale intermediate species, producing poor prediction results. A three-hidden-layer DNN, based on the multi-scale method without specific flame simulation data, allows predicting chemical kinetics in various scenarios and being stable during the temporal evolutions. This single DNN is readily implemented with several CFD codes and validated in various combustors, including (1). zero-dimensional autoignition, (2). one-dimensional freely propagating flame, (3). two-dimensional jet flame with triple-flame structure, and (4). three-dimensional turbulent lifted flames. The results demonstrate the satisfying accuracy and generalization ability of the pre-trained DNN. The Fortran and Python versions of DNN and example code are attached in the supplementary for reproducibility.
A deep learning-based model reduction method for simplifying chemical kinetics
Jan 07, 2022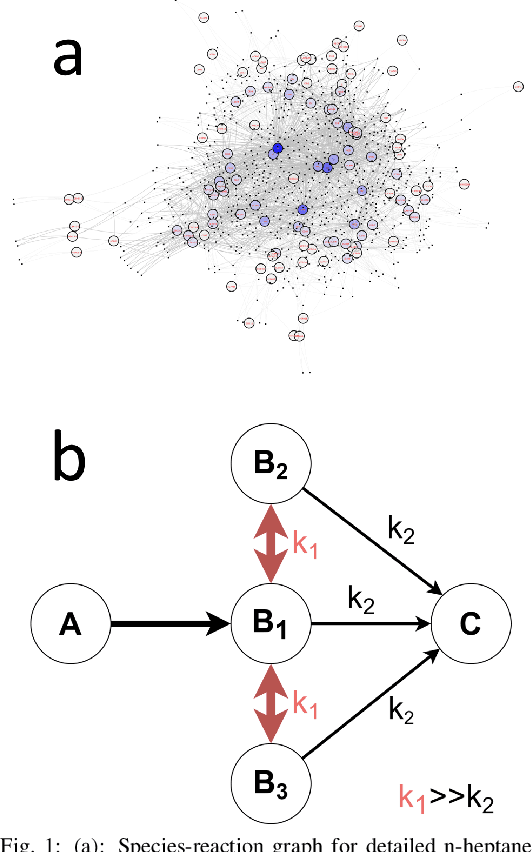
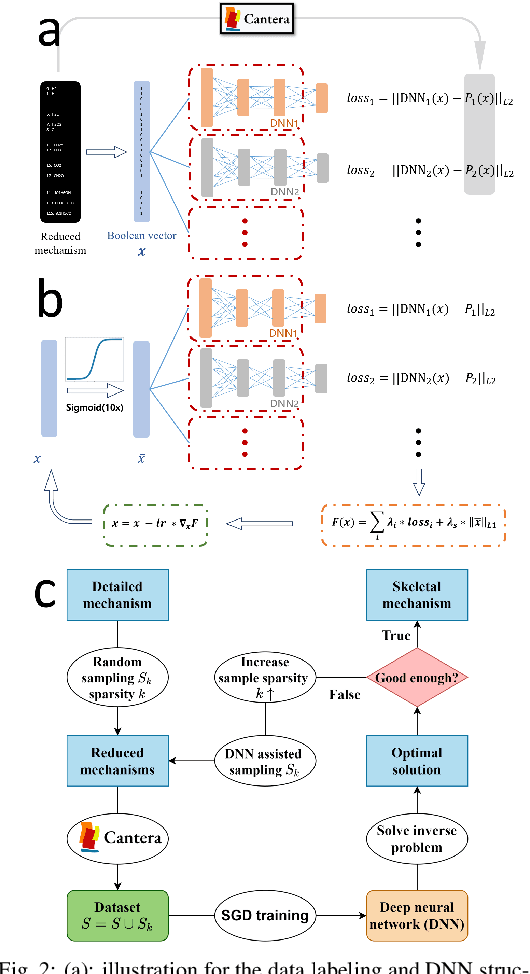
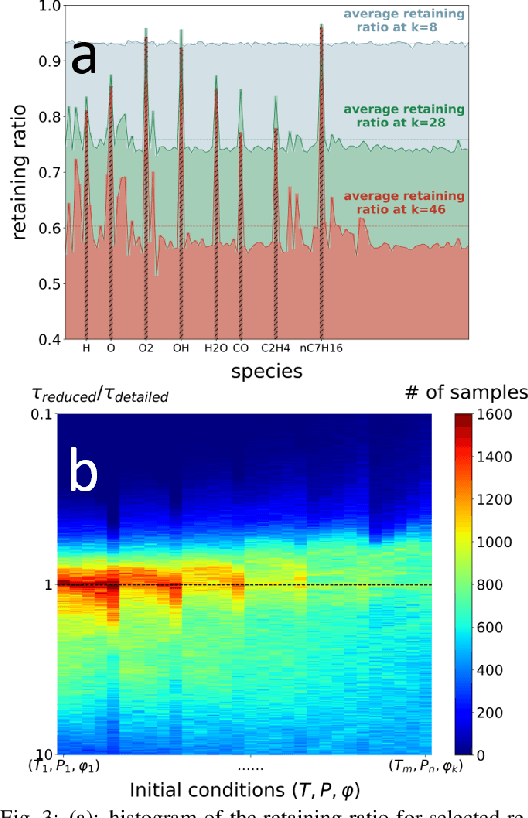
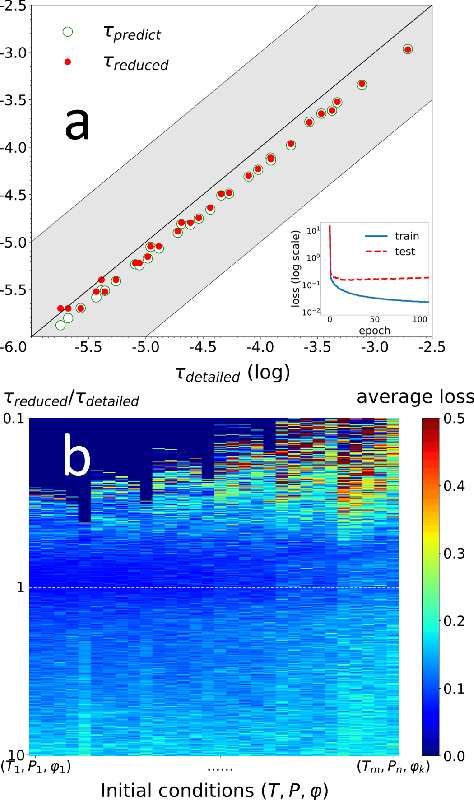
A deep learning-based model reduction (DeePMR) method for simplifying chemical kinetics is proposed and validated using high-temperature auto-ignitions, perfectly stirred reactors (PSR), and one-dimensional freely propagating flames of n-heptane/air mixtures. The mechanism reduction is modeled as an optimization problem on Boolean space, where a Boolean vector, each entry corresponding to a species, represents a reduced mechanism. The optimization goal is to minimize the reduced mechanism size given the error tolerance of a group of pre-selected benchmark quantities. The key idea of the DeePMR is to employ a deep neural network (DNN) to formulate the objective function in the optimization problem. In order to explore high dimensional Boolean space efficiently, an iterative DNN-assisted data sampling and DNN training procedure are implemented. The results show that DNN-assistance improves sampling efficiency significantly, selecting only $10^5$ samples out of $10^{34}$ possible samples for DNN to achieve sufficient accuracy. The results demonstrate the capability of the DNN to recognize key species and reasonably predict reduced mechanism performance. The well-trained DNN guarantees the optimal reduced mechanism by solving an inverse optimization problem. By comparing ignition delay times, laminar flame speeds, temperatures in PSRs, the resulting skeletal mechanism has fewer species (45 species) but the same level of accuracy as the skeletal mechanism (56 species) obtained by the Path Flux Analysis (PFA) method. In addition, the skeletal mechanism can be further reduced to 28 species if only considering atmospheric, near-stoichiometric conditions (equivalence ratio between 0.6 and 1.2). The DeePMR provides an innovative way to perform model reduction and demonstrates the great potential of data-driven methods in the combustion area.
Embedding Principle: a hierarchical structure of loss landscape of deep neural networks
Nov 30, 2021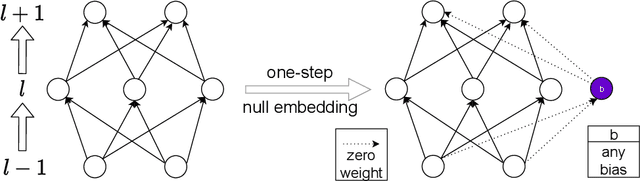
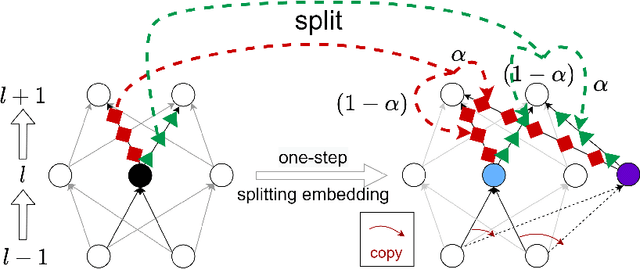
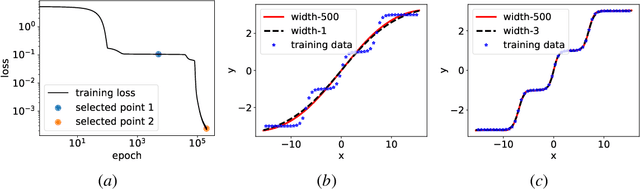
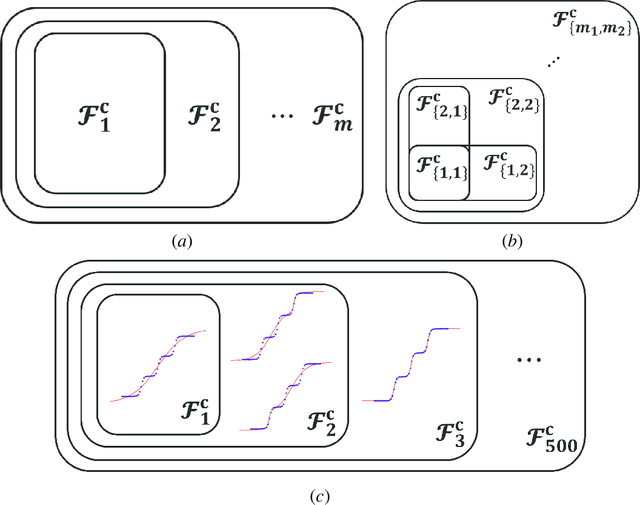
We prove a general Embedding Principle of loss landscape of deep neural networks (NNs) that unravels a hierarchical structure of the loss landscape of NNs, i.e., loss landscape of an NN contains all critical points of all the narrower NNs. This result is obtained by constructing a class of critical embeddings which map any critical point of a narrower NN to a critical point of the target NN with the same output function. By discovering a wide class of general compatible critical embeddings, we provide a gross estimate of the dimension of critical submanifolds embedded from critical points of narrower NNs. We further prove an irreversiblility property of any critical embedding that the number of negative/zero/positive eigenvalues of the Hessian matrix of a critical point may increase but never decrease as an NN becomes wider through the embedding. Using a special realization of general compatible critical embedding, we prove a stringent necessary condition for being a "truly-bad" critical point that never becomes a strict-saddle point through any critical embedding. This result implies the commonplace of strict-saddle points in wide NNs, which may be an important reason underlying the easy optimization of wide NNs widely observed in practice.
Data-informed Deep Optimization
Jul 17, 2021
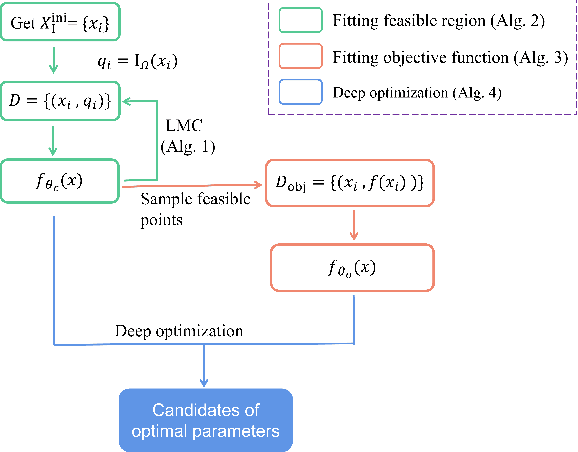
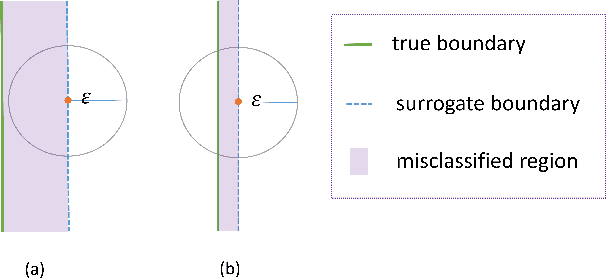
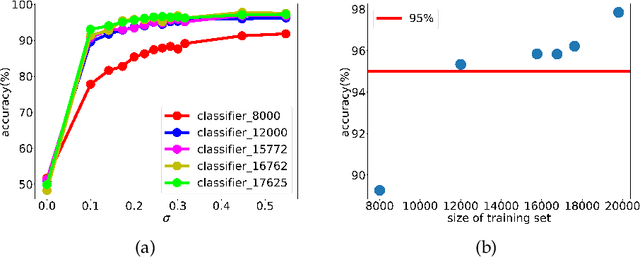
Complex design problems are common in the scientific and industrial fields. In practice, objective functions or constraints of these problems often do not have explicit formulas, and can be estimated only at a set of sampling points through experiments or simulations. Such optimization problems are especially challenging when design parameters are high-dimensional due to the curse of dimensionality. In this work, we propose a data-informed deep optimization (DiDo) approach as follows: first, we use a deep neural network (DNN) classifier to learn the feasible region; second, we sample feasible points based on the DNN classifier for fitting of the objective function; finally, we find optimal points of the DNN-surrogate optimization problem by gradient descent. To demonstrate the effectiveness of our DiDo approach, we consider a practical design case in industry, in which our approach yields good solutions using limited size of training data. We further use a 100-dimension toy example to show the effectiveness of our model for higher dimensional problems. Our results indicate that the DiDo approach empowered by DNN is flexible and promising for solving general high-dimensional design problems in practice.
MOD-Net: A Machine Learning Approach via Model-Operator-Data Network for Solving PDEs
Jul 08, 2021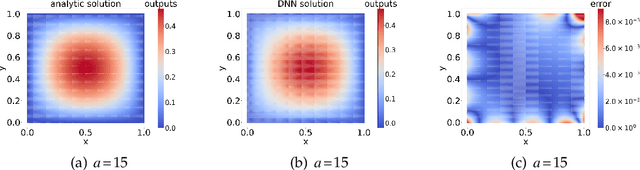
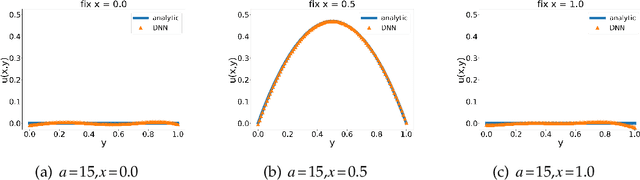
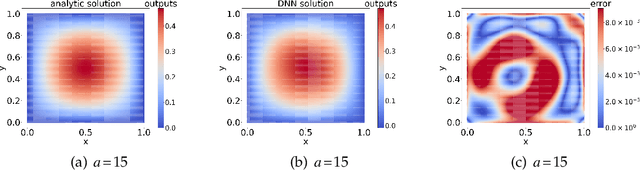
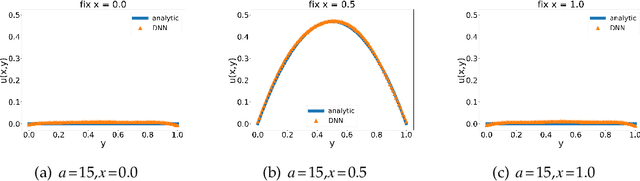
In this paper, we propose a model-operator-data network (MOD-Net) for solving PDEs. A MOD-Net is driven by a model to solve PDEs based on operator representation with regularization from data. In this work, we use a deep neural network to parameterize the Green's function. The empirical risk consists of the mean square of the governing equation, boundary conditions, and a few labels, which are numerically computed by traditional schemes on coarse grid points with cheap computation cost. With only the labeled dataset or only the model constraints, it is insufficient to accurately train a MOD-Net for complicate problems. Intuitively, the labeled dataset works as a regularization in addition to the model constraints. The MOD-Net is much efficient than original neural operator because the MOD-Net also uses the information of governing equation and the boundary conditions of the PDE rather than purely the expensive labels. Since the MOD-Net learns the Green's function of a PDE, it solves a type of PDEs but not a specific case. We numerically show MOD-Net is very efficient in solving Poisson equation and one-dimensional Boltzmann equation. For non-linear PDEs, where the concept of the Green's function does not apply, the non-linear MOD-Net can be similarly used as an ansatz for solving non-linear PDEs.
An Upper Limit of Decaying Rate with Respect to Frequency in Deep Neural Network
Jun 03, 2021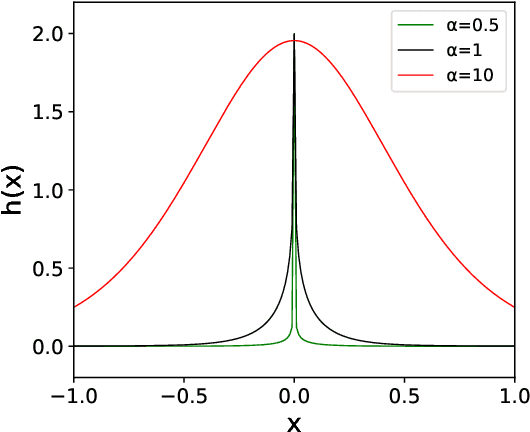
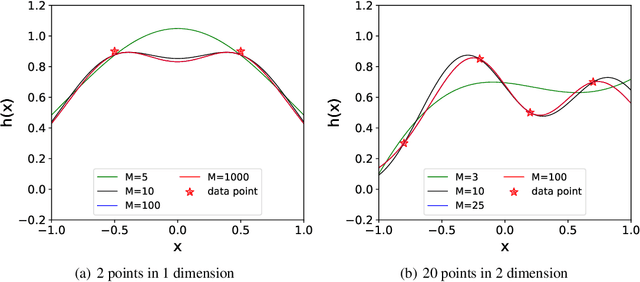
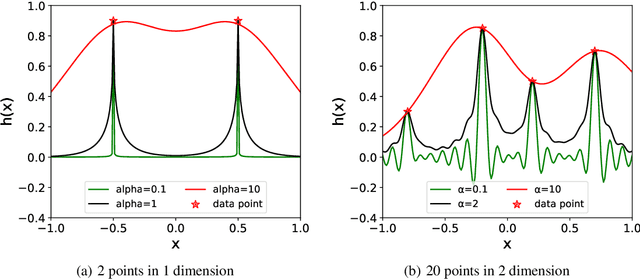
Deep neural network (DNN) usually learns the target function from low to high frequency, which is called frequency principle or spectral bias. This frequency principle sheds light on a high-frequency curse of DNNs -- difficult to learn high-frequency information. Inspired by the frequency principle, a series of works are devoted to develop algorithms for overcoming the high-frequency curse. A natural question arises: what is the upper limit of the decaying rate w.r.t. frequency when one trains a DNN? In this work, our theory, confirmed by numerical experiments, suggests that there is a critical decaying rate w.r.t. frequency in DNN training. Below the upper limit of the decaying rate, the DNN interpolates the training data by a function with a certain regularity. However, above the upper limit, the DNN interpolates the training data by a trivial function, i.e., a function is only non-zero at training data points. Our results indicate a better way to overcome the high-frequency curse is to design a proper pre-condition approach to shift high-frequency information to low-frequency one, which coincides with several previous developed algorithms for fast learning high-frequency information. More importantly, this work rigorously proves that the high-frequency curse is an intrinsic difficulty of DNNs.
Embedding Principle of Loss Landscape of Deep Neural Networks
May 30, 2021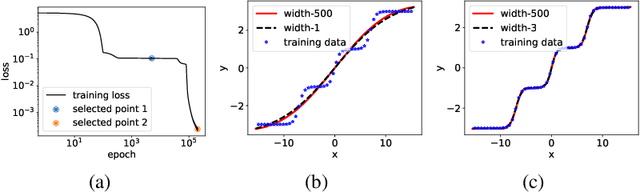
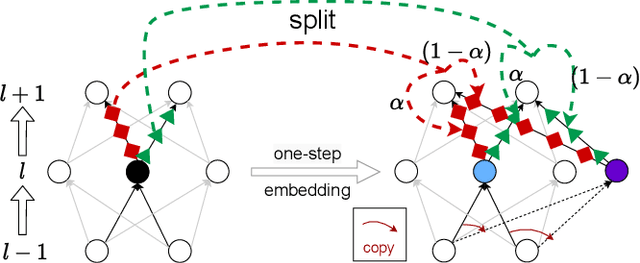
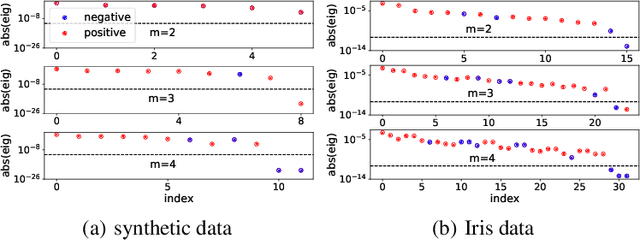
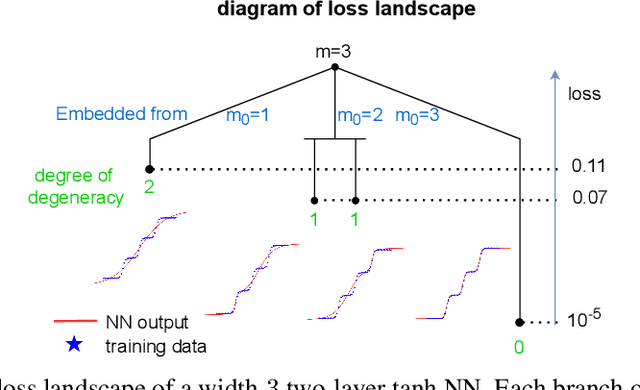
Understanding the structure of loss landscape of deep neural networks (DNNs)is obviously important. In this work, we prove an embedding principle that the loss landscape of a DNN "contains" all the critical points of all the narrower DNNs. More precisely, we propose a critical embedding such that any critical point, e.g., local or global minima, of a narrower DNN can be embedded to a critical point/hyperplane of the target DNN with higher degeneracy and preserving the DNN output function. The embedding structure of critical points is independent of loss function and training data, showing a stark difference from other nonconvex problems such as protein-folding. Empirically, we find that a wide DNN is often attracted by highly-degenerate critical points that are embedded from narrow DNNs. The embedding principle provides an explanation for the general easy optimization of wide DNNs and unravels a potential implicit low-complexity regularization during the training. Overall, our work provides a skeleton for the study of loss landscape of DNNs and its implication, by which a more exact and comprehensive understanding can be anticipated in the near
Towards Understanding the Condensation of Two-layer Neural Networks at Initial Training
May 29, 2021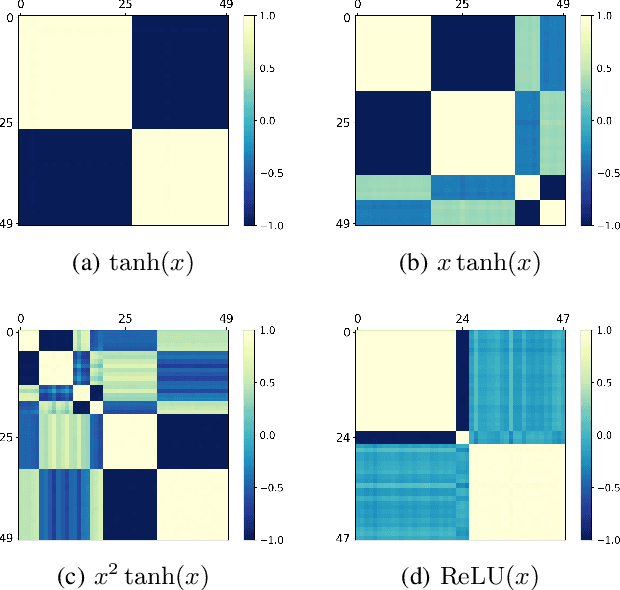
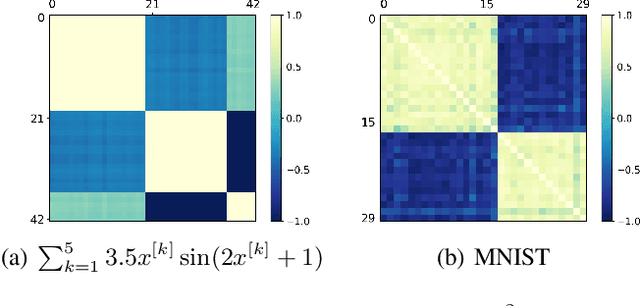
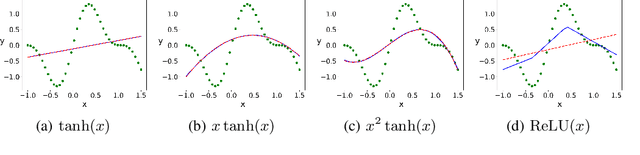
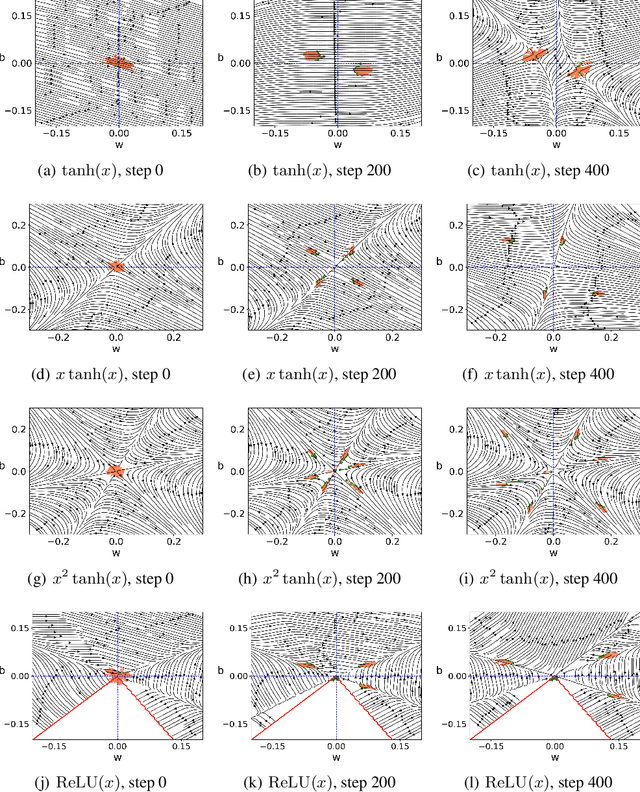
It is important to study what implicit regularization is imposed on the loss function during the training that leads over-parameterized neural networks (NNs) to good performance on real dataset. Empirically, existing works have shown that weights of NNs condense on isolated orientations with small initialization. The condensation implies that the NN learns features from the training data and is effectively a much smaller network. In this work, we show that the singularity of the activation function at original point is a key factor to understanding the condensation at initial training stage. Our experiments suggest that the maximal number of condensed orientations is twice of the singularity order. Our theoretical analysis confirms experiments for two cases, one is for the first-order singularity activation function and the other is for the one-dimensional input. This work takes a step towards understanding how small initialization implicitly leads NNs to condensation at initial training, which is crucial to understand the training and the learning of deep NNs.