 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Out-of-Distribution Detection to Hallucination Detection: A Geometric View
Feb 06, 2026Detecting hallucinations in large language models is a critical open problem with significant implications for safety and reliability. While existing hallucination detection methods achieve strong performance in question-answering tasks, they remain less effective on tasks requiring reasoning. In this work, we revisit hallucination detection through the lens of out-of-distribution (OOD) detection, a well-studied problem in areas like computer vision. Treating next-token prediction in language models as a classification task allows us to apply OOD techniques, provided appropriate modifications are made to account for the structural differences in large language models. We show that OOD-based approaches yield training-free, single-sample-based detectors, achieving strong accuracy in hallucination detection for reasoning tasks. Overall, our work suggests that reframing hallucination detection as OOD detection provides a promising and scalable pathway toward language model safety.
MetaboNet: The Largest Publicly Available Consolidated Dataset for Type 1 Diabetes Management
Jan 16, 2026Progress in Type 1 Diabetes (T1D) algorithm development is limited by the fragmentation and lack of standardization across existing T1D management datasets. Current datasets differ substantially in structure and are time-consuming to access and process, which impedes data integration and reduces the comparability and generalizability of algorithmic developments. This work aims to establish a unified and accessible data resource for T1D algorithm development. Multiple publicly available T1D datasets were consolidated into a unified resource, termed the MetaboNet dataset. Inclusion required the availability of both continuous glucose monitoring (CGM) data and corresponding insulin pump dosing records. Additionally, auxiliary information such as reported carbohydrate intake and physical activity was retained when present. The MetaboNet dataset comprises 3135 subjects and 1228 patient-years of overlapping CGM and insulin data, making it substantially larger than existing standalone benchmark datasets. The resource is distributed as a fully public subset available for immediate download at https://metabo-net.org/ , and with a Data Use Agreement (DUA)-restricted subset accessible through their respective application processes. For the datasets in the latter subset, processing pipelines are provided to automatically convert the data into the standardized MetaboNet format. A consolidated public dataset for T1D research is presented, and the access pathways for both its unrestricted and DUA-governed components are described. The resulting dataset covers a broad range of glycemic profiles and demographics and thus can yield more generalizable algorithmic performance than individual datasets.
Zero-Training Task-Specific Model Synthesis for Few-Shot Medical Image Classification
Nov 18, 2025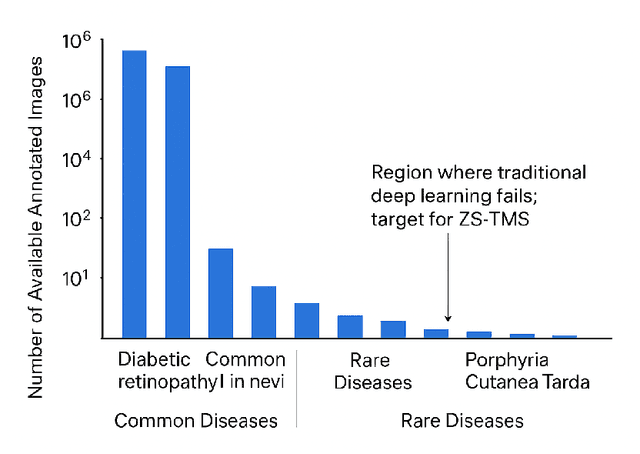
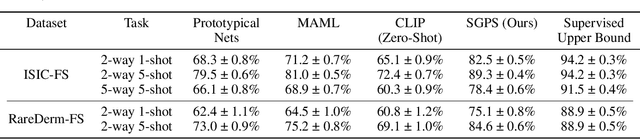
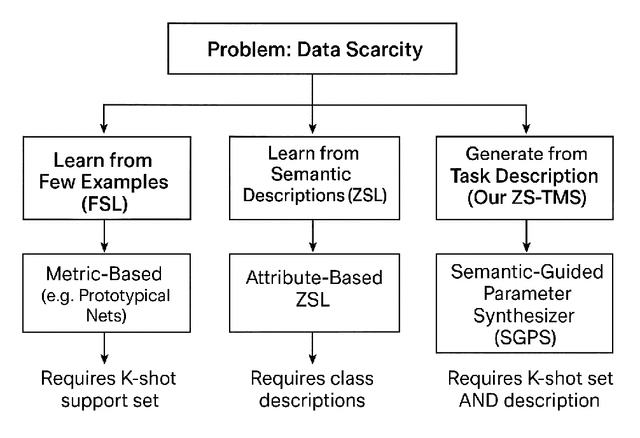

Deep learning models have achieved remarkable success in medical image analysis but are fundamentally constrained by the requirement for large-scale, meticulously annotated datasets. This dependency on "big data" is a critical bottleneck in the medical domain, where patient data is inherently difficult to acquire and expert annotation is expensive, particularly for rare diseases where samples are scarce by definition. To overcome this fundamental challenge, we propose a novel paradigm: Zero-Training Task-Specific Model Synthesis (ZS-TMS). Instead of adapting a pre-existing model or training a new one, our approach leverages a large-scale, pre-trained generative engine to directly synthesize the entire set of parameters for a task-specific classifier. Our framework, the Semantic-Guided Parameter Synthesizer (SGPS), takes as input minimal, multi-modal task information as little as a single example image (1-shot) and a corresponding clinical text description to directly synthesize the entire set of parameters for a task-specific classifier. The generative engine interprets these inputs to generate the weights for a lightweight, efficient classifier (e.g., an EfficientNet-V2), which can be deployed for inference immediately without any task-specific training or fine-tuning. We conduct extensive evaluations on challenging few-shot classification benchmarks derived from the ISIC 2018 skin lesion dataset and a custom rare disease dataset. Our results demonstrate that SGPS establishes a new state-of-the-art, significantly outperforming advanced few-shot and zero-shot learning methods, especially in the ultra-low data regimes of 1-shot and 5-shot classification. This work paves the way for the rapid development and deployment of AI-powered diagnostic tools, particularly for the long tail of rare diseases where data is critically limited.
Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
Oct 06, 2025



Recent advancements in large language models (LLMs) have substantially improved automated code generation. While function-level and file-level generation have achieved promising results, real-world software development typically requires reasoning across entire repositories. This gives rise to the challenging task of Repository-Level Code Generation (RLCG), where models must capture long-range dependencies, ensure global semantic consistency, and generate coherent code spanning multiple files or modules. To address these challenges, Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm that integrates external retrieval mechanisms with LLMs, enhancing context-awareness and scalability. In this survey, we provide a comprehensive review of research on Retrieval-Augmented Code Generation (RACG), with an emphasis on repository-level approaches. We categorize existing work along several dimensions, including generation strategies, retrieval modalities, model architectures, training paradigms, and evaluation protocols. Furthermore, we summarize widely used datasets and benchmarks, analyze current limitations, and outline key challenges and opportunities for future research. Our goal is to establish a unified analytical framework for understanding this rapidly evolving field and to inspire continued progress in AI-powered software engineering.
DIY-MKG: An LLM-Based Polyglot Language Learning System
Jul 02, 2025Existing language learning tools, even those powered by Large Language Models (LLMs), often lack support for polyglot learners to build linguistic connections across vocabularies in multiple languages, provide limited customization for individual learning paces or needs, and suffer from detrimental cognitive offloading. To address these limitations, we design Do-It-Yourself Multilingual Knowledge Graph (DIY-MKG), an open-source system that supports polyglot language learning. DIY-MKG allows the user to build personalized vocabulary knowledge graphs, which are constructed by selective expansion with related words suggested by an LLM. The system further enhances learning through rich annotation capabilities and an adaptive review module that leverages LLMs for dynamic, personalized quiz generation. In addition, DIY-MKG allows users to flag incorrect quiz questions, simultaneously increasing user engagement and providing a feedback loop for prompt refinement. Our evaluation of LLM-based components in DIY-MKG shows that vocabulary expansion is reliable and fair across multiple languages, and that the generated quizzes are highly accurate, validating the robustness of DIY-MKG.
Bridging Distribution Shift and AI Safety: Conceptual and Methodological Synergies
May 28, 2025This paper bridges distribution shift and AI safety through a comprehensive analysis of their conceptual and methodological synergies. While prior discussions often focus on narrow cases or informal analogies, we establish two types connections between specific causes of distribution shift and fine-grained AI safety issues: (1) methods addressing a specific shift type can help achieve corresponding safety goals, or (2) certain shifts and safety issues can be formally reduced to each other, enabling mutual adaptation of their methods. Our findings provide a unified perspective that encourages fundamental integration between distribution shift and AI safety research.
SPICE: A Synergistic, Precise, Iterative, and Customizable Image Editing Workflow
Apr 13, 2025Recent prompt-based image editing models have demonstrated impressive prompt-following capability at structural editing tasks. However, existing models still fail to perform local edits, follow detailed editing prompts, or maintain global image quality beyond a single editing step. To address these challenges, we introduce SPICE, a training-free workflow that accepts arbitrary resolutions and aspect ratios, accurately follows user requirements, and improves image quality consistently during more than 100 editing steps. By synergizing the strengths of a base diffusion model and a Canny edge ControlNet model, SPICE robustly handles free-form editing instructions from the user. SPICE outperforms state-of-the-art baselines on a challenging realistic image-editing dataset consisting of semantic editing (object addition, removal, replacement, and background change), stylistic editing (texture changes), and structural editing (action change) tasks. Not only does SPICE achieve the highest quantitative performance according to standard evaluation metrics, but it is also consistently preferred by users over existing image-editing methods. We release the workflow implementation for popular diffusion model Web UIs to support further research and artistic exploration.
Improving Adversarial Transferability in MLLMs via Dynamic Vision-Language Alignment Attack
Feb 27, 2025



Multimodal Large Language Models (MLLMs), built upon LLMs, have recently gained attention for their capabilities in image recognition and understanding. However, while MLLMs are vulnerable to adversarial attacks, the transferability of these attacks across different models remains limited, especially under targeted attack setting. Existing methods primarily focus on vision-specific perturbations but struggle with the complex nature of vision-language modality alignment. In this work, we introduce the Dynamic Vision-Language Alignment (DynVLA) Attack, a novel approach that injects dynamic perturbations into the vision-language connector to enhance generalization across diverse vision-language alignment of different models. Our experimental results show that DynVLA significantly improves the transferability of adversarial examples across various MLLMs, including BLIP2, InstructBLIP, MiniGPT4, LLaVA, and closed-source models such as Gemini.
Mix from Failure: Confusion-Pairing Mixup for Long-Tailed Recognition
Nov 12, 2024



Long-tailed image recognition is a computer vision problem considering a real-world class distribution rather than an artificial uniform. Existing methods typically detour the problem by i) adjusting a loss function, ii) decoupling classifier learning, or iii) proposing a new multi-head architecture called experts. In this paper, we tackle the problem from a different perspective to augment a training dataset to enhance the sample diversity of minority classes. Specifically, our method, namely Confusion-Pairing Mixup (CP-Mix), estimates the confusion distribution of the model and handles the data deficiency problem by augmenting samples from confusion pairs in real-time. In this way, CP-Mix trains the model to mitigate its weakness and distinguish a pair of classes it frequently misclassifies. In addition, CP-Mix utilizes a novel mixup formulation to handle the bias in decision boundaries that originated from the imbalanced dataset. Extensive experiments demonstrate that CP-Mix outperforms existing methods for long-tailed image recognition and successfully relieves the confusion of the classifier.
Conflict-Aware Adversarial Training
Oct 21, 2024Adversarial training is the most effective method to obtain adversarial robustness for deep neural networks by directly involving adversarial samples in the training procedure. To obtain an accurate and robust model, the weighted-average method is applied to optimize standard loss and adversarial loss simultaneously. In this paper, we argue that the weighted-average method does not provide the best tradeoff for the standard performance and adversarial robustness. We argue that the failure of the weighted-average method is due to the conflict between the gradients derived from standard and adversarial loss, and further demonstrate such a conflict increases with attack budget theoretically and practically. To alleviate this problem, we propose a new trade-off paradigm for adversarial training with a conflict-aware factor for the convex combination of standard and adversarial loss, named \textbf{Conflict-Aware Adversarial Training~(CA-AT)}. Comprehensive experimental results show that CA-AT consistently offers a superior trade-off between standard performance and adversarial robustness under the settings of adversarial training from scratch and parameter-efficient finetuning.