 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamo: Dynamic Skill-Tool Evolution for Vision-Language Agents
Jun 29, 2026Improving vision-language models (VLMs) on visual reasoning typically requires retraining or hand-designed prompts and tools. We present Dynamo, a training-free framework that adapts a frozen VLM without any weight updates. On a small labeled training subset, the agent inspects its own correct and incorrect attempts and evolves two complementary capabilities: reusable reasoning skills for cognitive bottlenecks, and executable visual tools for perceptual ones. Each generated tool is paired with a skill that specifies when to invoke it, and both capability types accumulate in a persistent library. Across four visual reasoning benchmarks and five VLM backbones, Dynamo improves direct inference on all 20 model--benchmark settings (avg. +5.6 acc). When the tool set is given in advance, the framework learns when to call each tool, and per-step tool choice improves on every tested backbone. Against task-specific RL (VTool-R1, DeepEyes), Dynamo closes 65--99% of the RL gap at a fraction of the compute, and combines additively with RL when available.
REKEY: Metadata-Grounded Visual-Key Regeneration for Contamination-Resilient VQA Evaluation
Jun 17, 2026Static visual question answering (VQA) benchmarks age quickly: Once the items leak into training corpora, scores can reflect memorization rather than genuine visual ability, thus obscuring real progress. Rebuilding high-quality benchmarks such as V*Bench requires substantial human annotation, yet each static release can quickly become another leaked artifact. We propose ReKey, a live benchmark protocol that randomly regenerates the answer-bearing local detail, or visual key, in real images at evaluation time. Using human-validated edit slots, ReKey samples fresh instances with new answers, construction-grounded labels, and controlled visual-search difficulty. On V*Bench, the ReKey regenerated benchmark reveals a sharp score jump across eight frontier vision-language models (VLMs): The original items score 9.5--18.8 percentage points higher than the regenerated variants. By making the visual key renewable, ReKey keeps evaluation fresh as models and training data evolve.
Fill the GAP: A Granular Alignment Paradigm for Visual Reasoning in Multimodal Large Language Models
May 12, 2026Visual latent reasoning lets a multimodal large language model (MLLM) create intermediate visual evidence as continuous tokens, avoiding external tools or image generators. However, existing methods usually follow an output-as-input latent paradigm and yield unstable gains. We identify evidence for a feature-space mismatch that can contribute to this instability: dominant visual-latent models build on pre-norm MLLMs and reuse decoder hidden states as predicted latent inputs, even though these states occupy a substantially different norm regime from the input embeddings the model was trained to consume~\citep{xie2025mhc,li2026siamesenorm,team2026attention}. This mismatch can make direct latent feedback unreliable. Motivated by this diagnosis, we propose \textbf{GAP}, a \textbf{G}ranular \textbf{A}lignment \textbf{P}aradigm for visual latent modeling. GAP aligns visual latent reasoning at three levels: feature-level alignment maps decoder outputs into input-compatible visual latents through a lightweight PCA-aligned latent head; context-level alignment grounds latent targets with inspectable auxiliary visual supervision; and capacity-guided alignment assigns latent supervision selectively to examples where the base MLLM struggles. On Qwen2.5-VL 7B, the resulting model achieves the best mean aggregate perception and reasoning performance among our supervised variants. Inference-time intervention probing further suggests that generated latents provide task-relevant visual signal beyond merely adding token slots.
Image-POSER: Reflective RL for Multi-Expert Image Generation and Editing
Nov 15, 2025
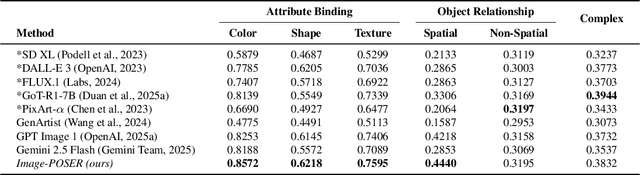
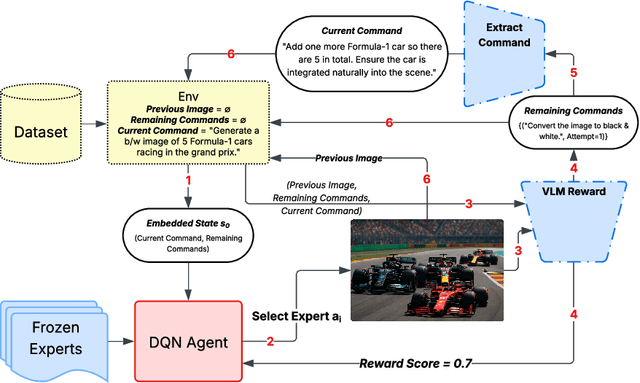
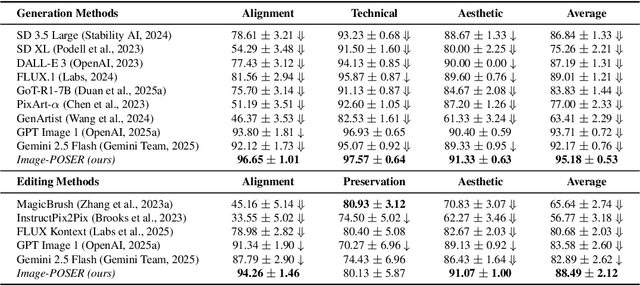
Recent advances in text-to-image generation have produced strong single-shot models, yet no individual system reliably executes the long, compositional prompts typical of creative workflows. We introduce Image-POSER, a reflective reinforcement learning framework that (i) orchestrates a diverse registry of pretrained text-to-image and image-to-image experts, (ii) handles long-form prompts end-to-end through dynamic task decomposition, and (iii) supervises alignment at each step via structured feedback from a vision-language model critic. By casting image synthesis and editing as a Markov Decision Process, we learn non-trivial expert pipelines that adaptively combine strengths across models. Experiments show that Image-POSER outperforms baselines, including frontier models, across industry-standard and custom benchmarks in alignment, fidelity, and aesthetics, and is consistently preferred in human evaluations. These results highlight that reinforcement learning can endow AI systems with the capacity to autonomously decompose, reorder, and combine visual models, moving towards general-purpose visual assistants.