 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Extraction of Entities and Relations with a Hierarchical Multi-task Tagging Model
Aug 23, 2019
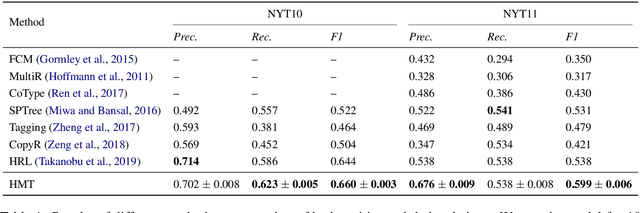
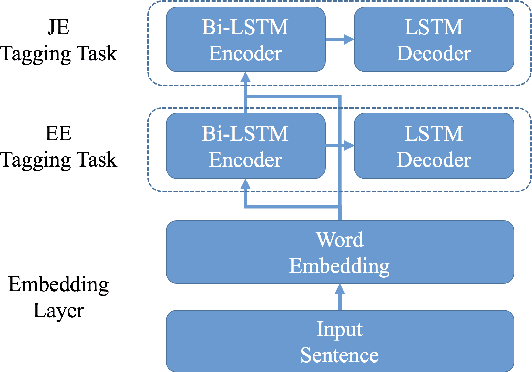

Entity extraction and relation extraction are two indispensable building blocks for knowledge graph construction. Recent works on entity and relation extraction have shown the superiority of solving the two problems in a joint manner, where entities and relations are extracted simultaneously to form relational triples in a knowledge graph. However, existing methods ignore the hierarchical semantic interdependency between entity extraction (EE) and joint extraction (JE), which leaves much to be desired in real applications. In this work, we propose a hierarchical multi-task tagging model, called HMT, which captures such interdependency and achieves better performance for joint extraction of entities and relations. Specifically, the EE task is organized at the bottom layer and JE task at the top layer in a hierarchical structure. Furthermore, the learned semantic representation at the lower level can be shared by the upper level via multi-task learning. Experimental results demonstrate the effectiveness of the proposed model for joint extraction in comparison with the state-of-the-art methods.
Path-Based Attention Neural Model for Fine-Grained Entity Typing
Jan 09, 2018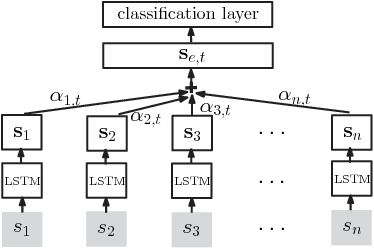
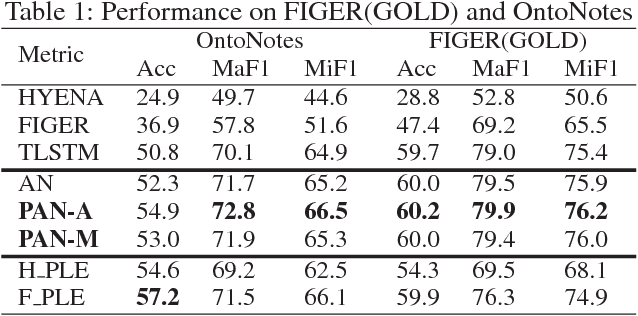
Fine-grained entity typing aims to assign entity mentions in the free text with types arranged in a hierarchical structure. Traditional distant supervision based methods employ a structured data source as a weak supervision and do not need hand-labeled data, but they neglect the label noise in the automatically labeled training corpus. Although recent studies use many features to prune wrong data ahead of training, they suffer from error propagation and bring much complexity. In this paper, we propose an end-to-end typing model, called the path-based attention neural model (PAN), to learn a noise- robust performance by leveraging the hierarchical structure of types. Experiments demonstrate its effectiveness.
Efficient Parallel Translating Embedding For Knowledge Graphs
Jan 09, 2018
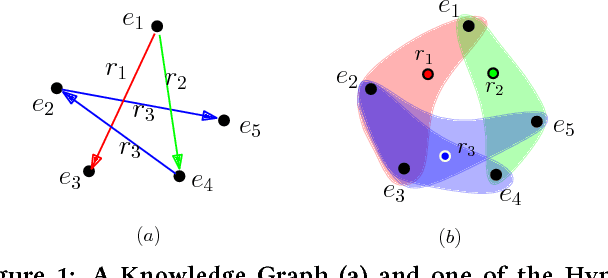
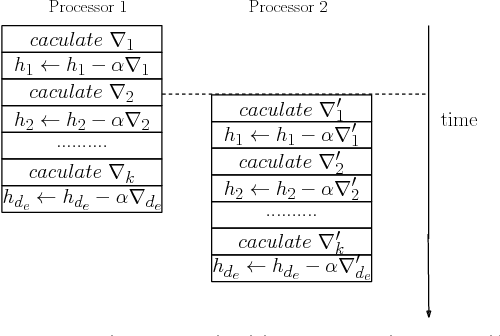

Knowledge graph embedding aims to embed entities and relations of knowledge graphs into low-dimensional vector spaces. Translating embedding methods regard relations as the translation from head entities to tail entities, which achieve the state-of-the-art results among knowledge graph embedding methods. However, a major limitation of these methods is the time consuming training process, which may take several days or even weeks for large knowledge graphs, and result in great difficulty in practical applications. In this paper, we propose an efficient parallel framework for translating embedding methods, called ParTrans-X, which enables the methods to be paralleled without locks by utilizing the distinguished structures of knowledge graphs. Experiments on two datasets with three typical translating embedding methods, i.e., TransE [3], TransH [17], and a more efficient variant TransE- AdaGrad [10] validate that ParTrans-X can speed up the training process by more than an order of magnitude.
Locally Adaptive Translation for Knowledge Graph Embedding
Dec 04, 2015
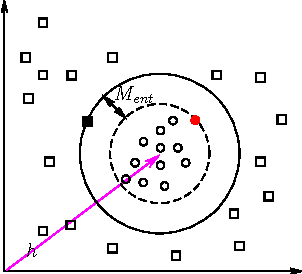
Knowledge graph embedding aims to represent entities and relations in a large-scale knowledge graph as elements in a continuous vector space. Existing methods, e.g., TransE and TransH, learn embedding representation by defining a global margin-based loss function over the data. However, the optimal loss function is determined during experiments whose parameters are examined among a closed set of candidates. Moreover, embeddings over two knowledge graphs with different entities and relations share the same set of candidate loss functions, ignoring the locality of both graphs. This leads to the limited performance of embedding related applications. In this paper, we propose a locally adaptive translation method for knowledge graph embedding, called TransA, to find the optimal loss function by adaptively determining its margin over different knowledge graphs. Experiments on two benchmark data sets demonstrate the superiority of the proposed method, as compared to the-state-of-the-art ones.