 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriLLMed: Interactive Visual Debugging of Medical Large Language Models with Knowledge Graphs
Apr 25, 2026Large language models (LLMs) show promise in medical diagnosis, but real-world deployment remains challenging due to high-stakes clinical decisions and imperfect reasoning reliability. As a result, careful inspection of model behavior is essential for assessing whether diagnostic reasoning is reliable and clinically grounded. However, debugging medical LLMs remains difficult. First, developers often lack sufficient medical domain expertise to interpret model errors in clinically meaningful terms. Second, models can fail across a large and diverse set of instances involving different input types, tasks, and reasoning steps, making it challenging for developers to prioritize which errors deserve focused inspection. Third, developers struggle to identify recurring error patterns across cases, as existing debugging practices are largely instance-centric and rely on manual inspection of isolated failures. To address these challenges, we present VeriLLMed, a visual analytics system that integrates external biomedical knowledge to audit and debug medical LLM diagnostic reasoning. VeriLLMed transforms model outputs into comparable reasoning paths, constructs knowledge graph-grounded reference paths, and identifies three recurring classes of diagnosis errors: relation errors, branch errors, and missing errors. Case studies and expert evaluation demonstrate that VeriLLMed helps developers identify clinically implausible reasoning and generate actionable insights that can inform the improvement of medical LLMs.
Navigating the Mirage: A Dual-Path Agentic Framework for Robust Misleading Chart Question Answering
Mar 30, 2026Despite the success of Vision-Language Models (VLMs), misleading charts remain a significant challenge due to their deceptive visual structures and distorted data representations. We present ChartCynics, an agentic dual-path framework designed to unmask visual deception via a "skeptical" reasoning paradigm. Unlike holistic models, ChartCynics decouples perception from verification: a Diagnostic Vision Path captures structural anomalies (e.g., inverted axes) through strategic ROI cropping, while an OCR-Driven Data Path ensures numerical grounding. To resolve cross-modal conflicts, we introduce an Agentic Summarizer optimized via a two-stage protocol: Oracle-Informed SFT for reasoning distillation and Deception-Aware GRPO for adversarial alignment. This pipeline effectively penalizes visual traps and enforces logical consistency. Evaluations on two benchmarks show that ChartCynics achieves 74.43% and 64.55% accuracy, providing an absolute performance boost of ~29% over the Qwen3-VL-8B backbone, outperforming state-of-the-art proprietary models. Our results demonstrate that specialized agentic workflows can grant smaller open-source models superior robustness, establishing a new foundation for trustworthy chart interpretation.
VBridge: Connecting the Dots Between Features, Explanations, and Data for Healthcare Models
Aug 04, 2021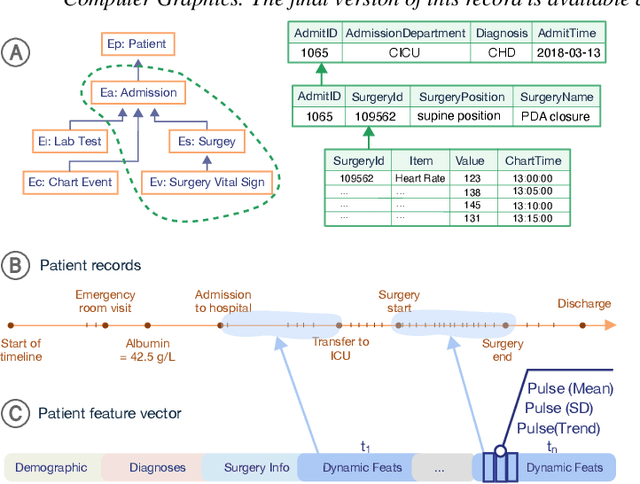
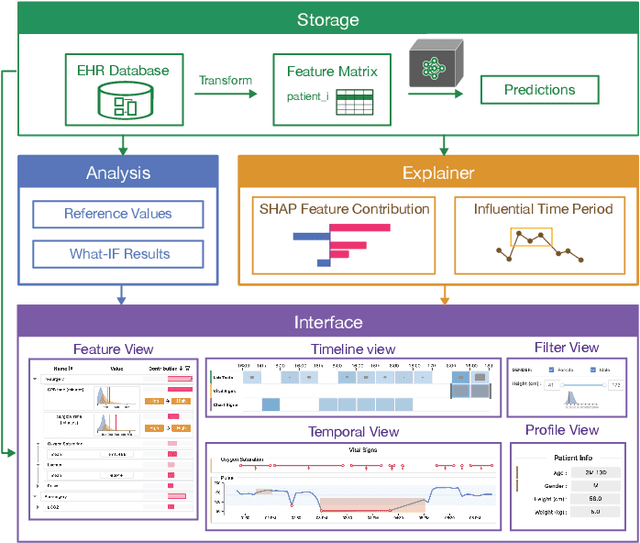
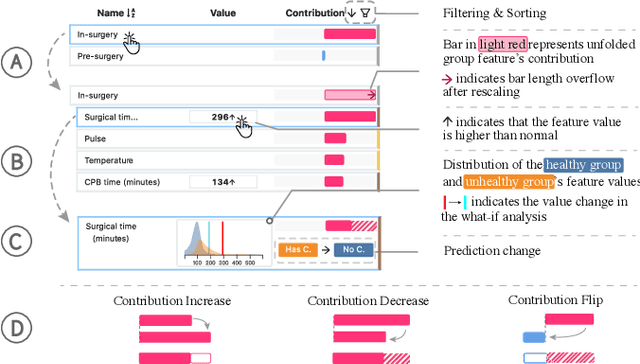
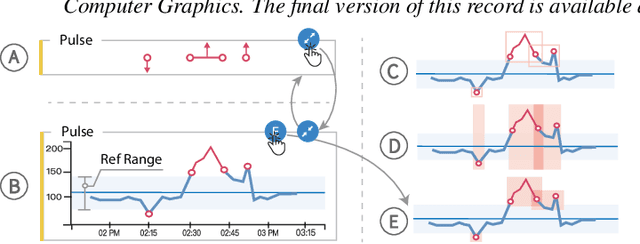
Machine learning (ML) is increasingly applied to Electronic Health Records (EHRs) to solve clinical prediction tasks. Although many ML models perform promisingly, issues with model transparency and interpretability limit their adoption in clinical practice. Directly using existing explainable ML techniques in clinical settings can be challenging. Through literature surveys and collaborations with six clinicians with an average of 17 years of clinical experience, we identified three key challenges, including clinicians' unfamiliarity with ML features, lack of contextual information, and the need for cohort-level evidence. Following an iterative design process, we further designed and developed VBridge, a visual analytics tool that seamlessly incorporates ML explanations into clinicians' decision-making workflow. The system includes a novel hierarchical display of contribution-based feature explanations and enriched interactions that connect the dots between ML features, explanations, and data. We demonstrated the effectiveness of VBridge through two case studies and expert interviews with four clinicians, showing that visually associating model explanations with patients' situational records can help clinicians better interpret and use model predictions when making clinician decisions. We further derived a list of design implications for developing future explainable ML tools to support clinical decision-making.