 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in High Dimension Always Amounts to Extrapolation
Oct 29, 2021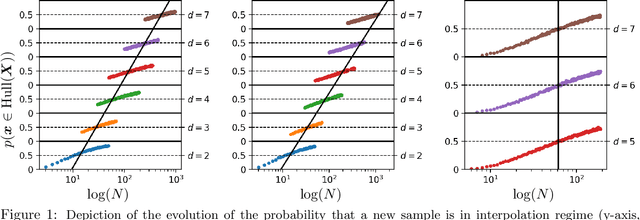

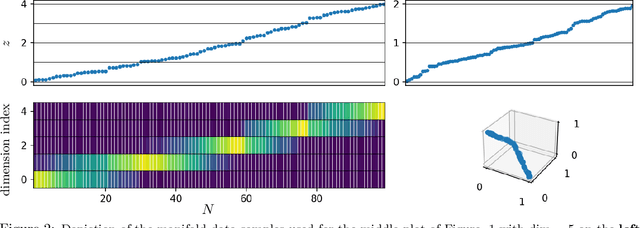
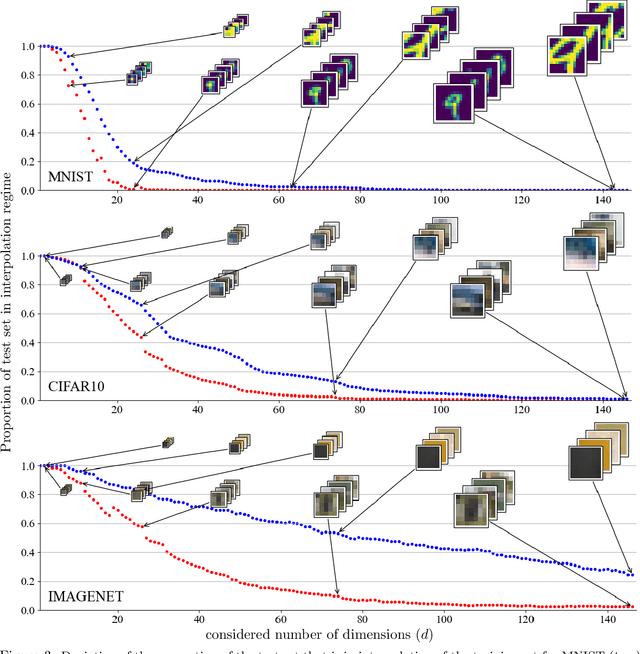
The notion of interpolation and extrapolation is fundamental in various fields from deep learning to function approximation. Interpolation occurs for a sample $x$ whenever this sample falls inside or on the boundary of the given dataset's convex hull. Extrapolation occurs when $x$ falls outside of that convex hull. One fundamental (mis)conception is that state-of-the-art algorithms work so well because of their ability to correctly interpolate training data. A second (mis)conception is that interpolation happens throughout tasks and datasets, in fact, many intuitions and theories rely on that assumption. We empirically and theoretically argue against those two points and demonstrate that on any high-dimensional ($>$100) dataset, interpolation almost surely never happens. Those results challenge the validity of our current interpolation/extrapolation definition as an indicator of generalization performances.
Decoupled Contrastive Learning
Oct 23, 2021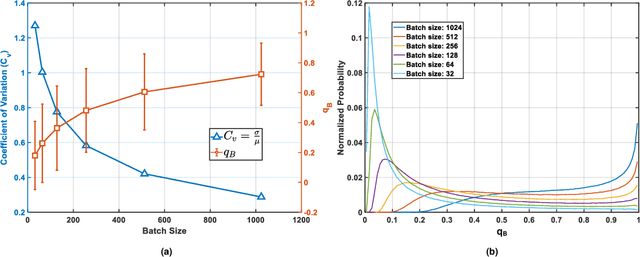
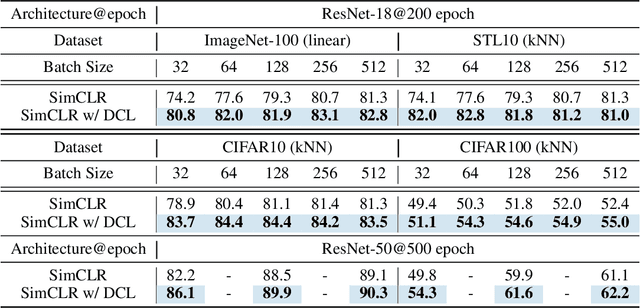
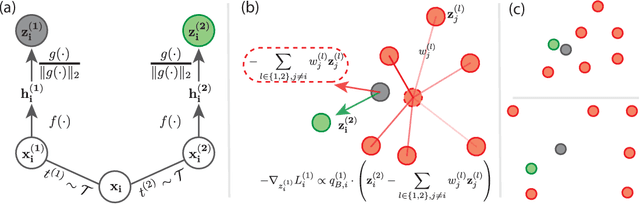

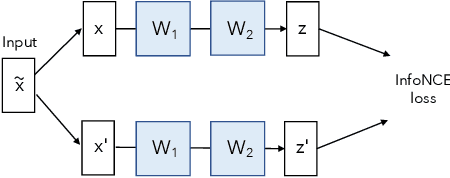
Contrastive learning (CL) is one of the most successful paradigms for self-supervised learning (SSL). In a principled way, it considers two augmented "views" of the same image as positive to be pulled closer, and all other images negative to be pushed further apart. However, behind the impressive success of CL-based techniques, their formulation often relies on heavy-computation settings, including large sample batches, extensive training epochs, etc. We are thus motivated to tackle these issues and aim at establishing a simple, efficient, and yet competitive baseline of contrastive learning. Specifically, we identify, from theoretical and empirical studies, a noticeable negative-positive-coupling (NPC) effect in the widely used cross-entropy (InfoNCE) loss, leading to unsuitable learning efficiency with respect to the batch size. Indeed the phenomenon tends to be neglected in that optimizing infoNCE loss with a small-size batch is effective in solving easier SSL tasks. By properly addressing the NPC effect, we reach a decoupled contrastive learning (DCL) objective function, significantly improving SSL efficiency. DCL can achieve competitive performance, requiring neither large batches in SimCLR, momentum encoding in MoCo, or large epochs. We demonstrate the usefulness of DCL in various benchmarks, while manifesting its robustness being much less sensitive to suboptimal hyperparameters. Notably, our approach achieves $66.9\%$ ImageNet top-1 accuracy using batch size 256 within 200 epochs pre-training, outperforming its baseline SimCLR by $5.1\%$. With further optimized hyperparameters, DCL can improve the accuracy to $68.2\%$. We believe DCL provides a valuable baseline for future contrastive learning-based SSL studies.
Understanding Dimensional Collapse in Contrastive Self-supervised Learning
Oct 18, 2021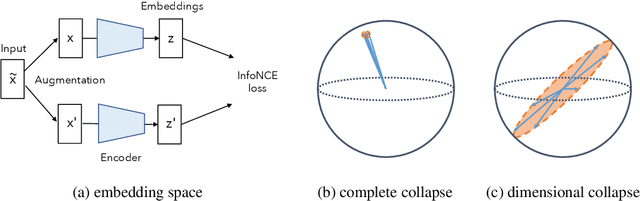

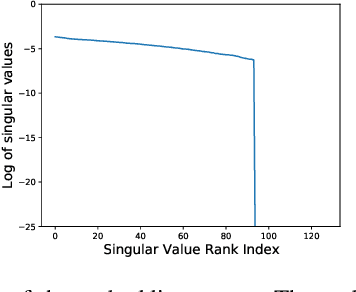
Self-supervised visual representation learning aims to learn useful representations without relying on human annotations. Joint embedding approach bases on maximizing the agreement between embedding vectors from different views of the same image. Various methods have been proposed to solve the collapsing problem where all embedding vectors collapse to a trivial constant solution. Among these methods, contrastive learning prevents collapse via negative sample pairs. It has been shown that non-contrastive methods suffer from a lesser collapse problem of a different nature: dimensional collapse, whereby the embedding vectors end up spanning a lower-dimensional subspace instead of the entire available embedding space. Here, we show that dimensional collapse also happens in contrastive learning. In this paper, we shed light on the dynamics at play in contrastive learning that leads to dimensional collapse. Inspired by our theory, we propose a novel contrastive learning method, called DirectCLR, which directly optimizes the representation space without relying on a trainable projector. Experiments show that DirectCLR outperforms SimCLR with a trainable linear projector on ImageNet.
Recurrent Parameter Generators
Jul 15, 2021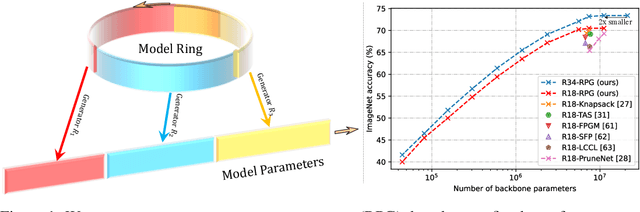
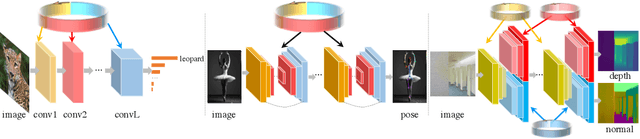
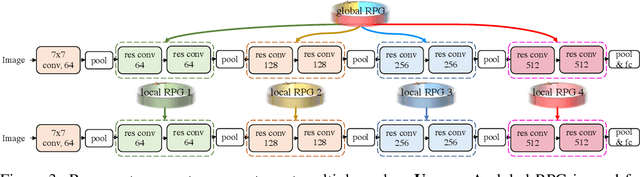

We present a generic method for recurrently using the same parameters for many different convolution layers to build a deep network. Specifically, for a network, we create a recurrent parameter generator (RPG), from which the parameters of each convolution layer are generated. Though using recurrent models to build a deep convolutional neural network (CNN) is not entirely new, our method achieves significant performance gain compared to the existing works. We demonstrate how to build a one-layer neural network to achieve similar performance compared to other traditional CNN models on various applications and datasets. Such a method allows us to build an arbitrarily complex neural network with any amount of parameters. For example, we build a ResNet34 with model parameters reduced by more than $400$ times, which still achieves $41.6\%$ ImageNet top-1 accuracy. Furthermore, we demonstrate the RPG can be applied at different scales, such as layers, blocks, or even sub-networks. Specifically, we use the RPG to build a ResNet18 network with the number of weights equivalent to one convolutional layer of a conventional ResNet and show this model can achieve $67.2\%$ ImageNet top-1 accuracy. The proposed method can be viewed as an inverse approach to model compression. Rather than removing the unused parameters from a large model, it aims to squeeze more information into a small number of parameters. Extensive experiment results are provided to demonstrate the power of the proposed recurrent parameter generator.
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
May 11, 2021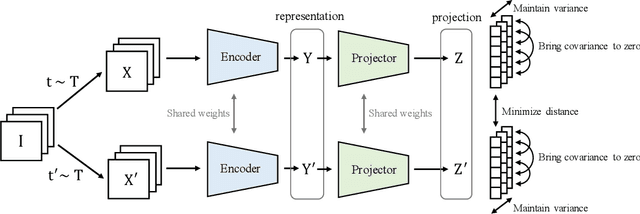
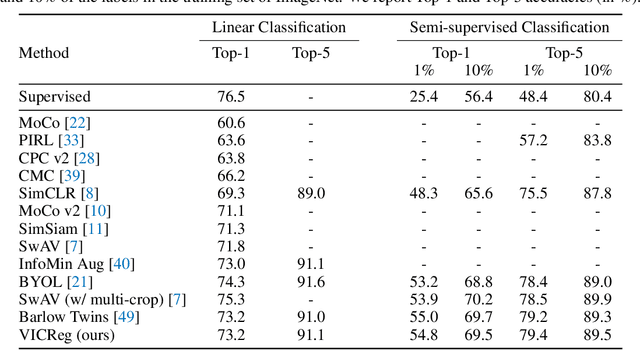
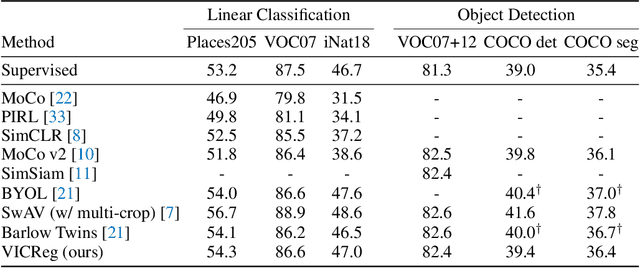
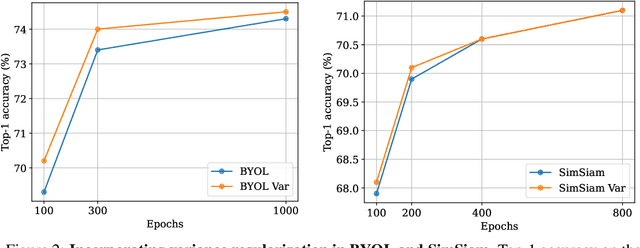
Recent self-supervised methods for image representation learning are based on maximizing the agreement between embedding vectors from different views of the same image. A trivial solution is obtained when the encoder outputs constant vectors. This collapse problem is often avoided through implicit biases in the learning architecture, that often lack a clear justification or interpretation. In this paper, we introduce VICReg (Variance-Invariance-Covariance Regularization), a method that explicitly avoids the collapse problem with a simple regularization term on the variance of the embeddings along each dimension individually. VICReg combines the variance term with a decorrelation mechanism based on redundancy reduction and covariance regularization, and achieves results on par with the state of the art on several downstream tasks. In addition, we show that incorporating our new variance term into other methods helps stabilize the training and leads to performance improvements.
MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
Apr 26, 2021
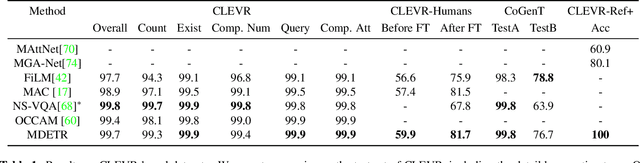
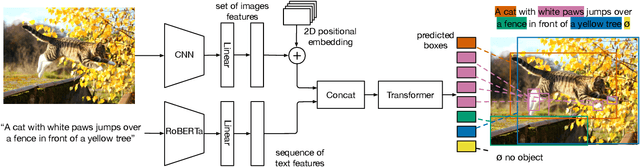
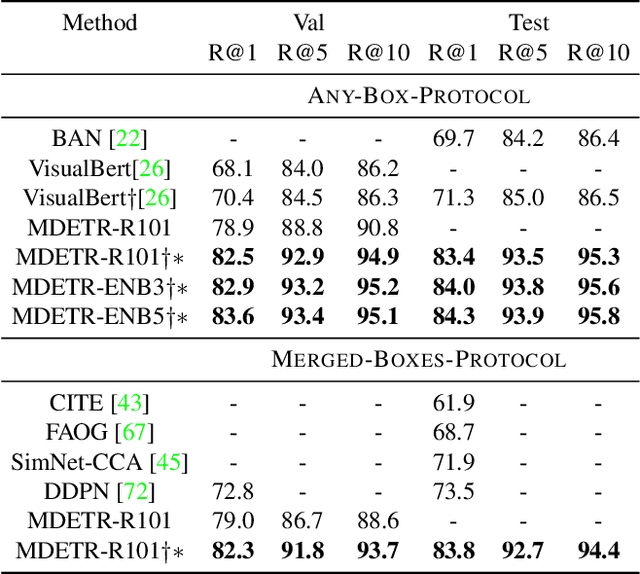
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes. This makes it challenging for such systems to capture the long tail of visual concepts expressed in free form text. In this paper we propose MDETR, an end-to-end modulated detector that detects objects in an image conditioned on a raw text query, like a caption or a question. We use a transformer-based architecture to reason jointly over text and image by fusing the two modalities at an early stage of the model. We pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image. We then fine-tune on several downstream tasks such as phrase grounding, referring expression comprehension and segmentation, achieving state-of-the-art results on popular benchmarks. We also investigate the utility of our model as an object detector on a given label set when fine-tuned in a few-shot setting. We show that our pre-training approach provides a way to handle the long tail of object categories which have very few labelled instances. Our approach can be easily extended for visual question answering, achieving competitive performance on GQA and CLEVR. The code and models are available at https://github.com/ashkamath/mdetr.
Transformer visualization via dictionary learning: contextualized embedding as a linear superposition of transformer factors
Mar 29, 2021

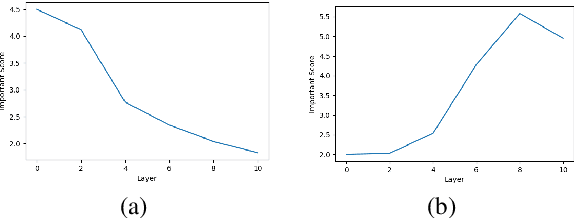

Transformer networks have revolutionized NLP representation learning since they were introduced. Though a great effort has been made to explain the representation in transformers, it is widely recognized that our understanding is not sufficient. One important reason is that there lack enough visualization tools for detailed analysis. In this paper, we propose to use dictionary learning to open up these `black boxes' as linear superpositions of transformer factors. Through visualization, we demonstrate the hierarchical semantic structures captured by the transformer factors, e.g. word-level polysemy disambiguation, sentence-level pattern formation, and long-range dependency. While some of these patterns confirm the conventional prior linguistic knowledge, the rest are relatively unexpected, which may provide new insights. We hope this visualization tool can bring further knowledge and a better understanding of how transformer networks work.
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Mar 04, 2021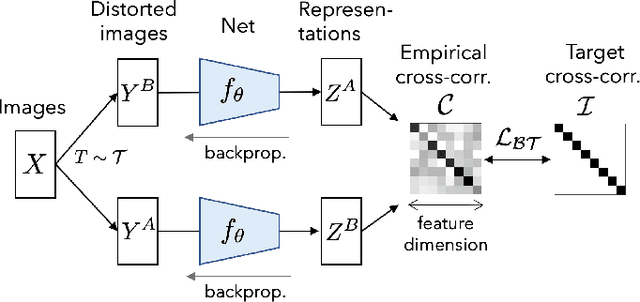
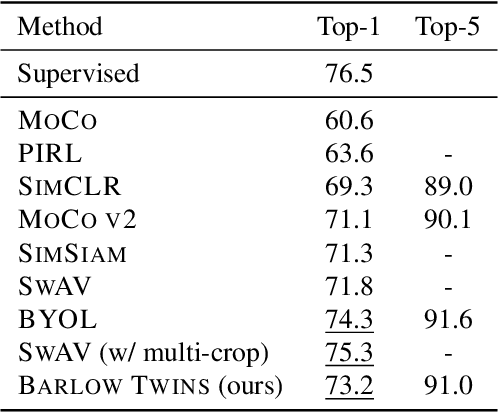
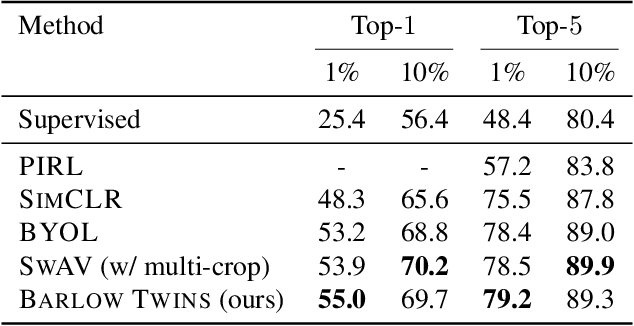
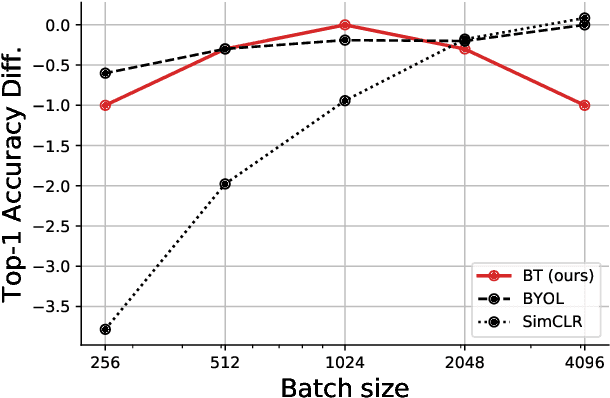
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow's redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.
Implicit Rank-Minimizing Autoencoder
Oct 14, 2020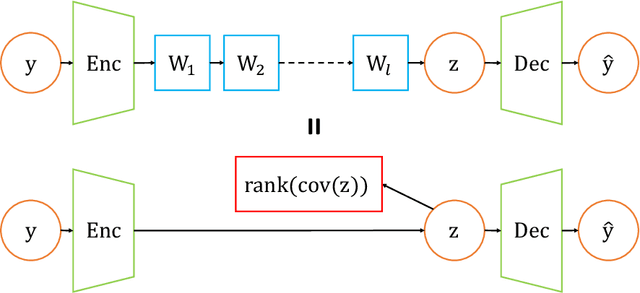
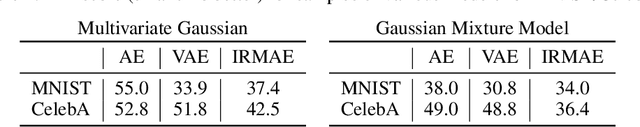
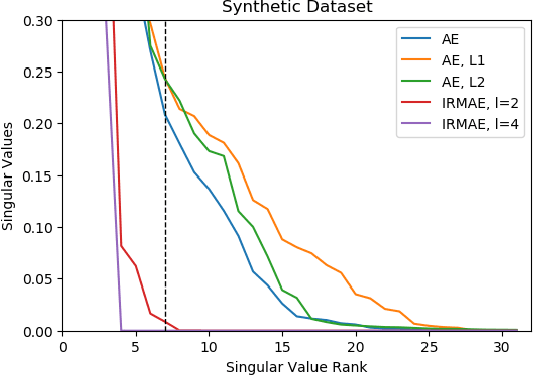
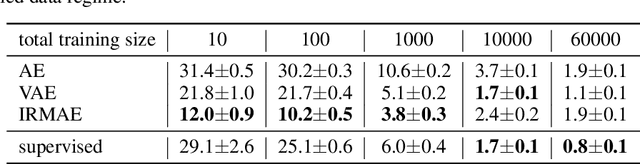
An important component of autoencoders is the method by which the information capacity of the latent representation is minimized or limited. In this work, the rank of the covariance matrix of the codes is implicitly minimized by relying on the fact that gradient descent learning in multi-layer linear networks leads to minimum-rank solutions. By inserting a number of extra linear layers between the encoder and the decoder, the system spontaneously learns representations with a low effective dimension. The model, dubbed Implicit Rank-Minimizing Autoencoder (IRMAE), is simple, deterministic, and learns compact latent spaces. We demonstrate the validity of the method on several image generation and representation learning tasks.
Inspirational Adversarial Image Generation
Jun 17, 2019

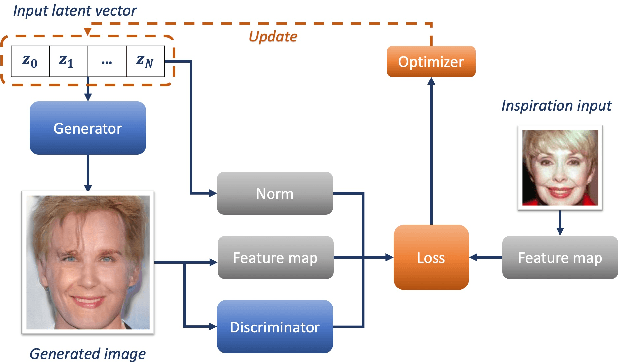
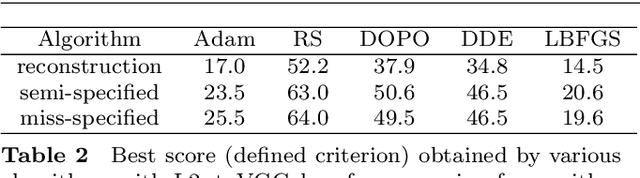
The task of image generation started to receive some attention from artists and designers to inspire them in new creations. However, exploiting the results of deep generative models such as Generative Adversarial Networks can be long and tedious given the lack of existing tools. In this work, we propose a simple strategy to inspire creators with new generations learned from a dataset of their choice, while providing some control on them. We design a simple optimization method to find the optimal latent parameters corresponding to the closest generation to any input inspirational image. Specifically, we allow the generation given an inspirational image of the user choice by performing several optimization steps to recover optimal parameters from the model's latent space. We tested several exploration methods starting with classic gradient descents to gradient-free optimizers. Many gradient-free optimizers just need comparisons (better/worse than another image), so that they can even be used without numerical criterion, without inspirational image, but with only with human preference. Thus, by iterating on one's preferences we could make robust Facial Composite or Fashion Generation algorithms. High resolution of the produced design generations are obtained using progressive growing of GANs. Our results on four datasets of faces, fashion images, and textures show that satisfactory images are effectively retrieved in most cases.