 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Evaluation of AI Agent Security Guardrails
Apr 27, 2026This report presents a comparative evaluation of DKnownAI Guard in AI agent security scenarios, benchmarked against three competing products: AWS Bedrock Guardrails, Azure Content Safety, and Lakera Guard. Using human annotation as the ground truth, we assess each guardrail's ability to detect two categories of risks: threats to the agent itself (e.g., instruction override, indirect injection, tool abuse) and requests intended to elicit harmful content (e.g., hate speech, pornography, violence). Evaluation results demonstrate that DKnownAI Guard achieves the highest recall rate at 96.5\% and ranks first in true negative rate (TNR) at 90.4\%, delivering the best overall performance among all evaluated guardrails.
QuoteR: A Benchmark of Quote Recommendation for Writing
Mar 14, 2022
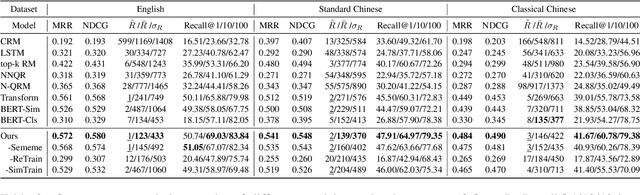
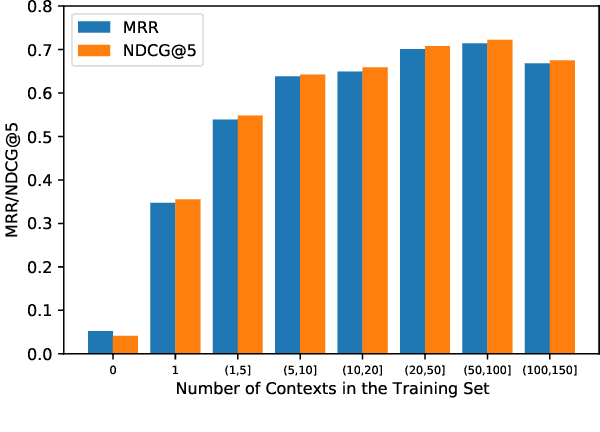

It is very common to use quotations (quotes) to make our writings more elegant or convincing. To help people find appropriate quotes efficiently, the task of quote recommendation is presented, aiming to recommend quotes that fit the current context of writing. There have been various quote recommendation approaches, but they are evaluated on different unpublished datasets. To facilitate the research on this task, we build a large and fully open quote recommendation dataset called QuoteR, which comprises three parts including English, standard Chinese and classical Chinese. Any part of it is larger than previous unpublished counterparts. We conduct an extensive evaluation of existing quote recommendation methods on QuoteR. Furthermore, we propose a new quote recommendation model that significantly outperforms previous methods on all three parts of QuoteR. All the code and data of this paper are available at https://github.com/thunlp/QuoteR.