 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausShield: Sample Reconstruction-Resilient Vertical FL via Causal Representation Learning
Jun 06, 2026Vertical federated learning (VFL) is a distributed learning paradigm that leverages vertically partitioned features across isolated parties without sharing raw samples; however, it remains vulnerable to active sample reconstruction attacks. Existing defenses fail to achieve a satisfactory trade-off between model utility and privacy protection, due to either suppressing task-relevant information alongside privacy-sensitive features or relying on end-to-end supervised training to converge the defense module, which exposes the model to early-epoch vulnerability. To address this challenge, we adopt a structural causal model (SCM) insight and construct CausShield. From a task-learning standpoint, causal features within a raw sample are those that are directly relevant and contributory to the learning objective, whereas non-causal features are task-irrelevant but often encode sample-specific private information, thereby facilitating reconstruction. Importantly, we lay a theoretical foundation to prove this insight. CausShield thus decomposes the shared representations between the client and the coordinating server in VFL into task-relevant and task-irrelevant components to ensure full-cycle privacy protection. Nonetheless, the decomposition is inherently challenging due to the dual objectives of preserving model utility while mitigating privacy leakage. We address this via a carefully formulated optimization problem, which is solved through unsupervised representation learning. We further theoretically prove that CausShield preserves the convergence behavior of standard VFL. Extensive experiments compare CausShield against seven SOTAs, including InvL (USENIX Security'25), and evaluate robustness against advanced reconstruction attacks such as URVFL (NDSS'25). Results demonstrate that CausShield consistently outperforms in privacy protection, model utility, and computational efficiency.
A Component-Based Survey of Interactions between Large Language Models and Multi-Armed Bandits
Jan 21, 2026Large language models (LLMs) have become powerful and widely used systems for language understanding and generation, while multi-armed bandit (MAB) algorithms provide a principled framework for adaptive decision-making under uncertainty. This survey explores the potential at the intersection of these two fields. As we know, it is the first survey to systematically review the bidirectional interaction between large language models and multi-armed bandits at the component level. We highlight the bidirectional benefits: MAB algorithms address critical LLM challenges, spanning from pre-training to retrieval-augmented generation (RAG) and personalization. Conversely, LLMs enhance MAB systems by redefining core components such as arm definition and environment modeling, thereby improving decision-making in sequential tasks. We analyze existing LLM-enhanced bandit systems and bandit-enhanced LLM systems, providing insights into their design, methodologies, and performance. Key challenges and representative findings are identified to help guide future research. An accompanying GitHub repository that indexes relevant literature is available at https://github.com/bucky1119/Awesome-LLM-Bandit-Interaction.
Uncertainty Minimization for Personalized Federated Semi-Supervised Learning
May 05, 2022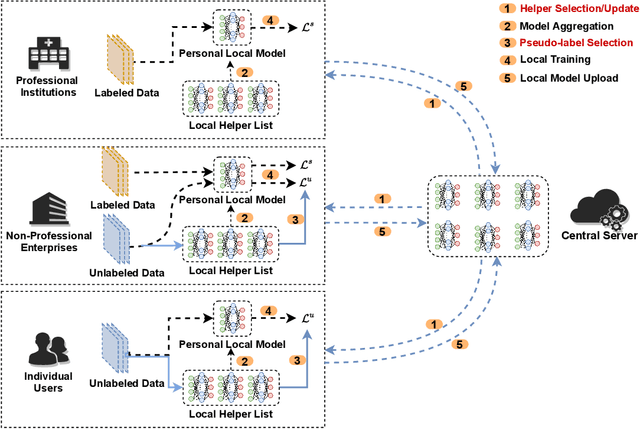
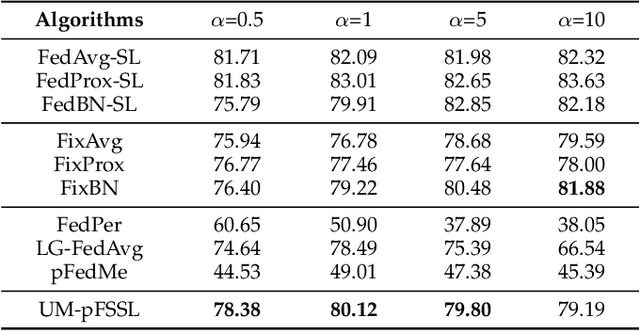
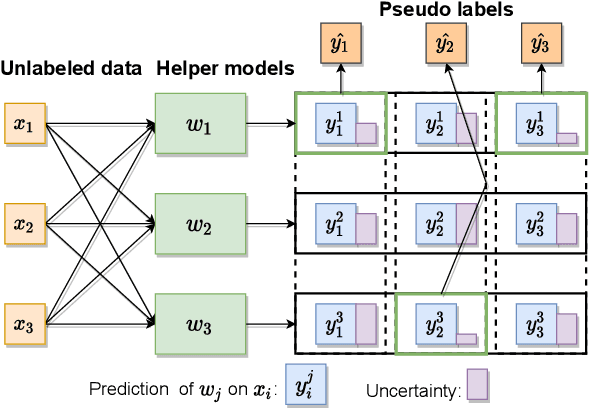
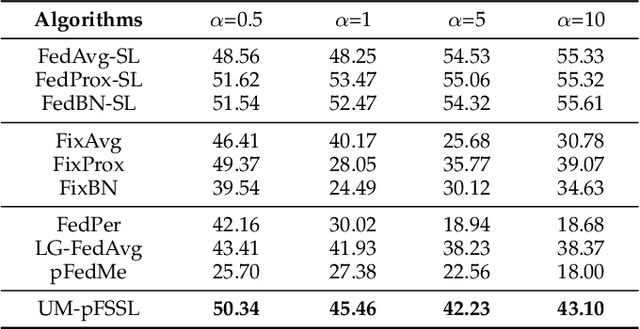
Since federated learning (FL) has been introduced as a decentralized learning technique with privacy preservation, statistical heterogeneity of distributed data stays the main obstacle to achieve robust performance and stable convergence in FL applications. Model personalization methods have been studied to overcome this problem. However, existing approaches are mainly under the prerequisite of fully labeled data, which is unrealistic in practice due to the requirement of expertise. The primary issue caused by partial-labeled condition is that, clients with deficient labeled data can suffer from unfair performance gain because they lack adequate insights of local distribution to customize the global model. To tackle this problem, 1) we propose a novel personalized semi-supervised learning paradigm which allows partial-labeled or unlabeled clients to seek labeling assistance from data-related clients (helper agents), thus to enhance their perception of local data; 2) based on this paradigm, we design an uncertainty-based data-relation metric to ensure that selected helpers can provide trustworthy pseudo labels instead of misleading the local training; 3) to mitigate the network overload introduced by helper searching, we further develop a helper selection protocol to achieve efficient communication with negligible performance sacrifice. Experiments show that our proposed method can obtain superior performance and more stable convergence than other related works with partial labeled data, especially in highly heterogeneous setting.