 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers
Mar 26, 2026Concept erasure serves as a vital safety mechanism for removing unwanted concepts from text-to-image (T2I) models. While extensively studied in U-Net and dual-stream architectures (e.g., Flux), this task remains under-explored in the recent emerging paradigm of single-stream diffusion transformers (e.g., Z-Image). In this new paradigm, text and image tokens are processed as a single unified sequence via shared parameters. Consequently, directly applying prior erasure methods typically leads to generation collapse. To bridge this gap, we introduce Z-Erase, the first concept erasure method tailored for single-stream T2I models. To guarantee stable image generation, Z-Erase first proposes a Stream Disentangled Concept Erasure Framework that decouples updates and enables existing methods on single-stream models. Subsequently, within this framework, we introduce Lagrangian-Guided Adaptive Erasure Modulation, a constrained algorithm that further balances the sensitive erasure-preservation trade-off. Moreover, we provide a rigorous convergence analysis proving that Z-Erase can converge to a Pareto stationary point. Experiments demonstrate that Z-Erase successfully overcomes the generation collapse issue, achieving state-of-the-art performance across a wide range of tasks.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Discriminative Anchor Learning for Efficient Multi-view Clustering
Sep 25, 2024



Multi-view clustering aims to study the complementary information across views and discover the underlying structure. For solving the relatively high computational cost for the existing approaches, works based on anchor have been presented recently. Even with acceptable clustering performance, these methods tend to map the original representation from multiple views into a fixed shared graph based on the original dataset. However, most studies ignore the discriminative property of the learned anchors, which ruin the representation capability of the built model. Moreover, the complementary information among anchors across views is neglected to be ensured by simply learning the shared anchor graph without considering the quality of view-specific anchors. In this paper, we propose discriminative anchor learning for multi-view clustering (DALMC) for handling the above issues. We learn discriminative view-specific feature representations according to the original dataset and build anchors from different views based on these representations, which increase the quality of the shared anchor graph. The discriminative feature learning and consensus anchor graph construction are integrated into a unified framework to improve each other for realizing the refinement. The optimal anchors from multiple views and the consensus anchor graph are learned with the orthogonal constraints. We give an iterative algorithm to deal with the formulated problem. Extensive experiments on different datasets show the effectiveness and efficiency of our method compared with other methods.
Orientation Convolutional Networks for Image Recognition
Feb 02, 2021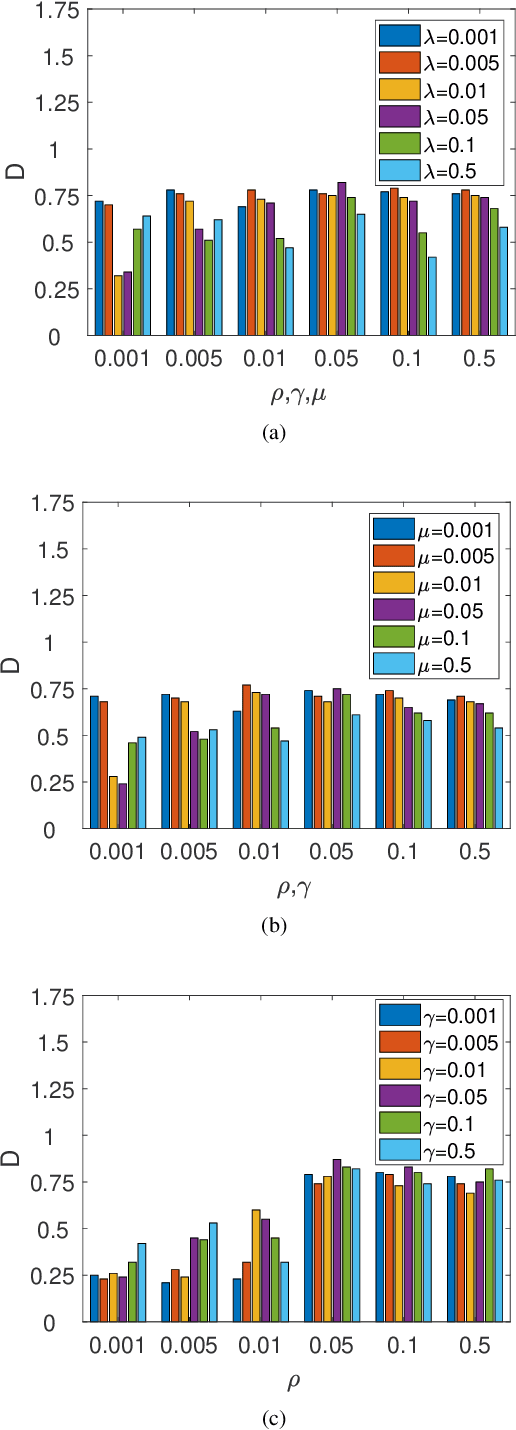
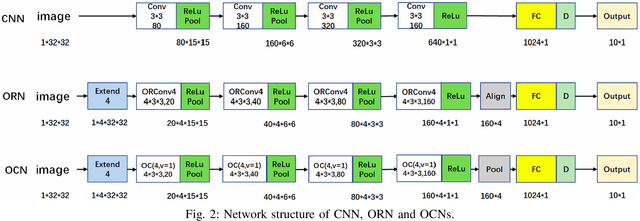
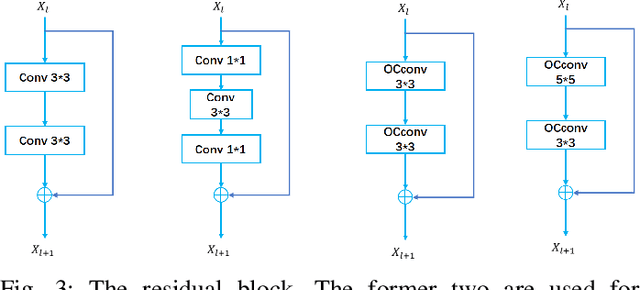

Deep Convolutional Neural Networks (DCNNs) are capable of obtaining powerful image representations, which have attracted great attentions in image recognition. However, they are limited in modeling orientation transformation by the internal mechanism. In this paper, we develop Orientation Convolution Networks (OCNs) for image recognition based on the proposed Landmark Gabor Filters (LGFs) that the robustness of the learned representation against changed of orientation can be enhanced. By modulating the convolutional filter with LGFs, OCNs can be compatible with any existing deep learning networks. LGFs act as a Gabor filter bank achieved by selecting $ p $ $ \left( \ll n\right) $ representative Gabor filters as andmarks and express the original Gabor filters as sparse linear combinations of these landmarks. Specifically, based on a matrix factorization framework, a flexible integration for the local and the global structure of original Gabor filters by sparsity and low-rank constraints is utilized. With the propogation of the low-rank structure, the corresponding sparsity for representation of original Gabor filter bank can be significantly promoted. Experimental results over several benchmarks demonstrate that our method is less sensitive to the orientation and produce higher performance both in accuracy and cost, compared with the existing state-of-art methods. Besides, our OCNs have few parameters to learn and can significantly reduce the complexity of training network.