 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Speech Synthesis For Speech-To-Speech Translation
Oct 15, 2021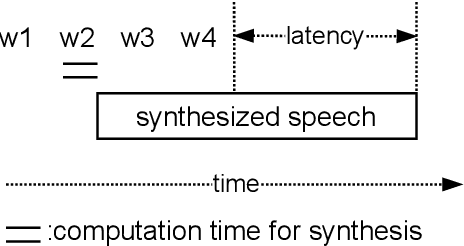
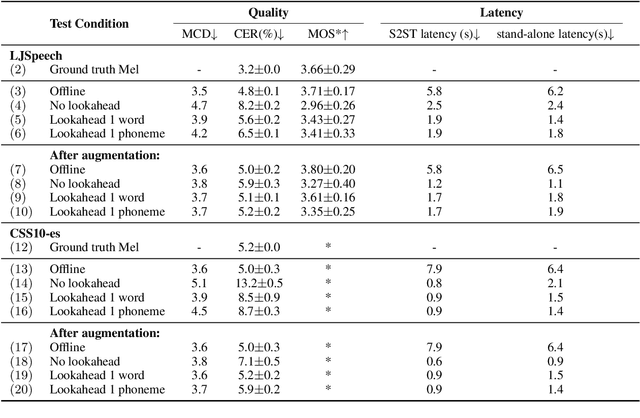

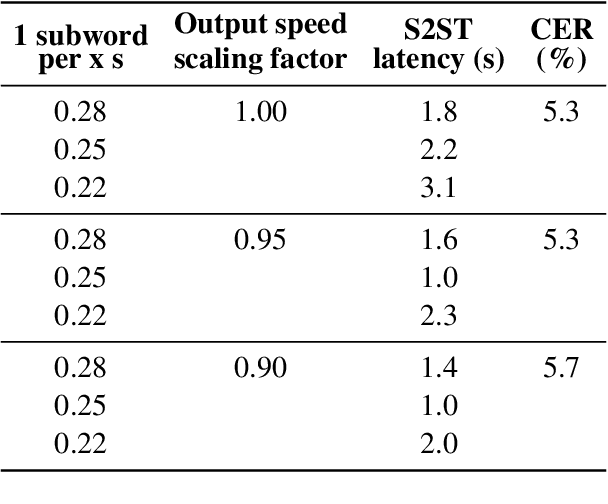
In a speech-to-speech translation (S2ST) pipeline, the text-to-speech (TTS) module is an important component for delivering the translated speech to users. To enable incremental S2ST, the TTS module must be capable of synthesizing and playing utterances while its input text is still streaming in. In this work, we focus on improving the incremental synthesis performance of TTS models. With a simple data augmentation strategy based on prefixes, we are able to improve the incremental TTS quality to approach offline performance. Furthermore, we bring our incremental TTS system to the practical scenario in combination with an upstream simultaneous speech translation system, and show the gains also carry over to this use-case. In addition, we propose latency metrics tailored to S2ST applications, and investigate methods for latency reduction in this context.
Direct speech-to-speech translation with discrete units
Jul 12, 2021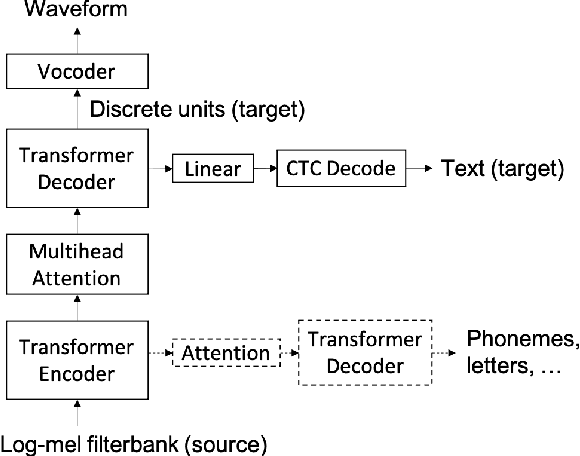
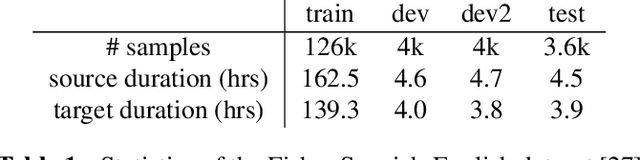
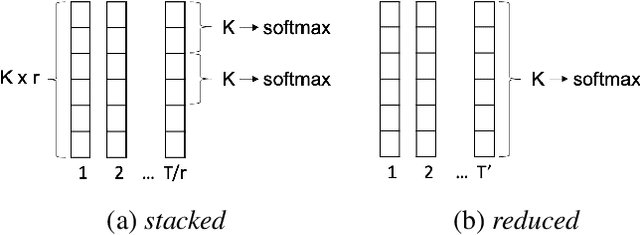
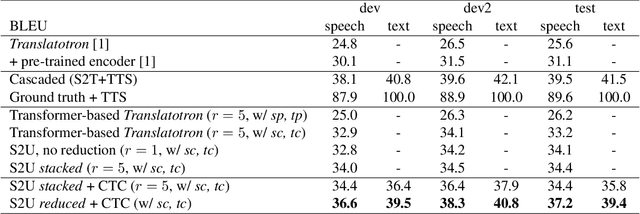
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.
SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation
Nov 03, 2020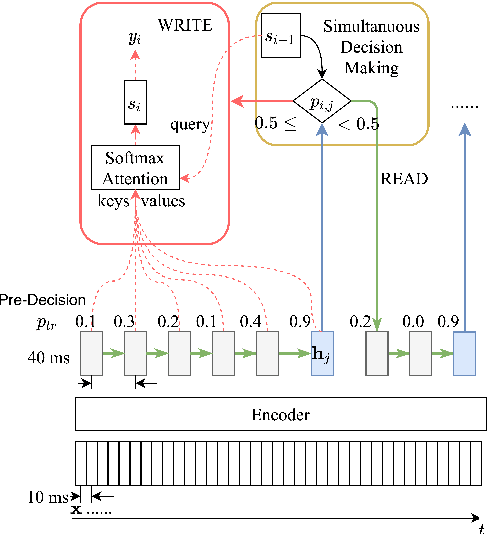
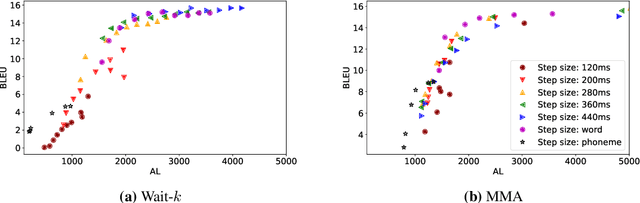
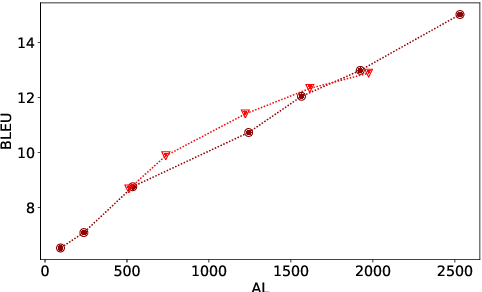
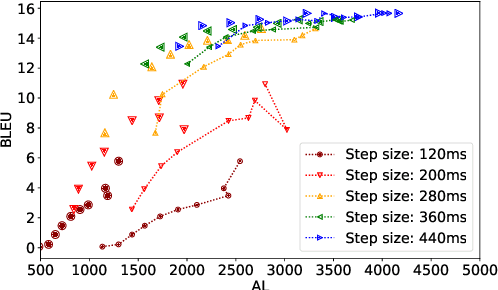
Simultaneous text translation and end-to-end speech translation have recently made great progress but little work has combined these tasks together. We investigate how to adapt simultaneous text translation methods such as wait-k and monotonic multihead attention to end-to-end simultaneous speech translation by introducing a pre-decision module. A detailed analysis is provided on the latency-quality trade-offs of combining fixed and flexible pre-decision with fixed and flexible policies. We also design a novel computation-aware latency metric, adapted from Average Lagging.
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020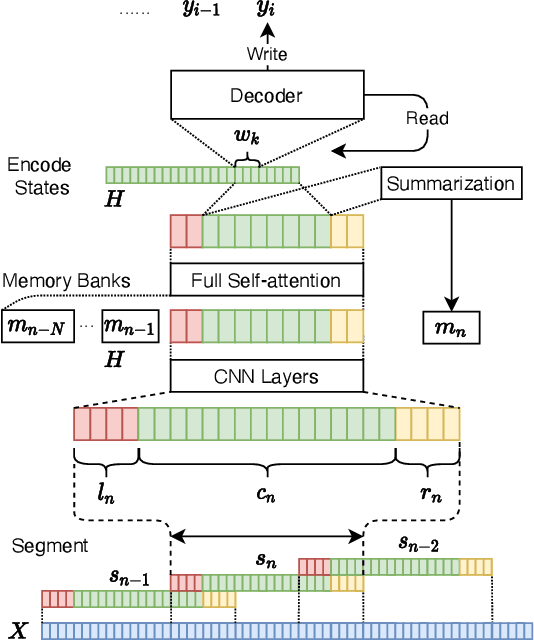
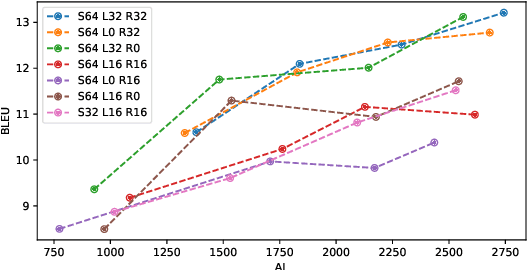
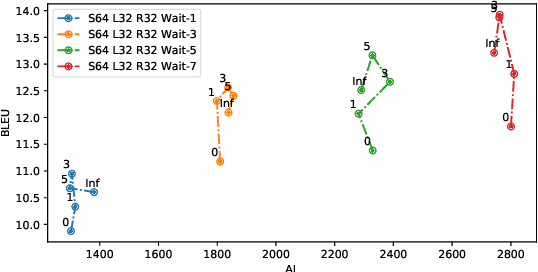
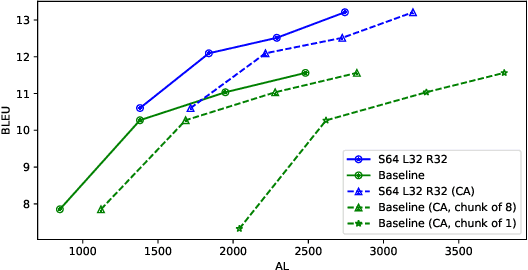
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.
A General Multi-Task Learning Framework to Leverage Text Data for Speech to Text Tasks
Oct 21, 2020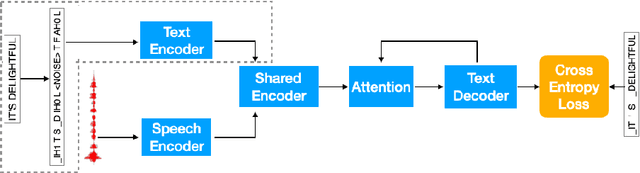
Attention-based sequence-to-sequence modeling provides a powerful and elegant solution for applications that need to map one sequence to a different sequence. Its success heavily relies on the availability of large amounts of training data. This presents a challenge for speech applications where labelled speech data is very expensive to obtain, such as automatic speech recognition (ASR) and speech translation (ST). In this study, we propose a general multi-task learning framework to leverage text data for ASR and ST tasks. Two auxiliary tasks, a denoising autoencoder task and machine translation task, are proposed to be co-trained with ASR and ST tasks respectively. We demonstrate that representing text input as phoneme sequences can reduce the difference between speech and text inputs, and enhance the knowledge transfer from text corpora to the speech to text tasks. Our experiments show that the proposed method achieves a relative 10~15% word error rate reduction on the English Librispeech task, and improves the speech translation quality on the MuST-C tasks by 4.2~11.1 BLEU.
fairseq S2T: Fast Speech-to-Text Modeling with fairseq
Oct 11, 2020

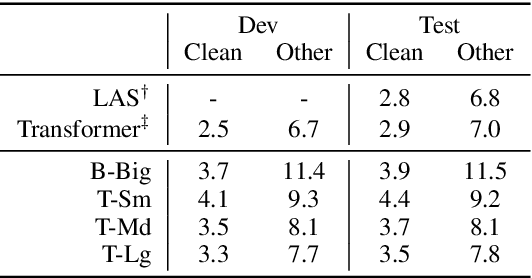
We introduce fairseq S2T, a fairseq extension for speech-to-text (S2T) modeling tasks such as end-to-end speech recognition and speech-to-text translation. It follows fairseq's careful design for scalability and extensibility. We provide end-to-end workflows from data pre-processing, model training to offline (online) inference. We implement state-of-the-art RNN-based as well as Transformer-based models and open-source detailed training recipes. Fairseq's machine translation models and language models can be seamlessly integrated into S2T workflows for multi-task learning or transfer learning. Fairseq S2T documentation and examples are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text.
SimulEval: An Evaluation Toolkit for Simultaneous Translation
Jul 31, 2020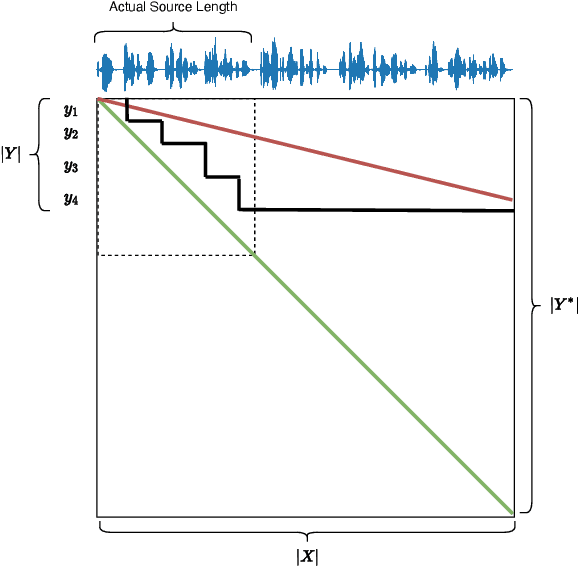

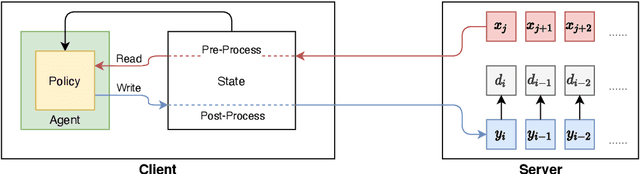
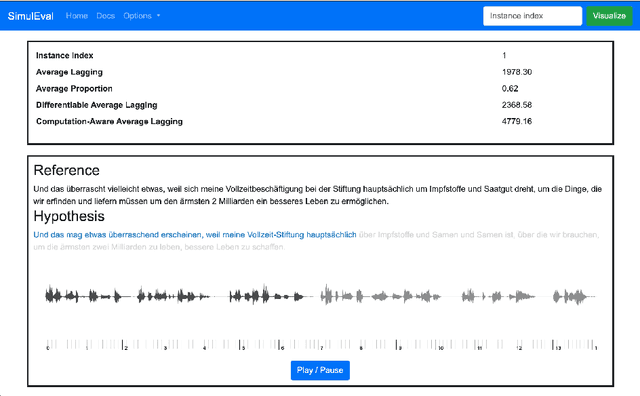
Simultaneous translation on both text and speech focuses on a real-time and low-latency scenario where the model starts translating before reading the complete source input. Evaluating simultaneous translation models is more complex than offline models because the latency is another factor to consider in addition to translation quality. The research community, despite its growing focus on novel modeling approaches to simultaneous translation, currently lacks a universal evaluation procedure. Therefore, we present SimulEval, an easy-to-use and general evaluation toolkit for both simultaneous text and speech translation. A server-client scheme is introduced to create a simultaneous translation scenario, where the server sends source input and receives predictions for evaluation and the client executes customized policies. Given a policy, it automatically performs simultaneous decoding and collectively reports several popular latency metrics. We also adapt latency metrics from text simultaneous translation to the speech task. Additionally, SimulEval is equipped with a visualization interface to provide better understanding of the simultaneous decoding process of a system. SimulEval has already been extensively used for the IWSLT 2020 shared task on simultaneous speech translation. Code will be released upon publication.
Self-Training for End-to-End Speech Translation
Jun 03, 2020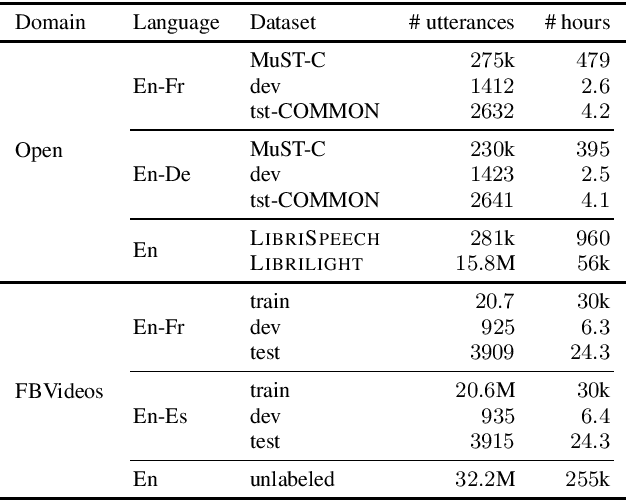
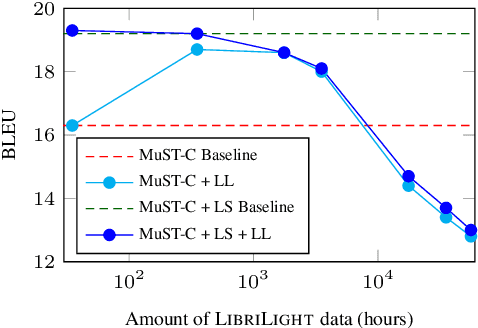
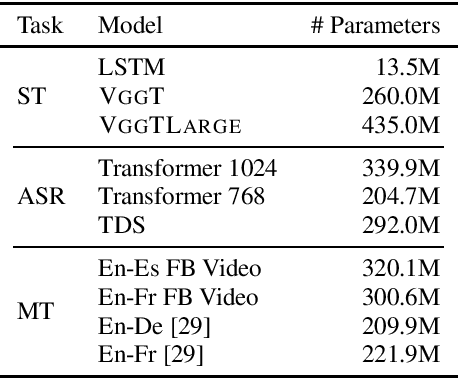
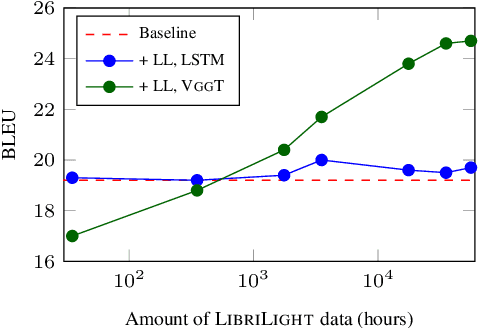
One of the main challenges for end-to-end speech translation is data scarcity. We leverage pseudo-labels generated from unlabeled audio by a cascade and an end-to-end speech translation model. This provides 8.3 and 5.7 BLEU gains over a strong semi-supervised baseline on the MuST-C English-French and English-German datasets, reaching state-of-the art performance. The effect of the quality of the pseudo-labels is investigated. Our approach is shown to be more effective than simply pre-training the encoder on the speech recognition task. Finally, we demonstrate the effectiveness of self-training by directly generating pseudo-labels with an end-to-end model instead of a cascade model.
Harnessing Indirect Training Data for End-to-End Automatic Speech Translation: Tricks of the Trade
Oct 22, 2019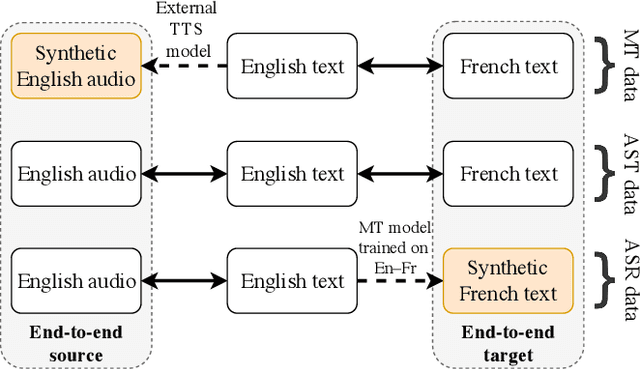
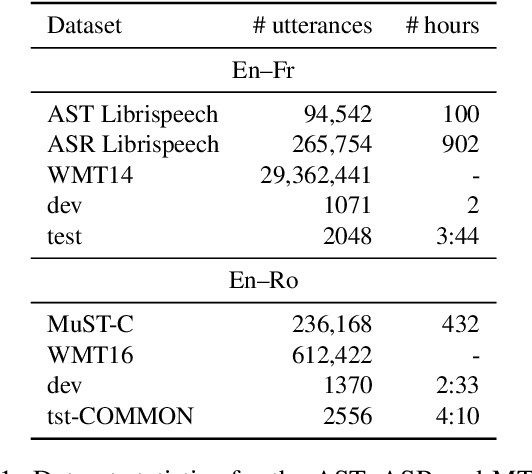
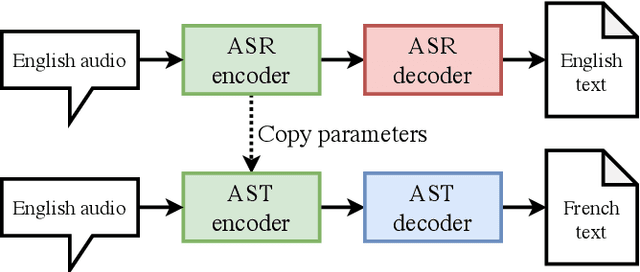
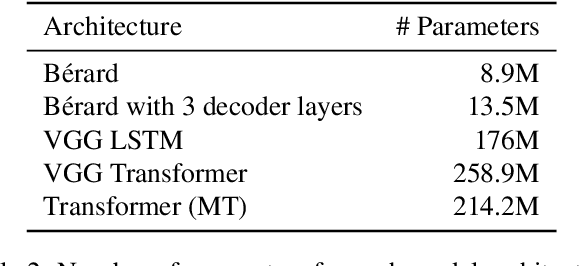
For automatic speech translation (AST), end-to-end approaches are outperformed by cascaded models that transcribe with automatic speech recognition (ASR), then translate with machine translation (MT). A major cause of the performance gap is that, while existing AST corpora are small, massive datasets exist for both the ASR and MT subsystems. In this work, we evaluate several data augmentation and pretraining approaches for AST, by comparing all on the same datasets. Simple data augmentation by translating ASR transcripts proves most effective on the English--French augmented LibriSpeech dataset, closing the performance gap from 8.2 to 1.4 BLEU, compared to a very strong cascade that could directly utilize copious ASR and MT data. The same end-to-end approach plus fine-tuning closes the gap on the English--Romanian MuST-C dataset from 6.7 to 3.7 BLEU. In addition to these results, we present practical recommendations for augmentation and pretraining approaches. Finally, we decrease the performance gap to 0.01 BLEU using a Transformer-based architecture.
Monotonic Multihead Attention
Sep 26, 2019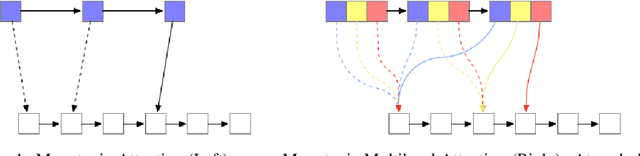
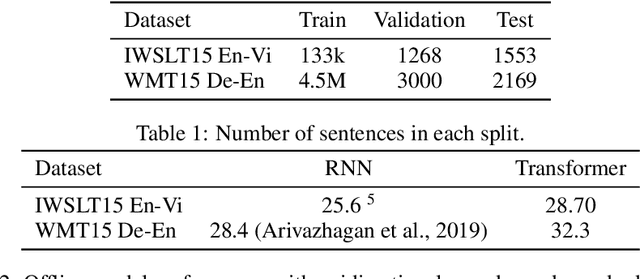
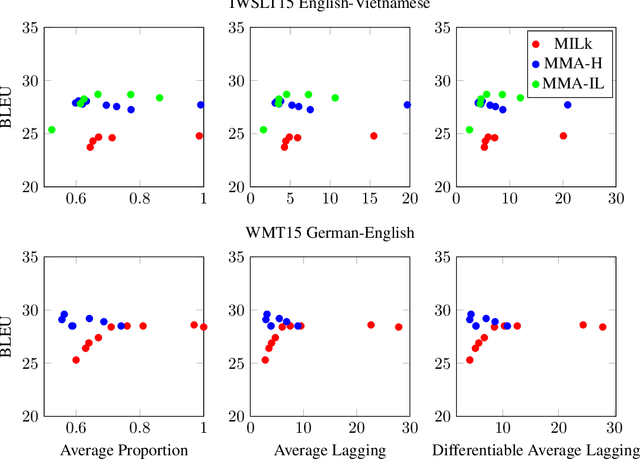
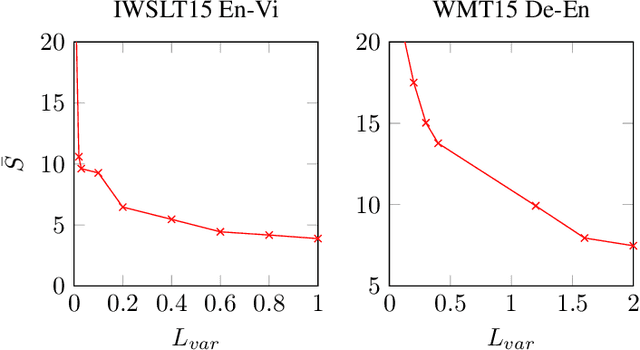
Simultaneous machine translation models start generating a target sequence before they have encoded or read the source sequence. Recent approaches for this task either apply a fixed policy on a state-of-the art Transformer model, or a learnable monotonic attention on a weaker recurrent neural network-based structure. In this paper, we propose a new attention mechanism, Monotonic Multihead Attention (MMA), which extends the monotonic attention mechanism to multihead attention. We also introduce two novel and interpretable approaches for latency control that are specifically designed for multiple attentions heads. We apply MMA to the simultaneous machine translation task and demonstrate better latency-quality tradeoffs compared to MILk, the previous state-of-the-art approach. We also analyze how the latency controls affect the attention span and we motivate the introduction of our model by analyzing the effect of the number of decoder layers and heads on quality and latency.