 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinAugment: Auto-Encoding Speaker Conversions for Automatic Speech Translation
Feb 27, 2020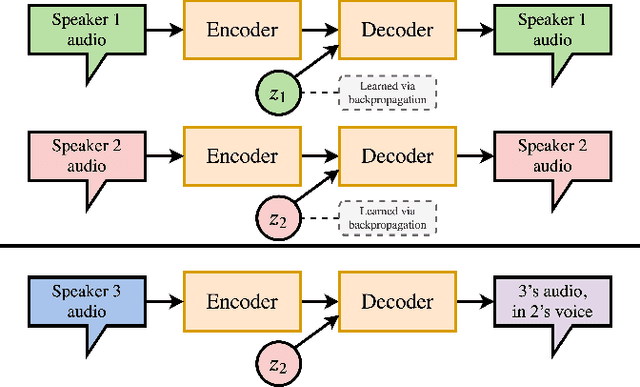
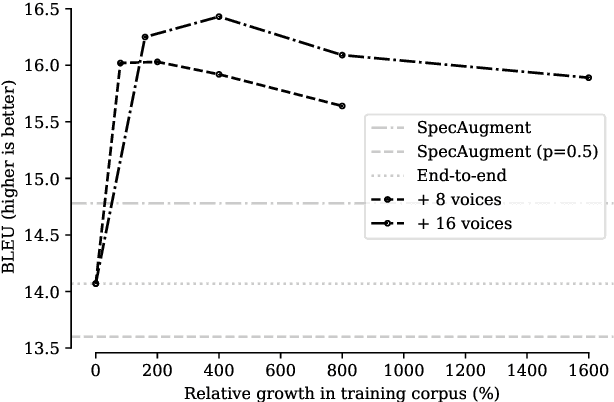
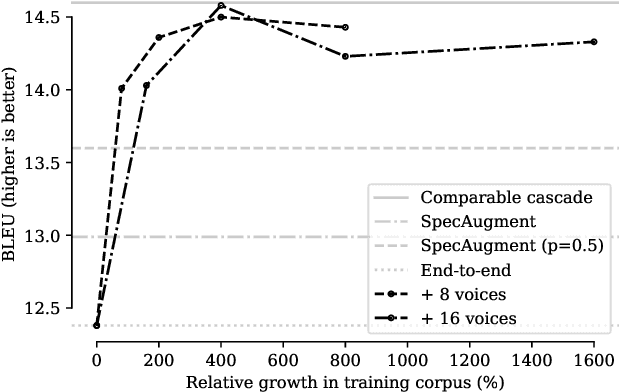
We propose autoencoding speaker conversion for training data augmentation in automatic speech translation. This technique directly transforms an audio sequence, resulting in audio synthesized to resemble another speaker's voice. Our method compares favorably to SpecAugment on English$\to$French and English$\to$Romanian automatic speech translation (AST) tasks as well as on a low-resource English automatic speech recognition (ASR) task. Further, in ablations, we show the benefits of both quantity and diversity in augmented data. Finally, we show that we can combine our approach with augmentation by machine-translated transcripts to obtain a competitive end-to-end AST model that outperforms a very strong cascade model on an English$\to$French AST task. Our method is sufficiently general that it can be applied to other speech generation and analysis tasks.
Harnessing Indirect Training Data for End-to-End Automatic Speech Translation: Tricks of the Trade
Oct 22, 2019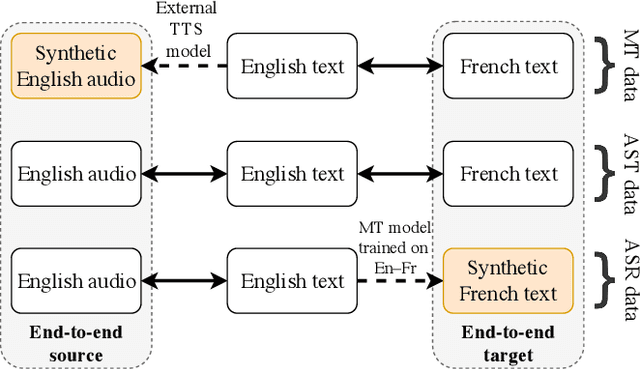
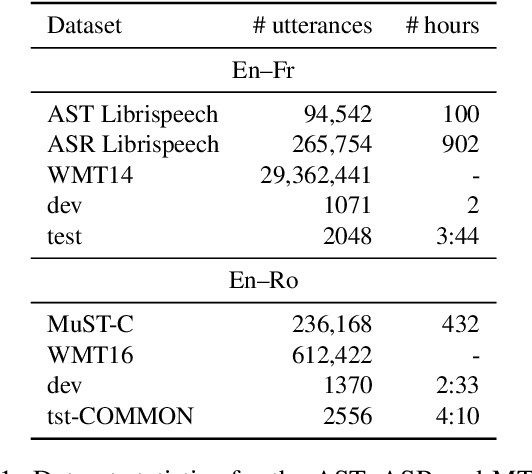
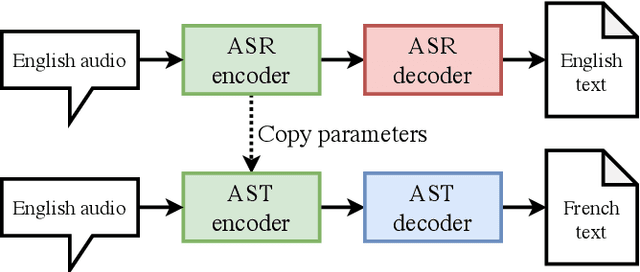
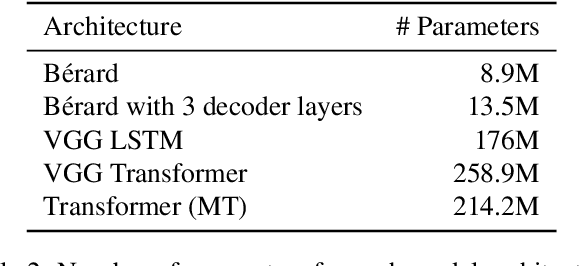
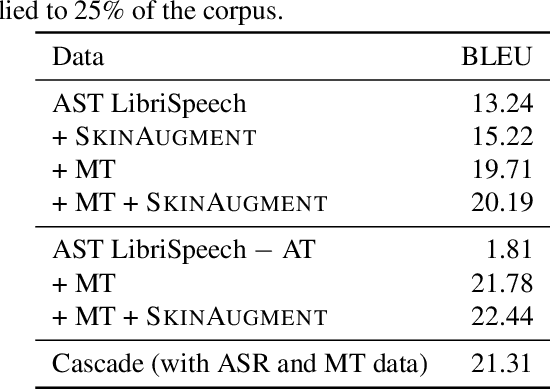
For automatic speech translation (AST), end-to-end approaches are outperformed by cascaded models that transcribe with automatic speech recognition (ASR), then translate with machine translation (MT). A major cause of the performance gap is that, while existing AST corpora are small, massive datasets exist for both the ASR and MT subsystems. In this work, we evaluate several data augmentation and pretraining approaches for AST, by comparing all on the same datasets. Simple data augmentation by translating ASR transcripts proves most effective on the English--French augmented LibriSpeech dataset, closing the performance gap from 8.2 to 1.4 BLEU, compared to a very strong cascade that could directly utilize copious ASR and MT data. The same end-to-end approach plus fine-tuning closes the gap on the English--Romanian MuST-C dataset from 6.7 to 3.7 BLEU. In addition to these results, we present practical recommendations for augmentation and pretraining approaches. Finally, we decrease the performance gap to 0.01 BLEU using a Transformer-based architecture.
Monotonic Multihead Attention
Sep 26, 2019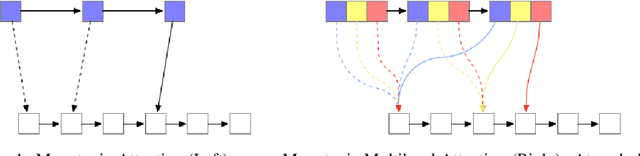
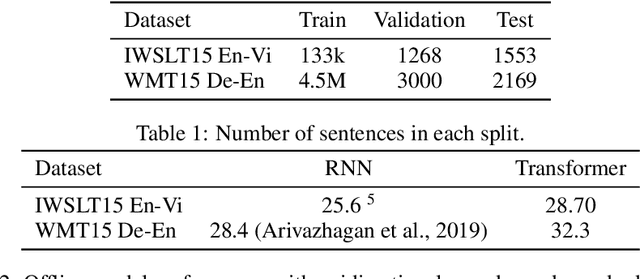
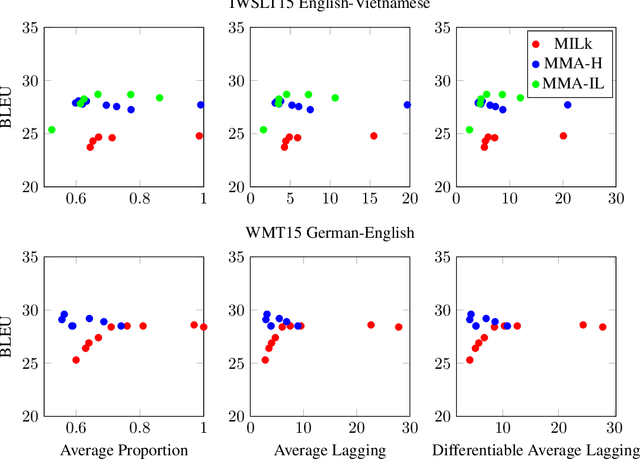
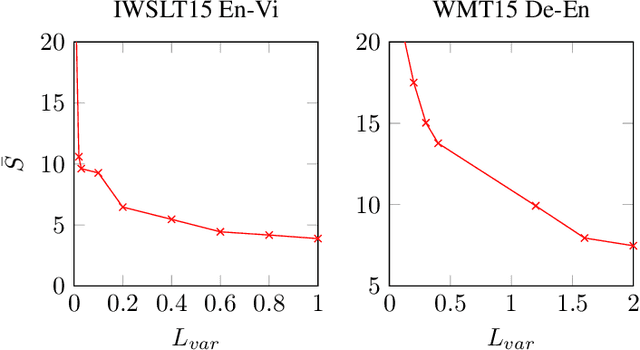
Simultaneous machine translation models start generating a target sequence before they have encoded or read the source sequence. Recent approaches for this task either apply a fixed policy on a state-of-the art Transformer model, or a learnable monotonic attention on a weaker recurrent neural network-based structure. In this paper, we propose a new attention mechanism, Monotonic Multihead Attention (MMA), which extends the monotonic attention mechanism to multihead attention. We also introduce two novel and interpretable approaches for latency control that are specifically designed for multiple attentions heads. We apply MMA to the simultaneous machine translation task and demonstrate better latency-quality tradeoffs compared to MILk, the previous state-of-the-art approach. We also analyze how the latency controls affect the attention span and we motivate the introduction of our model by analyzing the effect of the number of decoder layers and heads on quality and latency.