 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBI-GCN: Boundary-Aware Input-Dependent Graph Convolution Network for Biomedical Image Segmentation
Oct 31, 2021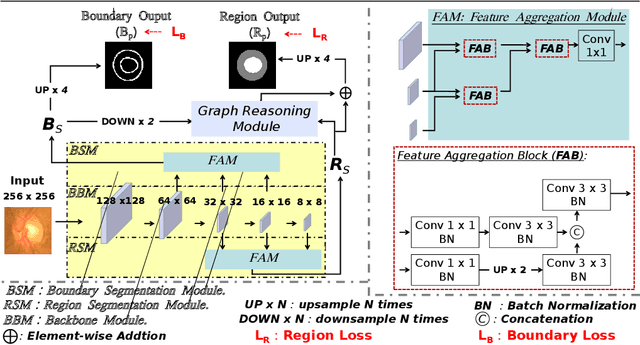



Segmentation is an essential operation of image processing. The convolution operation suffers from a limited receptive field, while global modelling is fundamental to segmentation tasks. In this paper, we apply graph convolution into the segmentation task and propose an improved \textit{Laplacian}. Different from existing methods, our \textit{Laplacian} is data-dependent, and we introduce two attention diagonal matrices to learn a better vertex relationship. In addition, it takes advantage of both region and boundary information when performing graph-based information propagation. Specifically, we model and reason about the boundary-aware region-wise correlations of different classes through learning graph representations, which is capable of manipulating long range semantic reasoning across various regions with the spatial enhancement along the object's boundary. Our model is well-suited to obtain global semantic region information while also accommodates local spatial boundary characteristics simultaneously. Experiments on two types of challenging datasets demonstrate that our method outperforms the state-of-the-art approaches on the segmentation of polyps in colonoscopy images and of the optic disc and optic cup in colour fundus images.
Video Annotation for Visual Tracking via Selection and Refinement
Aug 09, 2021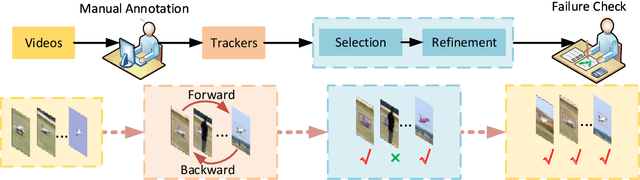
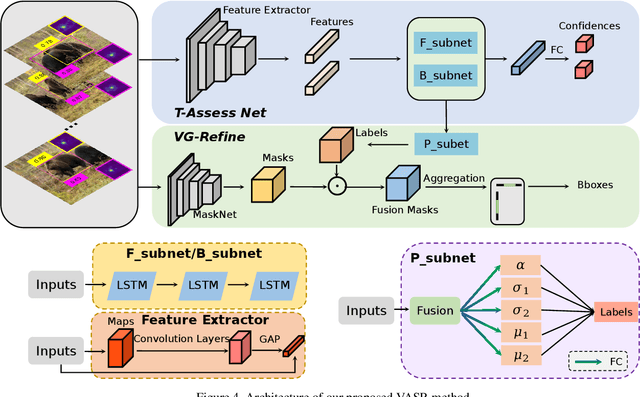
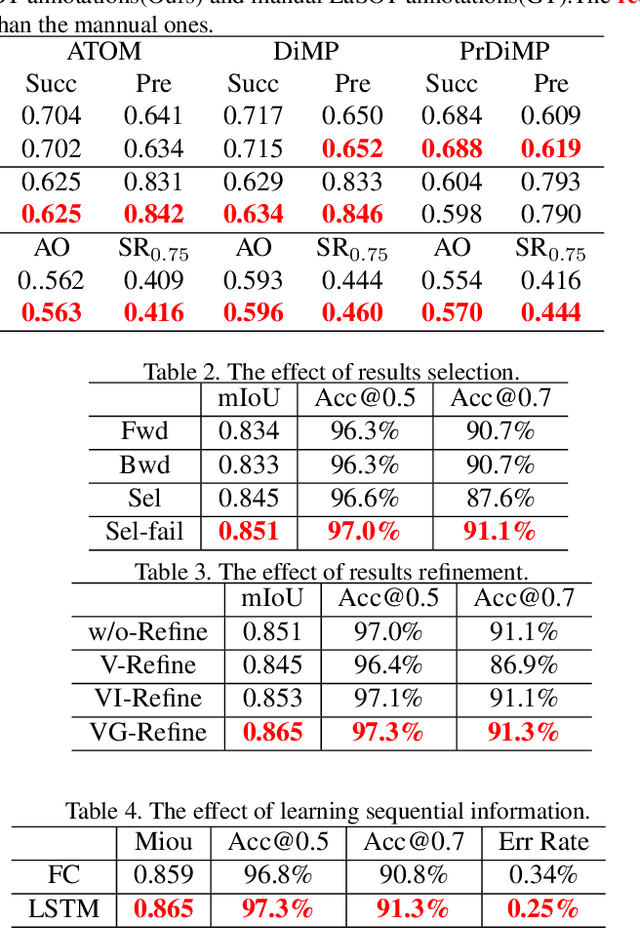
Deep learning based visual trackers entail offline pre-training on large volumes of video datasets with accurate bounding box annotations that are labor-expensive to achieve. We present a new framework to facilitate bounding box annotations for video sequences, which investigates a selection-and-refinement strategy to automatically improve the preliminary annotations generated by tracking algorithms. A temporal assessment network (T-Assess Net) is proposed which is able to capture the temporal coherence of target locations and select reliable tracking results by measuring their quality. Meanwhile, a visual-geometry refinement network (VG-Refine Net) is also designed to further enhance the selected tracking results by considering both target appearance and temporal geometry constraints, allowing inaccurate tracking results to be corrected. The combination of the above two networks provides a principled approach to ensure the quality of automatic video annotation. Experiments on large scale tracking benchmarks demonstrate that our method can deliver highly accurate bounding box annotations and significantly reduce human labor by 94.0%, yielding an effective means to further boost tracking performance with augmented training data.
Spatial Uncertainty-Aware Semi-Supervised Crowd Counting
Aug 02, 2021
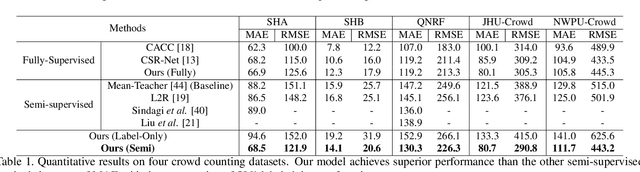
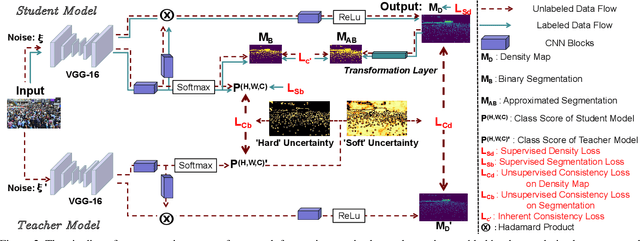
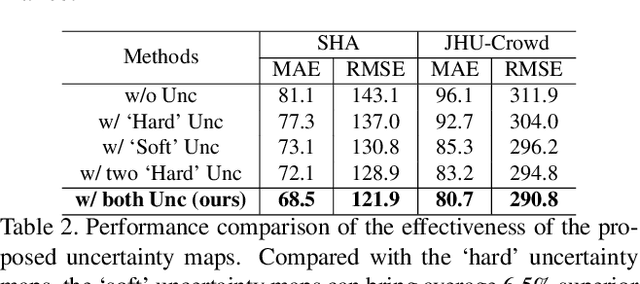
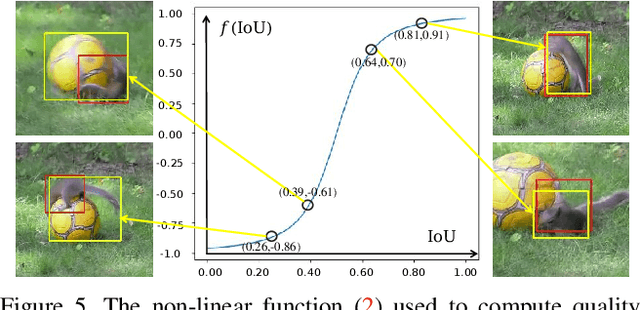
Semi-supervised approaches for crowd counting attract attention, as the fully supervised paradigm is expensive and laborious due to its request for a large number of images of dense crowd scenarios and their annotations. This paper proposes a spatial uncertainty-aware semi-supervised approach via regularized surrogate task (binary segmentation) for crowd counting problems. Different from existing semi-supervised learning-based crowd counting methods, to exploit the unlabeled data, our proposed spatial uncertainty-aware teacher-student framework focuses on high confident regions' information while addressing the noisy supervision from the unlabeled data in an end-to-end manner. Specifically, we estimate the spatial uncertainty maps from the teacher model's surrogate task to guide the feature learning of the main task (density regression) and the surrogate task of the student model at the same time. Besides, we introduce a simple yet effective differential transformation layer to enforce the inherent spatial consistency regularization between the main task and the surrogate task in the student model, which helps the surrogate task to yield more reliable predictions and generates high-quality uncertainty maps. Thus, our model can also address the task-level perturbation problems that occur spatial inconsistency between the primary and surrogate tasks in the student model. Experimental results on four challenging crowd counting datasets demonstrate that our method achieves superior performance to the state-of-the-art semi-supervised methods.
A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification
Apr 05, 2021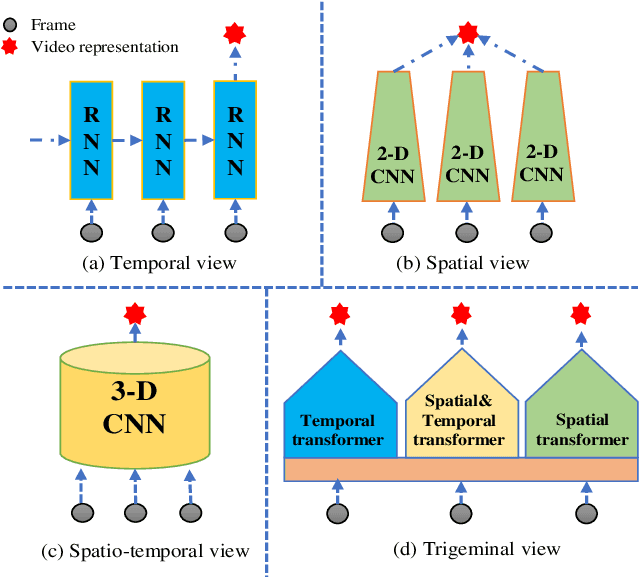
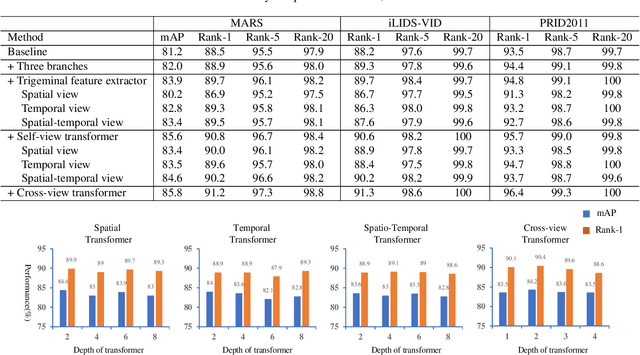
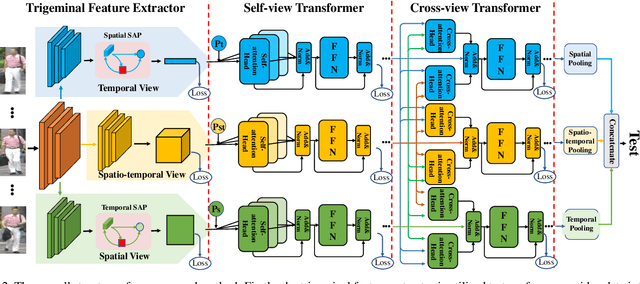
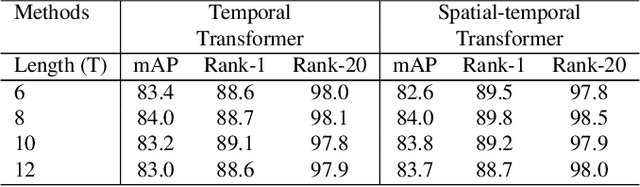
Video-based person re-identification (Re-ID) aims to retrieve video sequences of the same person under non-overlapping cameras. Previous methods usually focus on limited views, such as spatial, temporal or spatial-temporal view, which lack of the observations in different feature domains. To capture richer perceptions and extract more comprehensive video representations, in this paper we propose a novel framework named Trigeminal Transformers (TMT) for video-based person Re-ID. More specifically, we design a trigeminal feature extractor to jointly transform raw video data into spatial, temporal and spatial-temporal domain. Besides, inspired by the great success of vision transformer, we introduce the transformer structure for video-based person Re-ID. In our work, three self-view transformers are proposed to exploit the relationships between local features for information enhancement in spatial, temporal and spatial-temporal domains. Moreover, a cross-view transformer is proposed to aggregate the multi-view features for comprehensive video representations. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches on public Re-ID benchmarks. We will release the code for model reproduction.