 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing the Unknown: Interpretable Open-World Object Detection via Concept Decomposition Model
Feb 24, 2026Open-world object detection (OWOD) requires incrementally detecting known categories while reliably identifying unknown objects. Existing methods primarily focus on improving unknown recall, yet overlook interpretability, often leading to known-unknown confusion and reduced prediction reliability. This paper aims to make the entire OWOD framework interpretable, enabling the detector to truly "knowing the unknown". To this end, we propose a concept-driven InterPretable OWOD framework(IPOW) by introducing a Concept Decomposition Model (CDM) for OWOD, which explicitly decomposes the coupled RoI features in Faster R-CNN into discriminative, shared, and background concepts. Discriminative concepts identify the most discriminative features to enlarge the distances between known categories, while shared and background concepts, due to their strong generalization ability, can be readily transferred to detect unknown categories. Leveraging the interpretable framework, we identify that known-unknown confusion arises when unknown objects fall into the discriminative space of known classes. To address this, we propose Concept-Guided Rectification (CGR) to further resolve such confusion. Extensive experiments show that IPOW significantly improves unknown recall while mitigating confusion, and provides concept-level interpretability for both known and unknown predictions.
YOLO-IOD: Towards Real Time Incremental Object Detection
Dec 28, 2025Current methods for incremental object detection (IOD) primarily rely on Faster R-CNN or DETR series detectors; however, these approaches do not accommodate the real-time YOLO detection frameworks. In this paper, we first identify three primary types of knowledge conflicts that contribute to catastrophic forgetting in YOLO-based incremental detectors: foreground-background confusion, parameter interference, and misaligned knowledge distillation. Subsequently, we introduce YOLO-IOD, a real-time Incremental Object Detection (IOD) framework that is constructed upon the pretrained YOLO-World model, facilitating incremental learning via a stage-wise parameter-efficient fine-tuning process. Specifically, YOLO-IOD encompasses three principal components: 1) Conflict-Aware Pseudo-Label Refinement (CPR), which mitigates the foreground-background confusion by leveraging the confidence levels of pseudo labels and identifying potential objects relevant to future tasks. 2) Importancebased Kernel Selection (IKS), which identifies and updates the pivotal convolution kernels pertinent to the current task during the current learning stage. 3) Cross-Stage Asymmetric Knowledge Distillation (CAKD), which addresses the misaligned knowledge distillation conflict by transmitting the features of the student target detector through the detection heads of both the previous and current teacher detectors, thereby facilitating asymmetric distillation between existing and newly introduced categories. We further introduce LoCo COCO, a more realistic benchmark that eliminates data leakage across stages. Experiments on both conventional and LoCo COCO benchmarks show that YOLO-IOD achieves superior performance with minimal forgetting.
Improving Word Vector with Prior Knowledge in Semantic Dictionary
Jan 27, 2018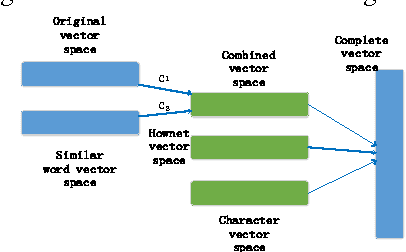

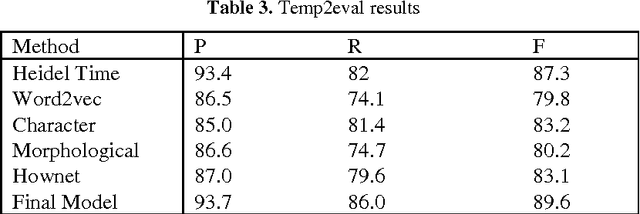
Using low dimensional vector space to represent words has been very effective in many NLP tasks. However, it doesn't work well when faced with the problem of rare and unseen words. In this paper, we propose to leverage the knowledge in semantic dictionary in combination with some morphological information to build an enhanced vector space. We get an improvement of 2.3% over the state-of-the-art Heidel Time system in temporal expression recognition, and obtain a large gain in other name entity recognition (NER) tasks. The semantic dictionary Hownet alone also shows promising results in computing lexical similarity.