 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Localized Adversarial Examples: A Generic Approach using Critical Region Analysis
Feb 14, 2021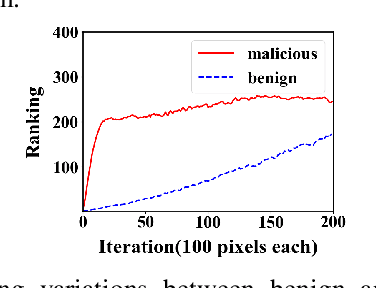
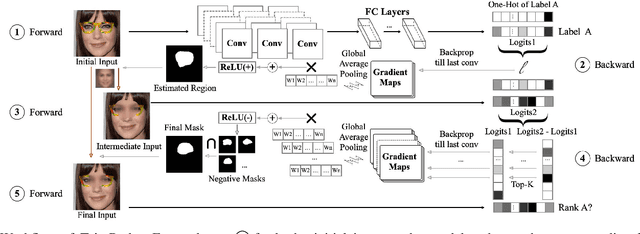
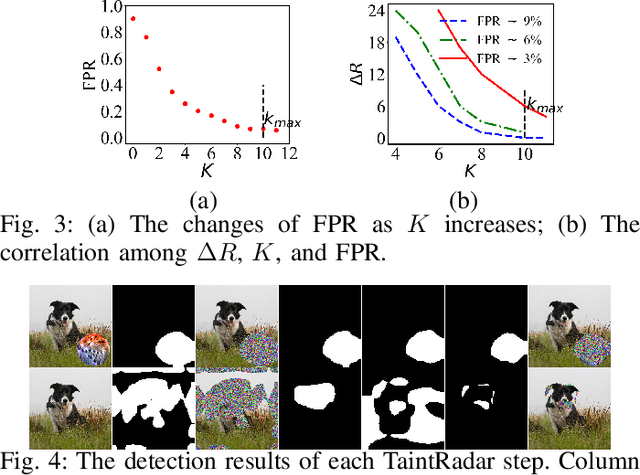
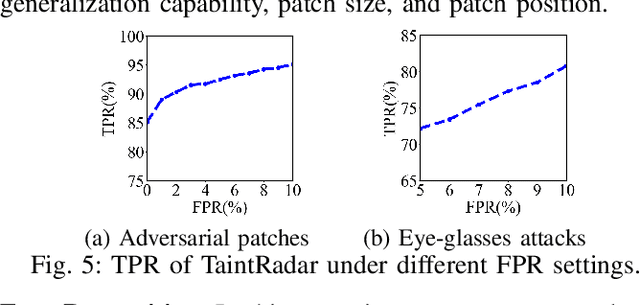
Deep neural networks (DNNs) have been applied in a wide range of applications,e.g.,face recognition and image classification; however,they are vulnerable to adversarial examples. By adding a small amount of imperceptible perturbations,an attacker can easily manipulate the outputs of a DNN. Particularly,the localized adversarial examples only perturb a small and contiguous region of the target object,so that they are robust and effective in both digital and physical worlds. Although the localized adversarial examples have more severe real-world impacts than traditional pixel attacks,they have not been well addressed in the literature. In this paper,we propose a generic defense system called TaintRadar to accurately detect localized adversarial examples via analyzing critical regions that have been manipulated by attackers. The main idea is that when removing critical regions from input images,the ranking changes of adversarial labels will be larger than those of benign labels. Compared with existing defense solutions,TaintRadar can effectively capture sophisticated localized partial attacks, e.g.,the eye-glasses attack,while not requiring additional training or fine-tuning of the original model's structure. Comprehensive experiments have been conducted in both digital and physical worlds to verify the effectiveness and robustness of our defense.
Removing Backdoor-Based Watermarks in Neural Networks with Limited Data
Aug 08, 2020
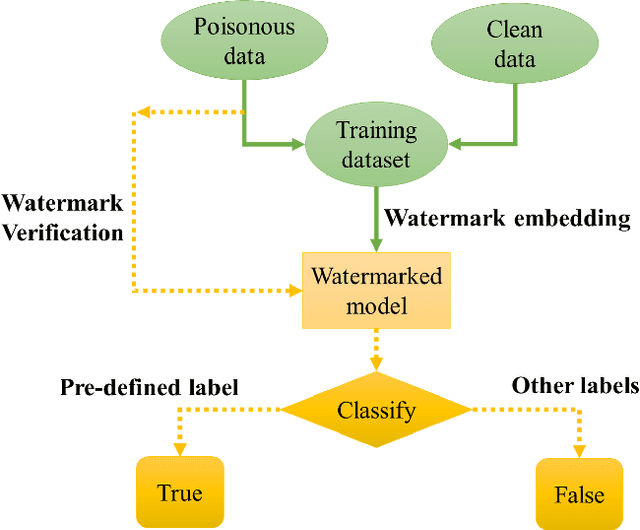

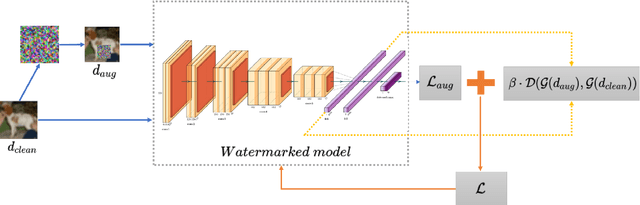
Deep neural networks have been widely applied and achieved great success in various fields. As training deep models usually consumes massive data and computational resources, trading the trained deep models is highly demanded and lucrative nowadays. Unfortunately, the naive trading schemes typically involves potential risks related to copyright and trustworthiness issues, e.g., a sold model can be illegally resold to others without further authorization to reap huge profits. To tackle this problem, various watermarking techniques are proposed to protect the model intellectual property, amongst which the backdoor-based watermarking is the most commonly-used one. However, the robustness of these watermarking approaches is not well evaluated under realistic settings, such as limited in-distribution data availability and agnostic of watermarking patterns. In this paper, we benchmark the robustness of watermarking, and propose a novel backdoor-based watermark removal framework using limited data, dubbed WILD. The proposed WILD removes the watermarks of deep models with only a small portion of training data, and the output model can perform the same as models trained from scratch without watermarks injected. In particular, a novel data augmentation method is utilized to mimic the behavior of watermark triggers. Combining with the distribution alignment between the normal and perturbed (e.g., occluded) data in the feature space, our approach generalizes well on all typical types of trigger contents. The experimental results demonstrate that our approach can effectively remove the watermarks without compromising the deep model performance for the original task with the limited access to training data.