 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechJudge: Towards Human-Level Judgment for Speech Naturalness
Nov 11, 2025



Aligning large generative models with human feedback is a critical challenge. In speech synthesis, this is particularly pronounced due to the lack of a large-scale human preference dataset, which hinders the development of models that truly align with human perception. To address this, we introduce SpeechJudge, a comprehensive suite comprising a dataset, a benchmark, and a reward model centered on naturalness--one of the most fundamental subjective metrics for speech synthesis. First, we present SpeechJudge-Data, a large-scale human feedback corpus of 99K speech pairs. The dataset is constructed using a diverse set of advanced zero-shot text-to-speech (TTS) models across diverse speech styles and multiple languages, with human annotations for both intelligibility and naturalness preference. From this, we establish SpeechJudge-Eval, a challenging benchmark for speech naturalness judgment. Our evaluation reveals that existing metrics and AudioLLMs struggle with this task; the leading model, Gemini-2.5-Flash, achieves less than 70% agreement with human judgment, highlighting a significant gap for improvement. To bridge this gap, we develop SpeechJudge-GRM, a generative reward model (GRM) based on Qwen2.5-Omni-7B. It is trained on SpeechJudge-Data via a two-stage post-training process: Supervised Fine-Tuning (SFT) with Chain-of-Thought rationales followed by Reinforcement Learning (RL) with GRPO on challenging cases. On the SpeechJudge-Eval benchmark, the proposed SpeechJudge-GRM demonstrates superior performance, achieving 77.2% accuracy (and 79.4% after inference-time scaling @10) compared to a classic Bradley-Terry reward model (72.7%). Furthermore, SpeechJudge-GRM can be also employed as a reward function during the post-training of speech generation models to facilitate their alignment with human preferences.
An End-to-end Chinese Text Normalization Model based on Rule-guided Flat-Lattice Transformer
Mar 31, 2022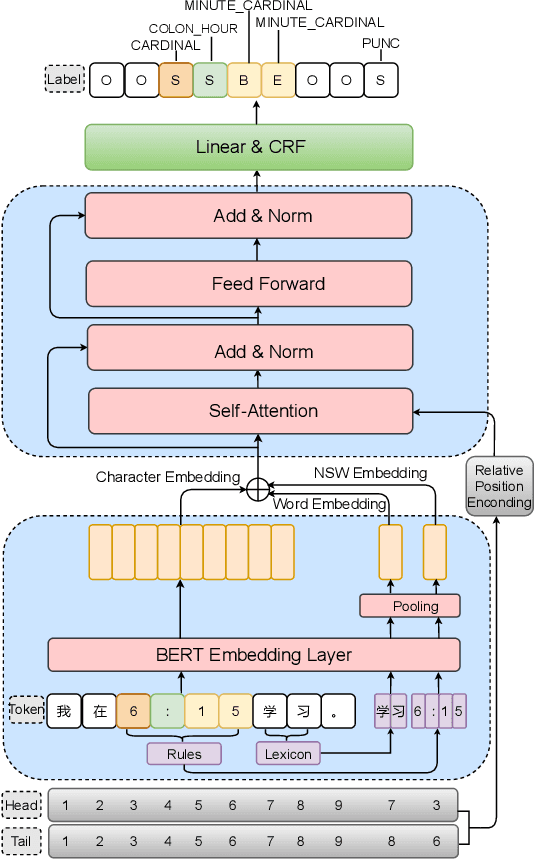
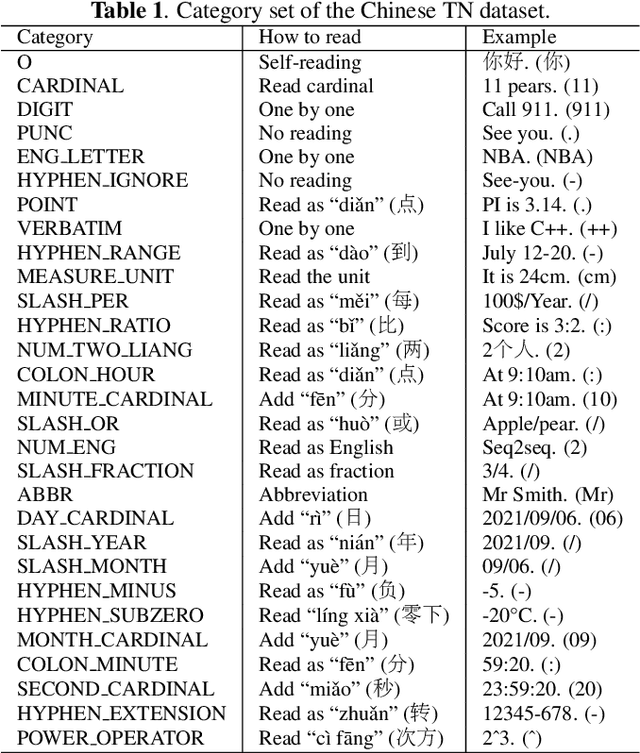
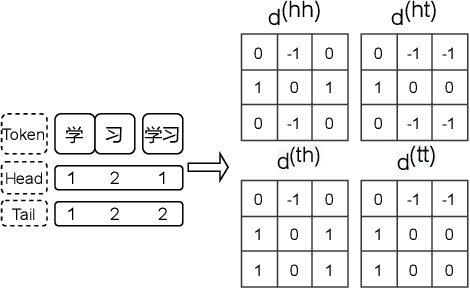
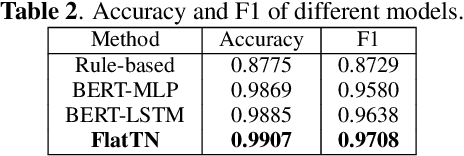
Text normalization, defined as a procedure transforming non standard words to spoken-form words, is crucial to the intelligibility of synthesized speech in text-to-speech system. Rule-based methods without considering context can not eliminate ambiguation, whereas sequence-to-sequence neural network based methods suffer from the unexpected and uninterpretable errors problem. Recently proposed hybrid system treats rule-based model and neural model as two cascaded sub-modules, where limited interaction capability makes neural network model cannot fully utilize expert knowledge contained in the rules. Inspired by Flat-LAttice Transformer (FLAT), we propose an end-to-end Chinese text normalization model, which accepts Chinese characters as direct input and integrates expert knowledge contained in rules into the neural network, both contribute to the superior performance of proposed model for the text normalization task. We also release a first publicly accessible largescale dataset for Chinese text normalization. Our proposed model has achieved excellent results on this dataset.