 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic High-frequency Convolution for Infrared Small Target Detection
Feb 03, 2026Infrared small targets are typically tiny and locally salient, which belong to high-frequency components (HFCs) in images. Single-frame infrared small target (SIRST) detection is challenging, since there are many HFCs along with targets, such as bright corners, broken clouds, and other clutters. Current learning-based methods rely on the powerful capabilities of deep networks, but neglect explicit modeling and discriminative representation learning of various HFCs, which is important to distinguish targets from other HFCs. To address the aforementioned issues, we propose a dynamic high-frequency convolution (DHiF) to translate the discriminative modeling process into the generation of a dynamic local filter bank. Especially, DHiF is sensitive to HFCs, owing to the dynamic parameters of its generated filters being symmetrically adjusted within a zero-centered range according to Fourier transformation properties. Combining with standard convolution operations, DHiF can adaptively and dynamically process different HFC regions and capture their distinctive grayscale variation characteristics for discriminative representation learning. DHiF functions as a drop-in replacement for standard convolution and can be used in arbitrary SIRST detection networks without significant decrease in computational efficiency. To validate the effectiveness of our DHiF, we conducted extensive experiments across different SIRST detection networks on real-scene datasets. Compared to other state-of-the-art convolution operations, DHiF exhibits superior detection performance with promising improvement. Codes are available at https://github.com/TinaLRJ/DHiF.
Probing Deep into Temporal Profile Makes the Infrared Small Target Detector Much Better
Jun 15, 2025Infrared small target (IRST) detection is challenging in simultaneously achieving precise, universal, robust and efficient performance due to extremely dim targets and strong interference. Current learning-based methods attempt to leverage ``more" information from both the spatial and the short-term temporal domains, but suffer from unreliable performance under complex conditions while incurring computational redundancy. In this paper, we explore the ``more essential" information from a more crucial domain for the detection. Through theoretical analysis, we reveal that the global temporal saliency and correlation information in the temporal profile demonstrate significant superiority in distinguishing target signals from other signals. To investigate whether such superiority is preferentially leveraged by well-trained networks, we built the first prediction attribution tool in this field and verified the importance of the temporal profile information. Inspired by the above conclusions, we remodel the IRST detection task as a one-dimensional signal anomaly detection task, and propose an efficient deep temporal probe network (DeepPro) that only performs calculations in the time dimension for IRST detection. We conducted extensive experiments to fully validate the effectiveness of our method. The experimental results are exciting, as our DeepPro outperforms existing state-of-the-art IRST detection methods on widely-used benchmarks with extremely high efficiency, and achieves a significant improvement on dim targets and in complex scenarios. We provide a new modeling domain, a new insight, a new method, and a new performance, which can promote the development of IRST detection. Codes are available at https://github.com/TinaLRJ/DeepPro.
The First Competition on Resource-Limited Infrared Small Target Detection Challenge: Methods and Results
Aug 18, 2024In this paper, we briefly summarize the first competition on resource-limited infrared small target detection (namely, LimitIRSTD). This competition has two tracks, including weakly-supervised infrared small target detection (Track 1) and lightweight infrared small target detection (Track 2). 46 and 60 teams successfully registered and took part in Tracks 1 and Track 2, respectively. The top-performing methods and their results in each track are described with details. This competition inspires the community to explore the tough problems in the application of infrared small target detection, and ultimately promote the deployment of this technology under limited resource.
Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
Apr 04, 2023



Training a convolutional neural network (CNN) to detect infrared small targets in a fully supervised manner has gained remarkable research interests in recent years, but is highly labor expensive since a large number of per-pixel annotations are required. To handle this problem, in this paper, we make the first attempt to achieve infrared small target detection with point-level supervision. Interestingly, during the training phase supervised by point labels, we discover that CNNs first learn to segment a cluster of pixels near the targets, and then gradually converge to predict groundtruth point labels. Motivated by this "mapping degeneration" phenomenon, we propose a label evolution framework named label evolution with single point supervision (LESPS) to progressively expand the point label by leveraging the intermediate predictions of CNNs. In this way, the network predictions can finally approximate the updated pseudo labels, and a pixel-level target mask can be obtained to train CNNs in an end-to-end manner. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Experimental results show that CNNs equipped with LESPS can well recover the target masks from corresponding point labels, {and can achieve over 70% and 95% of their fully supervised performance in terms of pixel-level intersection over union (IoU) and object-level probability of detection (Pd), respectively. Code is available at https://github.com/XinyiYing/LESPS.
MoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022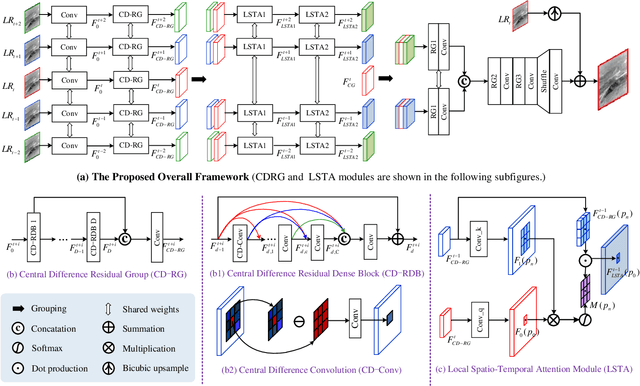
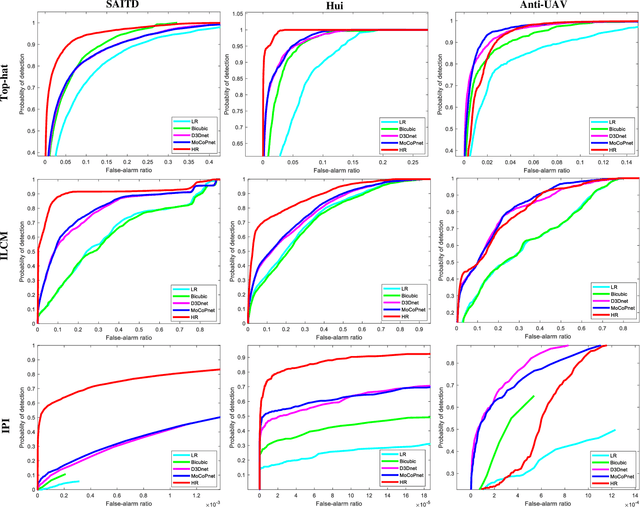

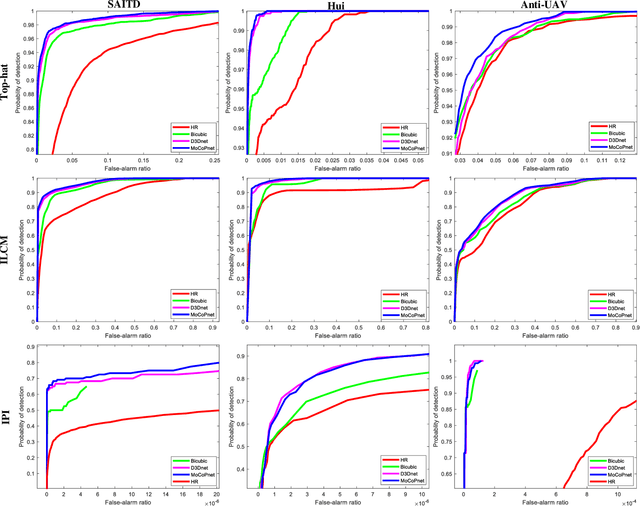
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
Symmetric Parallax Attention for Stereo Image Super-Resolution
Nov 07, 2020

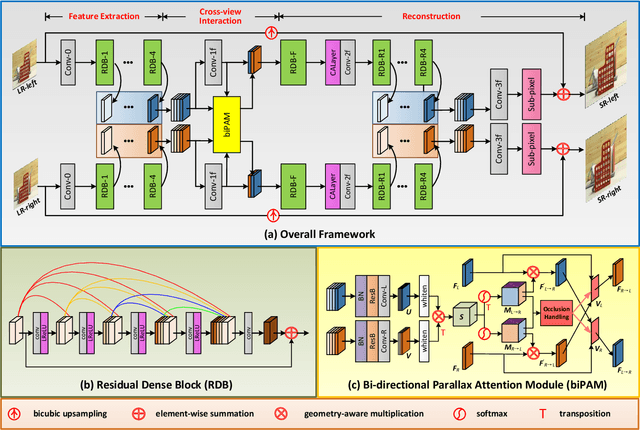
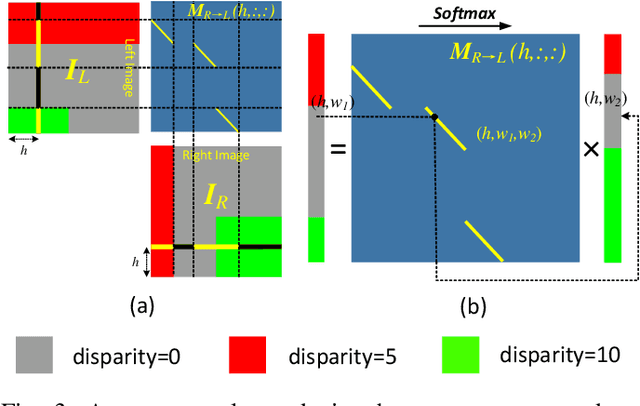
Although recent years have witnessed the great advances in stereo image super-resolution (SR), the beneficial information provided by binocular systems has not been fully used. Since stereo images are highly symmetric under epipolar constraint, in this paper, we improve the performance of stereo image SR by exploiting symmetry cues in stereo image pairs. Specifically, we propose a symmetric bi-directional parallax attention module (biPAM) and an inline occlusion handling scheme to effectively interact cross-view information. Then, we design a Siamese network equipped with a biPAM to super-resolve both sides of views in a highly symmetric manner. Finally, we design several illuminance-robust bilateral losses to enforce stereo consistency. Experiments on four public datasets have demonstrated the superiority of our method. As compared to PASSRnet, our method achieves notable performance improvements with a comparable model size. Source codes are available at https://github.com/YingqianWang/iPASSR.
Light Field Image Super-Resolution Using Deformable Convolution
Jul 07, 2020
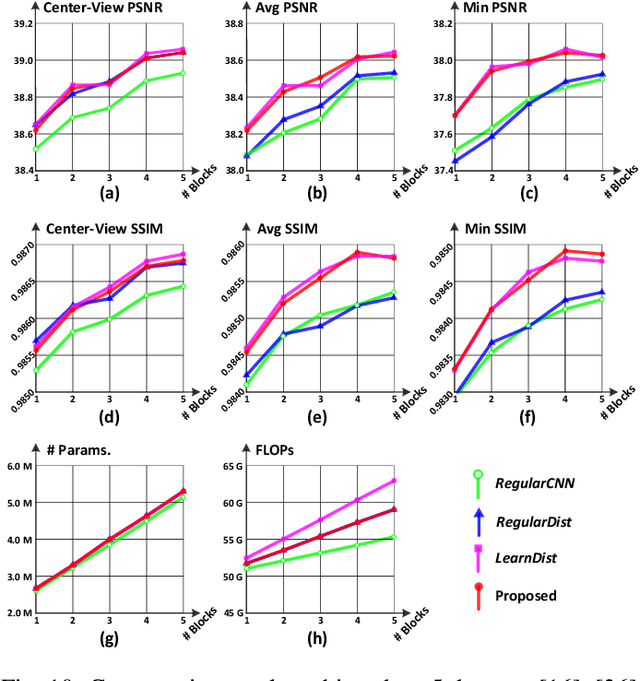
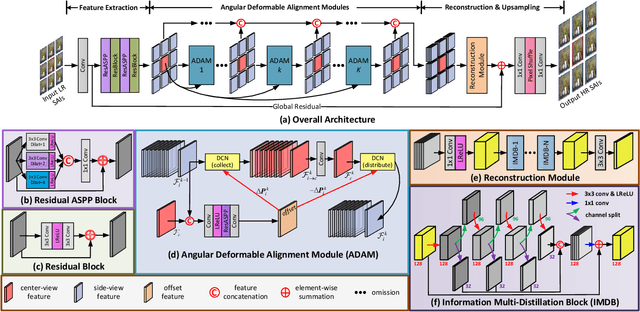

Light field (LF) cameras can record scenes from multiple perspectives, and thus introduce beneficial angular information for image super-resolution (SR). However, it is challenging to incorporate angular information due to disparities among LF images. In this paper, we propose a deformable convolution network (i.e., LF-DFnet) to handle the disparity problem for LF image SR. Specifically, we design an angular deformable alignment module (ADAM) for feature-level alignment. Based on ADAM, we further propose a collect-and-distribute approach to perform bidirectional alignment between the center-view feature and each side-view feature. Using our approach, angular information can be well incorporated and encoded into features of each view, which benefits the SR reconstruction of all LF images. Moreover, we develop a baseline-adjustable LF dataset to evaluate SR performance under different disparities. Experiments on both public and our self-developed datasets have demonstrated the superiority of our method. Our LF-DFnet can generate high-resolution images with more faithful details and achieve state-of-the-art reconstruction accuracy. Besides, our LF-DFnet is more robust to disparity variations, which has not been well addressed in literature.
Learning Sparse Masks for Efficient Image Super-Resolution
Jun 17, 2020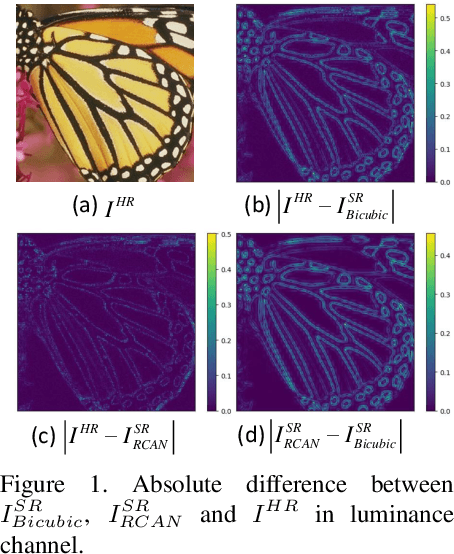
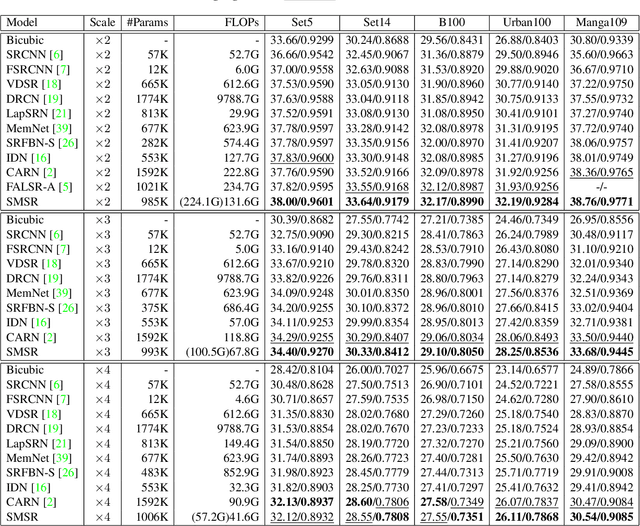
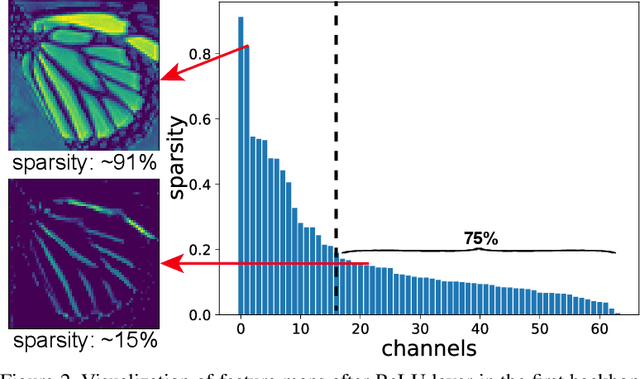

Current CNN-based super-resolution (SR) methods process all locations equally with computational resources being uniformly assigned in space. However, since highfrequency details mainly lie around edges and textures, less computational resources are required for those flat regions. Therefore, existing CNN-based methods involve much redundant computation in flat regions, which increases their computational cost and limits the applications on mobile devices. To address this limitation, we develop an SR network (SMSR) to learn sparse masks to prune redundant computation conditioned on the input image. Within our SMSR, spatial masks learn to identify "important" locations while channel masks learn to mark redundant channels in those "unimportant" regions. Consequently, redundant computation can be accurately located and skipped while maintaining comparable performance. It is demonstrated that our SMSR achieves state-of-the-art performance with 41%/33%/27% FLOPs being reduced for x2/3/4 SR.
Deformable 3D Convolution for Video Super-Resolution
Apr 06, 2020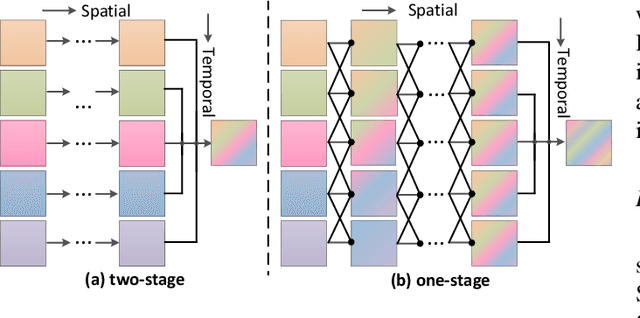
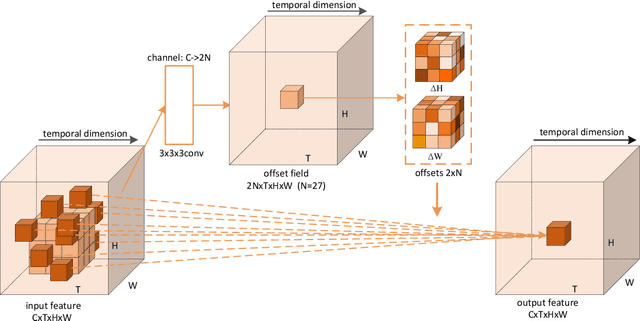
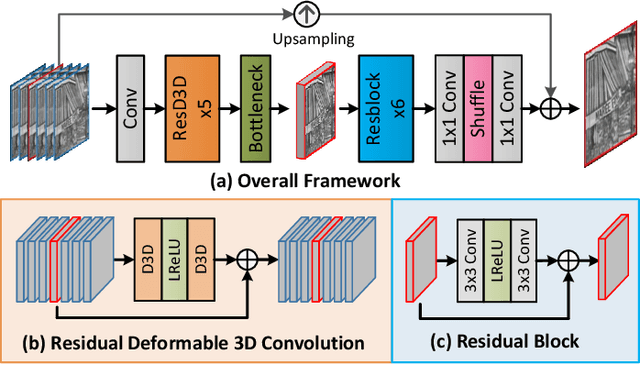
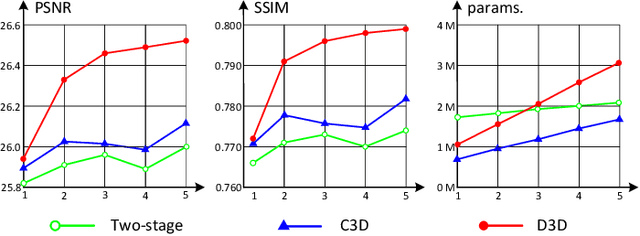
The spatio-temporal information among video sequences is significant for video super-resolution (SR). However, the spatio-temporal information cannot be fully used by existing video SR methods since spatial feature extraction and temporal motion compensation are usually performed sequentially. In this paper, we propose a deformable 3D convolution network (D3Dnet) to incorporate spatio-temporal information from both spatial and temporal dimensions for video SR. Specifically, we introduce deformable 3D convolutions (D3D) to integrate 2D spatial deformable convolutions with 3D convolutions (C3D), obtaining both superior spatio-temporal modeling capability and motion-aware modeling flexibility. Extensive experiments have demonstrated the effectiveness of our proposed D3D in exploiting spatio-temporal information. Comparative results show that our network outperforms the state-of-the-art methods. Code is available at: https://github.com/XinyiYing/D3Dnet.