 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning under latent space model
Sep 19, 2025Latent space model plays a crucial role in network analysis, and accurate estimation of latent variables is essential for downstream tasks such as link prediction. However, the large number of parameters to be estimated presents a challenge, especially when the latent space dimension is not exceptionally small. In this paper, we propose a transfer learning method that leverages information from networks with latent variables similar to those in the target network, thereby improving the estimation accuracy for the target. Given transferable source networks, we introduce a two-stage transfer learning algorithm that accommodates differences in node numbers between source and target networks. In each stage, we derive sufficient identification conditions and design tailored projected gradient descent algorithms for estimation. Theoretical properties of the resulting estimators are established. When the transferable networks are unknown, a detection algorithm is introduced to identify suitable source networks. Simulation studies and analyses of two real datasets demonstrate the effectiveness of the proposed methods.
RecBole 2.0: Towards a More Up-to-Date Recommendation Library
Jun 16, 2022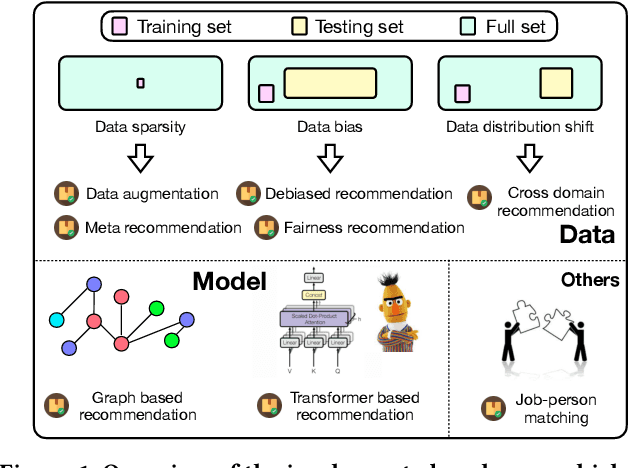
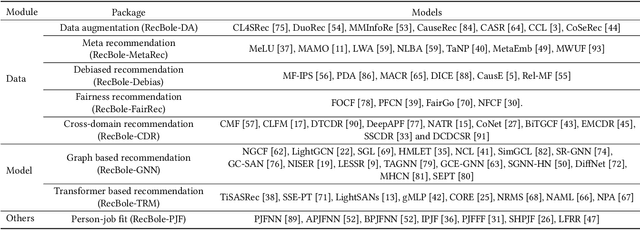

In order to support the study of recent advances in recommender systems, this paper presents an extended recommendation library consisting of eight packages for up-to-date topics and architectures. First of all, from a data perspective, we consider three important topics related to data issues (i.e., sparsity, bias and distribution shift), and develop five packages accordingly: meta-learning, data augmentation, debiasing, fairness and cross-domain recommendation. Furthermore, from a model perspective, we develop two benchmarking packages for Transformer-based and graph neural network (GNN)-based models, respectively. All the packages (consisting of 65 new models) are developed based on a popular recommendation framework RecBole, ensuring that both the implementation and interface are unified. For each package, we provide complete implementations from data loading, experimental setup, evaluation and algorithm implementation. This library provides a valuable resource to facilitate the up-to-date research in recommender systems. The project is released at the link: https://github.com/RUCAIBox/RecBole2.0.
Ada-Ranker: A Data Distribution Adaptive Ranking Paradigm for Sequential Recommendation
May 22, 2022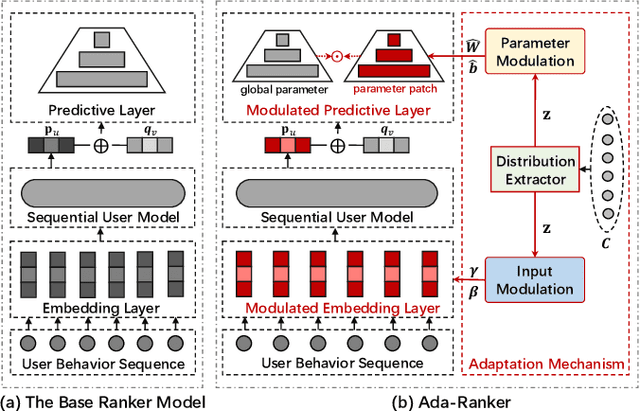
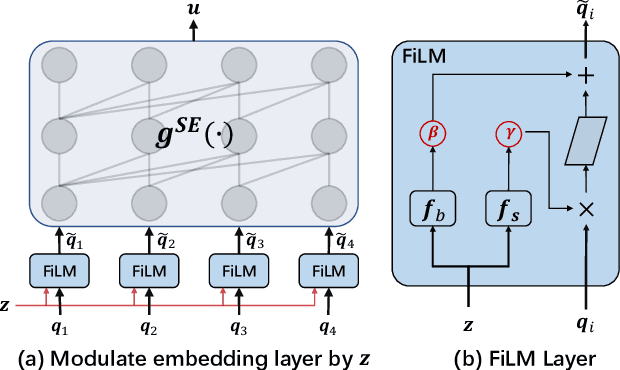
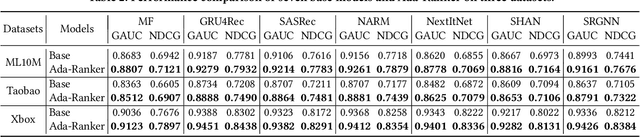
A large-scale recommender system usually consists of recall and ranking modules. The goal of ranking modules (aka rankers) is to elaborately discriminate users' preference on item candidates proposed by recall modules. With the success of deep learning techniques in various domains, we have witnessed the mainstream rankers evolve from traditional models to deep neural models. However, the way that we design and use rankers remains unchanged: offline training the model, freezing the parameters, and deploying it for online serving. Actually, the candidate items are determined by specific user requests, in which underlying distributions (e.g., the proportion of items for different categories, the proportion of popular or new items) are highly different from one another in a production environment. The classical parameter-frozen inference manner cannot adapt to dynamic serving circumstances, making rankers' performance compromised. In this paper, we propose a new training and inference paradigm, termed as Ada-Ranker, to address the challenges of dynamic online serving. Instead of using parameter-frozen models for universal serving, Ada-Ranker can adaptively modulate parameters of a ranker according to the data distribution of the current group of item candidates. We first extract distribution patterns from the item candidates. Then, we modulate the ranker by the patterns to make the ranker adapt to the current data distribution. Finally, we use the revised ranker to score the candidate list. In this way, we empower the ranker with the capacity of adapting from a global model to a local model which better handles the current task.