 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech2Video: Cross-Modal Distillation for Speech to Video Generation
Jul 10, 2021
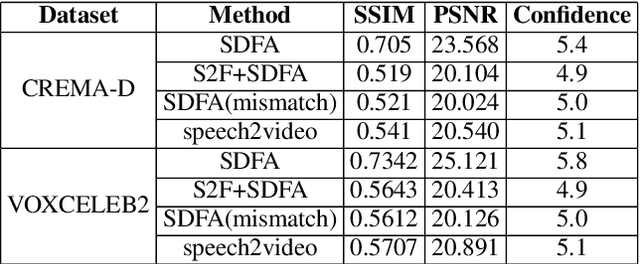
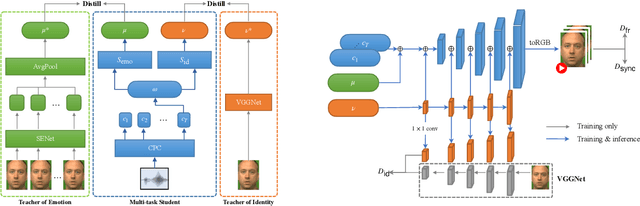
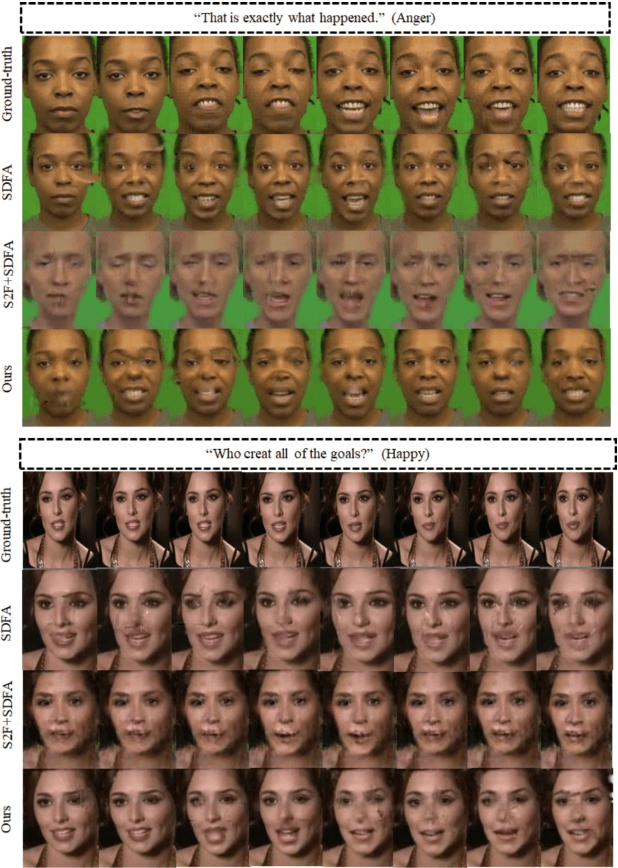
This paper investigates a novel task of talking face video generation solely from speeches. The speech-to-video generation technique can spark interesting applications in entertainment, customer service, and human-computer-interaction industries. Indeed, the timbre, accent and speed in speeches could contain rich information relevant to speakers' appearance. The challenge mainly lies in disentangling the distinct visual attributes from audio signals. In this article, we propose a light-weight, cross-modal distillation method to extract disentangled emotional and identity information from unlabelled video inputs. The extracted features are then integrated by a generative adversarial network into talking face video clips. With carefully crafted discriminators, the proposed framework achieves realistic generation results. Experiments with observed individuals demonstrated that the proposed framework captures the emotional expressions solely from speeches, and produces spontaneous facial motion in the video output. Compared to the baseline method where speeches are combined with a static image of the speaker, the results of the proposed framework is almost indistinguishable. User studies also show that the proposed method outperforms the existing algorithms in terms of emotion expression in the generated videos.
Efficient Client Contribution Evaluation for Horizontal Federated Learning
Feb 26, 2021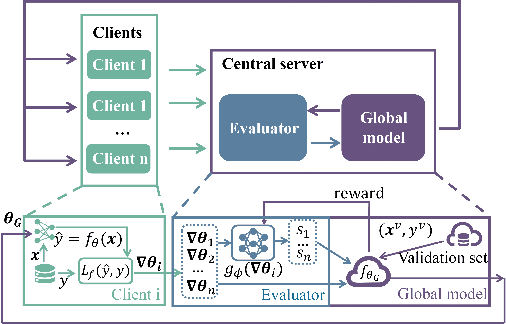

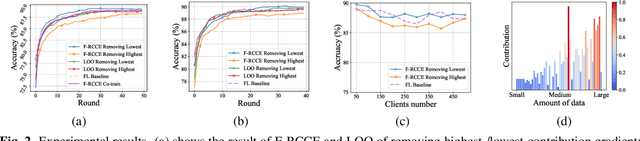
In federated learning (FL), fair and accurate measurement of the contribution of each federated participant is of great significance. The level of contribution not only provides a rational metric for distributing financial benefits among federated participants, but also helps to discover malicious participants that try to poison the FL framework. Previous methods for contribution measurement were based on enumeration over possible combination of federated participants. Their computation costs increase drastically with the number of participants or feature dimensions, making them inapplicable in practical situations. In this paper an efficient method is proposed to evaluate the contributions of federated participants. This paper focuses on the horizontal FL framework, where client servers calculate parameter gradients over their local data, and upload the gradients to the central server. Before aggregating the client gradients, the central server train a data value estimator of the gradients using reinforcement learning techniques. As shown by experimental results, the proposed method consistently outperforms the conventional leave-one-out method in terms of valuation authenticity as well as time complexity.
A Quantitative Metric for Privacy Leakage in Federated Learning
Feb 24, 2021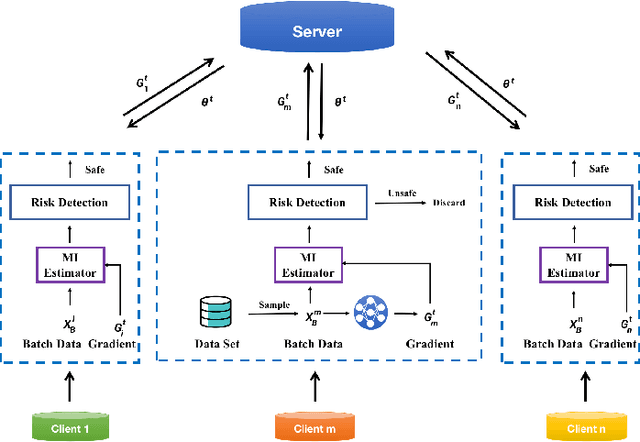
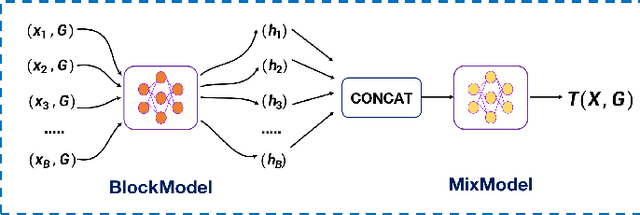
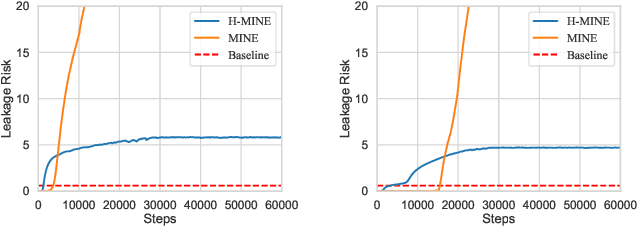
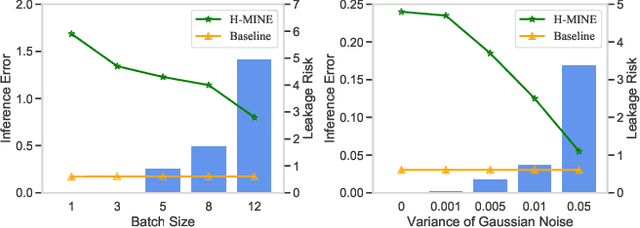
In the federated learning system, parameter gradients are shared among participants and the central modulator, while the original data never leave their protected source domain. However, the gradient itself might carry enough information for precise inference of the original data. By reporting their parameter gradients to the central server, client datasets are exposed to inference attacks from adversaries. In this paper, we propose a quantitative metric based on mutual information for clients to evaluate the potential risk of information leakage in their gradients. Mutual information has received increasing attention in the machine learning and data mining community over the past few years. However, existing mutual information estimation methods cannot handle high-dimensional variables. In this paper, we propose a novel method to approximate the mutual information between the high-dimensional gradients and batched input data. Experimental results show that the proposed metric reliably reflect the extent of information leakage in federated learning. In addition, using the proposed metric, we investigate the influential factors of risk level. It is proven that, the risk of information leakage is related to the status of the task model, as well as the inherent data distribution.