 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQA-Spider: Unifying Multi-Granularity Image Quality Assessment with Reasoning, Grounding and Referring
May 23, 2026We present IQA-Spider, the first image quality assessment (IQA) framework that unifies reasoning, grounding, and referring into a single LMM-based framework for multi-granularity quality understanding. Existing LMM-based IQA methods typically support only partial perception dimensions, such as quality description and question answering~(\textit{i.e.}, reasoning) or pixel-level grounding. This limitation largely stems from the absence of (i) a unified task and data formulation and (ii) effective optimization paradigms for multi-granularity learning. To address these limitations, we formulate a rigorous four-task paradigm covering global and local quality description, pixel-level grounding, and region-level referring. Based on this formulation, we construct a corresponding IQA dataset with a scalable and automatic annotation pipeline, thereby providing a solid foundation for unified multi-granularity learning. To further enable unified perception, we adopt a conflict-free two-stage design that progressively extends text-level multi-granularity understanding to pixel-level grounding: (i) the first stage equips the model with fine-grained text-level reasoning across multiple IQA tasks, and (ii) the second stage introduces a training-free text-to-point grounding paradigm, which bridges textual semantics and pixel-level perception by mapping token logits to spatial coordinates. Based on these efforts, we achieve IQA-Spider with unified multi-granularity explainable image quality assessment. Extensive experiments across multiple benchmarks demonstrate strong performance, validating the effectiveness and versatility of the proposed formulation and framework.
Repetitive Action Counting with Hybrid Temporal Relation Modeling
Dec 10, 2024



Repetitive Action Counting (RAC) aims to count the number of repetitive actions occurring in videos. In the real world, repetitive actions have great diversity and bring numerous challenges (e.g., viewpoint changes, non-uniform periods, and action interruptions). Existing methods based on the temporal self-similarity matrix (TSSM) for RAC are trapped in the bottleneck of insufficient capturing action periods when applied to complicated daily videos. To tackle this issue, we propose a novel method named Hybrid Temporal Relation Modeling Network (HTRM-Net) to build diverse TSSM for RAC. The HTRM-Net mainly consists of three key components: bi-modal temporal self-similarity matrix modeling, random matrix dropping, and local temporal context modeling. Specifically, we construct temporal self-similarity matrices by bi-modal (self-attention and dual-softmax) operations, yielding diverse matrix representations from the combination of row-wise and column-wise correlations. To further enhance matrix representations, we propose incorporating a random matrix dropping module to guide channel-wise learning of the matrix explicitly. After that, we inject the local temporal context of video frames and the learned matrix into temporal correlation modeling, which can make the model robust enough to cope with error-prone situations, such as action interruption. Finally, a multi-scale matrix fusion module is designed to aggregate temporal correlations adaptively in multi-scale matrices. Extensive experiments across intra- and cross-datasets demonstrate that the proposed method not only outperforms current state-of-the-art methods but also exhibits robust capabilities in accurately counting repetitive actions in unseen action categories. Notably, our method surpasses the classical TransRAC method by 20.04\% in MAE and 22.76\% in OBO.
Joint Skeletal and Semantic Embedding Loss for Micro-gesture Classification
Jul 20, 2023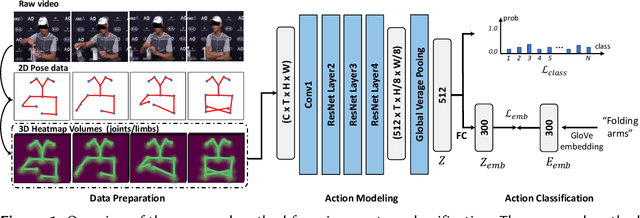

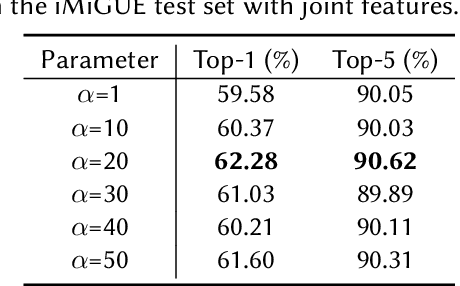
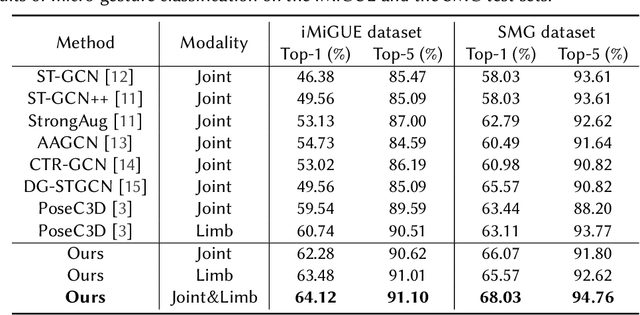
In this paper, we briefly introduce the solution of our team HFUT-VUT for the Micros-gesture Classification in the MiGA challenge at IJCAI 2023. The micro-gesture classification task aims at recognizing the action category of a given video based on the skeleton data. For this task, we propose a 3D-CNNs-based micro-gesture recognition network, which incorporates a skeletal and semantic embedding loss to improve action classification performance. Finally, we rank 1st in the Micro-gesture Classification Challenge, surpassing the second-place team in terms of Top-1 accuracy by 1.10%.