 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Adaptive Dimension Reduction for Bayesian Inference in Inverse Problems
May 28, 2026Solving high-dimensional PDE-governed inverse problems is often challenging due to complex non-Gaussian posterior distributions, expensive forward model evaluations, and misspecified prior information. To address these issues, we propose a deep adaptive dimension-reduction Bayesian inference framework based on the Variational Flow (VF) model. Since standard normalizing flows are restricted by bijective mappings and cannot directly reduce dimensions, VF overcomes this limitation by integrating VAE-based nonlinear dimension reduction with dual normalizing flows for the latent prior and encoder. This design provides a strictly higher evidence lower bound than VAE and allows more flexible approximation of complex posterior distributions. We further introduce an iterative prior updating strategy that gradually moves the prior mean toward high-probability posterior regions, avoiding manual prior tuning. These components form a closed adaptive loop together with an adaptively fine-tuned Fourier Neural Operator (FNO) surrogate: VF generates posterior-concentrated samples to refine the surrogate, while the updated surrogate further improves posterior inference. Numerical experiments on a 100-dimensional Rosenbrock problem and three standard PDE-governed inverse problems show that our method delivers competitive or superior accuracy compared with MCMC, UKI, and SVGD baselines across all tested configurations, with the most pronounced advantages emerging in challenging scenarios such as high-noise observations and high-dimensional parameter spaces.
How Should LLMs Consume High-Quality Data? Optimal Data Scheduling via Quality-Aware Functional Scaling Laws
May 25, 2026High-quality data is scarce in large language model (LLM) training, yet how to schedule its use jointly with training dynamics lacks theoretical guidance. We extend functional scaling laws by incorporating a data-quality dimension, and solve the joint data-quality and batch-size scheduling problem in asymptotic closed form. The solution reveals two regimes and a dual role of high-quality data. In the noise-limited regime, high-quality data should be used as a signal amplifier: lowering the batch size converts cleaner data into more signal without amplifying noise. In the signal-limited regime, it should be used as a noise suppressor: late placement reduces terminal noise without sacrificing signal accumulation. Existing curriculum-style pipelines primarily exploit the second role by placing cleaner data late, but miss the first role because conventional decay schedules reduce update intensity exactly when high-quality data becomes available. Guided by this, we propose Drop-Stable-Rampup for LLM midtraining: upon the quality transition, drop the batch size, hold it stable to accumulate signal, then ramp up to suppress terminal noise. On a 15B Mixture-of-Experts model midtrained on 108B tokens, Drop-Stable-Rampup improves average accuracy over Warmup-Stable-Decay (WSD) by +1.70 and over Cosine-decay by +2.98, with particularly large gains on mathematical reasoning benchmarks such as GSM8K (+4.23) and MATH (+2.80).
HE-SNR: Uncovering Latent Logic via Entropy for Guiding Mid-Training on SWE-BENCH
Jan 28, 2026SWE-bench has emerged as the premier benchmark for evaluating Large Language Models on complex software engineering tasks. While these capabilities are fundamentally acquired during the mid-training phase and subsequently elicited during Supervised Fine-Tuning (SFT), there remains a critical deficit in metrics capable of guiding mid-training effectively. Standard metrics such as Perplexity (PPL) are compromised by the "Long-Context Tax" and exhibit weak correlation with downstream SWE performance. In this paper, we bridge this gap by first introducing a rigorous data filtering strategy. Crucially, we propose the Entropy Compression Hypothesis, redefining intelligence not by scalar Top-1 compression, but by the capacity to structure uncertainty into Entropy-Compressed States of low orders ("reasonable hesitation"). Grounded in this fine-grained entropy analysis, we formulate a novel metric, HE-SNR (High-Entropy Signal-to-Noise Ratio). Validated on industrial-scale Mixture-of-Experts (MoE) models across varying context windows (32K/128K), our approach demonstrates superior robustness and predictive power. This work provides both the theoretical foundation and practical tools for optimizing the latent potential of LLMs in complex engineering domains.
MUA-RL: Multi-turn User-interacting Agent Reinforcement Learning for agentic tool use
Aug 26, 2025With the recent rapid advancement of Agentic Intelligence, agentic tool use in LLMs has become increasingly important. During multi-turn interactions between agents and users, the dynamic, uncertain, and stochastic nature of user demands poses significant challenges to the agent's tool invocation capabilities. Agents are no longer expected to simply call tools to deliver a result; rather, they must iteratively refine their understanding of user needs through communication while simultaneously invoking tools to resolve user queries. Existing reinforcement learning (RL) approaches for tool use lack the integration of genuinely dynamic users during the RL training process. To bridge this gap, we introduce MUA-RL (Multi-turn User-interacting Agent Reinforcement Learning for agentic tool use), a novel reinforcement learning framework that, for the first time in the field of agentic tool use, integrates LLM-simulated users into the reinforcement learning loop. MUA-RL aims to enable autonomous learning of models to communicate with users efficiently and use various tools to solve practical problems in dynamic multi-turn interactions. Evaluations are done on several multi-turn tool-using benchmarks (see Figure 1). Specifically, MUA-RL-32B achieves 67.3 on TAU2 Retail, 45.4 on TAU2 Airline, 28.3 on TAU2 Telecom, 28.4 on BFCL-V3 Multi Turn, and 82.5 on ACEBench Agent -- outperforming or matching the performance of larger open-source models such as DeepSeek-V3-0324 and Qwen3-235B-A22B in non-thinking settings.
Estimating Committor Functions via Deep Adaptive Sampling on Rare Transition Paths
Jan 26, 2025The committor functions are central to investigating rare but important events in molecular simulations. It is known that computing the committor function suffers from the curse of dimensionality. Recently, using neural networks to estimate the committor function has gained attention due to its potential for high-dimensional problems. Training neural networks to approximate the committor function needs to sample transition data from straightforward simulations of rare events, which is very inefficient. The scarcity of transition data makes it challenging to approximate the committor function. To address this problem, we propose an efficient framework to generate data points in the transition state region that helps train neural networks to approximate the committor function. We design a Deep Adaptive Sampling method for TRansition paths (DASTR), where deep generative models are employed to generate samples to capture the information of transitions effectively. In particular, we treat a non-negative function in the integrand of the loss functional as an unnormalized probability density function and approximate it with the deep generative model. The new samples from the deep generative model are located in the transition state region and fewer samples are located in the other region. This distribution provides effective samples for approximating the committor function and significantly improves the accuracy. We demonstrate the effectiveness of the proposed method through both simulations and realistic examples.
BAFNet: Bilateral Attention Fusion Network for Lightweight Semantic Segmentation of Urban Remote Sensing Images
Sep 16, 2024



Large-scale semantic segmentation networks often achieve high performance, while their application can be challenging when faced with limited sample sizes and computational resources. In scenarios with restricted network size and computational complexity, models encounter significant challenges in capturing long-range dependencies and recovering detailed information in images. We propose a lightweight bilateral semantic segmentation network called bilateral attention fusion network (BAFNet) to efficiently segment high-resolution urban remote sensing images. The model consists of two paths, namely dependency path and remote-local path. The dependency path utilizes large kernel attention to acquire long-range dependencies in the image. Besides, multi-scale local attention and efficient remote attention are designed to construct remote-local path. Finally, a feature aggregation module is designed to effectively utilize the different features of the two paths. Our proposed method was tested on public high-resolution urban remote sensing datasets Vaihingen and Potsdam, with mIoU reaching 83.20% and 86.53%, respectively. As a lightweight semantic segmentation model, BAFNet not only outperforms advanced lightweight models in accuracy but also demonstrates comparable performance to non-lightweight state-of-the-art methods on two datasets, despite a tenfold variance in floating-point operations and a fifteenfold difference in network parameters.
Deep adaptive sampling for surrogate modeling without labeled data
Feb 17, 2024Surrogate modeling is of great practical significance for parametric differential equation systems. In contrast to classical numerical methods, using physics-informed deep learning methods to construct simulators for such systems is a promising direction due to its potential to handle high dimensionality, which requires minimizing a loss over a training set of random samples. However, the random samples introduce statistical errors, which may become the dominant errors for the approximation of low-regularity and high-dimensional problems. In this work, we present a deep adaptive sampling method for surrogate modeling ($\text{DAS}^2$), where we generalize the deep adaptive sampling (DAS) method [62] [Tang, Wan and Yang, 2023] to build surrogate models for low-regularity parametric differential equations. In the parametric setting, the residual loss function can be regarded as an unnormalized probability density function (PDF) of the spatial and parametric variables. This PDF is approximated by a deep generative model, from which new samples are generated and added to the training set. Since the new samples match the residual-induced distribution, the refined training set can further reduce the statistical error in the current approximate solution. We demonstrate the effectiveness of $\text{DAS}^2$ with a series of numerical experiments, including the parametric lid-driven 2D cavity flow problem with a continuous range of Reynolds numbers from 100 to 1000.
A novel approach of solving the CNF-SAT problem
Jul 24, 2013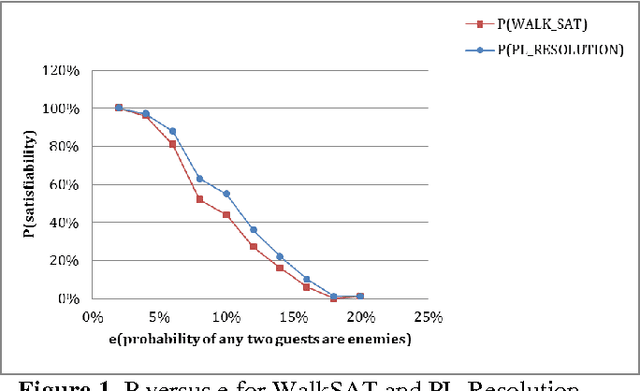
In this paper, we discussed CNF-SAT problem (NP-Complete problem) and analysis two solutions that can solve the problem, the PL-Resolution algorithm and the WalkSAT algorithm. PL-Resolution is a sound and complete algorithm that can be used to determine satisfiability and unsatisfiability with certainty. WalkSAT can determine satisfiability if it finds a model, but it cannot guarantee to find a model even there exists one. However, WalkSAT is much faster than PL-Resolution, which makes WalkSAT more practical; and we have analysis the performance between these two algorithms, and the performance of WalkSAT is acceptable if the problem is not so hard.