 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking LLM Watermark Detection in Black-Box Settings: A Non-Intrusive Third-Party Framework
Mar 16, 2026While watermarking serves as a critical mechanism for LLM provenance, existing secret-key schemes tightly couple detection with injection, requiring access to keys or provider-side scheme-specific detectors for verification. This dependency creates a fundamental barrier for real-world governance, as independent auditing becomes impossible without compromising model security or relying on the opaque claims of service providers. To resolve this dilemma, we introduce TTP-Detect, a pioneering black-box framework designed for non-intrusive, third-party watermark verification. By decoupling detection from injection, TTP-Detect reframes verification as a relative hypothesis testing problem. It employs a proxy model to amplify watermark-relevant signals and a suite of complementary relative measurements to assess the alignment of the query text with watermarked distributions. Extensive experiments across representative watermarking schemes, datasets and models demonstrate that TTP-Detect achieves superior detection performance and robustness against diverse attacks.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Is There More Pattern in Knowledge Graph? Exploring Proximity Pattern for Knowledge Graph Embedding
Oct 02, 2021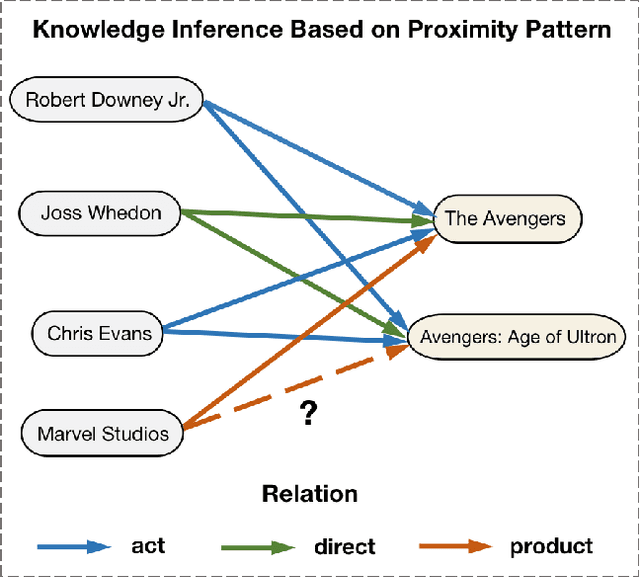

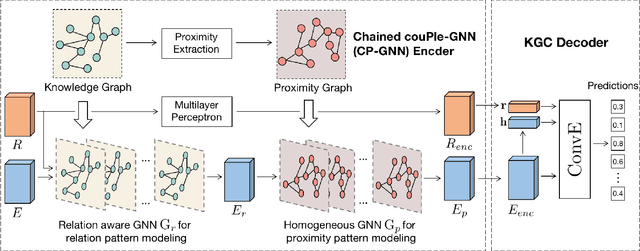
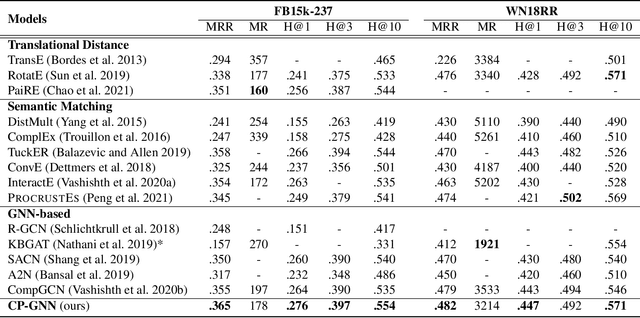
Modeling of relation pattern is the core focus of previous Knowledge Graph Embedding works, which represents how one entity is related to another semantically by some explicit relation. However, there is a more natural and intuitive relevancy among entities being always ignored, which is that how one entity is close to another semantically, without the consideration of any explicit relation. We name such semantic phenomenon in knowledge graph as proximity pattern. In this work, we explore the problem of how to define and represent proximity pattern, and how it can be utilized to help knowledge graph embedding. Firstly, we define the proximity of any two entities according to their statistically shared queries, then we construct a derived graph structure and represent the proximity pattern from global view. Moreover, with the original knowledge graph, we design a Chained couPle-GNN (CP-GNN) architecture to deeply merge the two patterns (graphs) together, which can encode a more comprehensive knowledge embedding. Being evaluated on FB15k-237 and WN18RR datasets, CP-GNN achieves state-of-the-art results for Knowledge Graph Completion task, and can especially boost the modeling capacity for complex queries that contain multiple answer entities, proving the effectiveness of introduced proximity pattern.
RLINK: Deep Reinforcement Learning for User Identity Linkage
Oct 31, 2019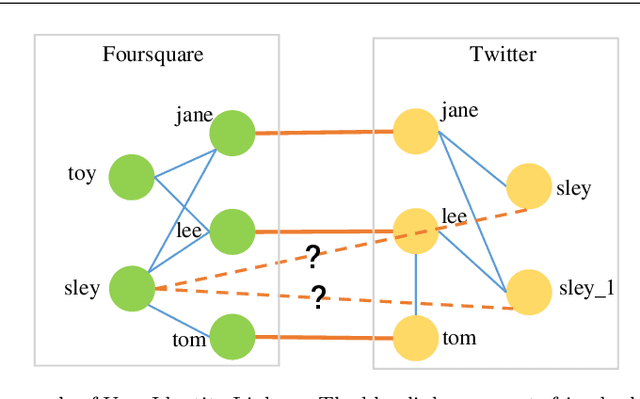
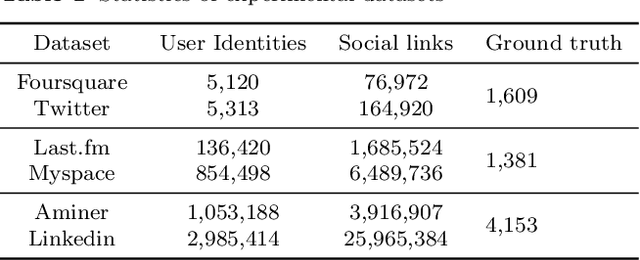
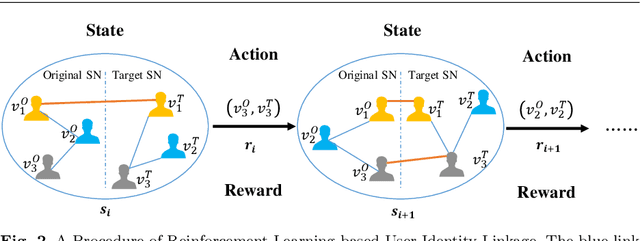
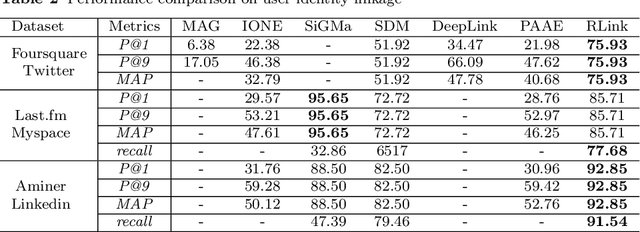
User identity linkage is a task of recognizing the identities of the same user across different social networks (SN). Previous works tackle this problem via estimating the pairwise similarity between identities from different SN, predicting the label of identity pairs or selecting the most relevant identity pair based on the similarity scores. However, most of these methods ignore the results of previously matched identities, which could contribute to the linkage in following matching steps. To address this problem, we convert user identity linkage into a sequence decision problem and propose a reinforcement learning model to optimize the linkage strategy from the global perspective. Our method makes full use of both the social network structure and the history matched identities, and explores the long-term influence of current matching on subsequent decisions. We conduct experiments on different types of datasets, the results show that our method achieves better performance than other state-of-the-art methods.