 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Multitask Learning based on Tensorized SVMs and LSSVMs
Aug 30, 2023



Multitask learning (MTL) leverages task-relatedness to enhance performance. With the emergence of multimodal data, tasks can now be referenced by multiple indices. In this paper, we employ high-order tensors, with each mode corresponding to a task index, to naturally represent tasks referenced by multiple indices and preserve their structural relations. Based on this representation, we propose a general framework of low-rank MTL methods with tensorized support vector machines (SVMs) and least square support vector machines (LSSVMs), where the CP factorization is deployed over the coefficient tensor. Our approach allows to model the task relation through a linear combination of shared factors weighted by task-specific factors and is generalized to both classification and regression problems. Through the alternating optimization scheme and the Lagrangian function, each subproblem is transformed into a convex problem, formulated as a quadratic programming or linear system in the dual form. In contrast to previous MTL frameworks, our decision function in the dual induces a weighted kernel function with a task-coupling term characterized by the similarities of the task-specific factors, better revealing the explicit relations across tasks in MTL. Experimental results validate the effectiveness and superiority of our proposed methods compared to existing state-of-the-art approaches in MTL. The code of implementation will be available at https://github.com/liujiani0216/TSVM-MTL.
Multi-Frame Self-Supervised Depth Estimation with Multi-Scale Feature Fusion in Dynamic Scenes
Mar 26, 2023Multi-frame methods improve monocular depth estimation over single-frame approaches by aggregating spatial-temporal information via feature matching. However, the spatial-temporal feature leads to accuracy degradation in dynamic scenes. To enhance the performance, recent methods tend to propose complex architectures for feature matching and dynamic scenes. In this paper, we show that a simple learning framework, together with designed feature augmentation, leads to superior performance. (1) A novel dynamic objects detecting method with geometry explainability is proposed. The detected dynamic objects are excluded during training, which guarantees the static environment assumption and relieves the accuracy degradation problem of the multi-frame depth estimation. (2) Multi-scale feature fusion is proposed for feature matching in the multi-frame depth network, which improves feature matching, especially between frames with large camera motion. (3) The robust knowledge distillation with a robust teacher network and reliability guarantee is proposed, which improves the multi-frame depth estimation without computation complexity increase during the test. The experiments show that our proposed methods achieve great performance improvement on the multi-frame depth estimation.
PCR-CG: Point Cloud Registration via Deep Color and Geometry
Feb 28, 2023In this paper, we introduce PCR-CG: a novel 3D point cloud registration module explicitly embedding the color signals into the geometry representation. Different from previous methods that only use geometry representation, our module is specifically designed to effectively correlate color into geometry for the point cloud registration task. Our key contribution is a 2D-3D cross-modality learning algorithm that embeds the deep features learned from color signals to the geometry representation. With our designed 2D-3D projection module, the pixel features in a square region centered at correspondences perceived from images are effectively correlated with point clouds. In this way, the overlapped regions can be inferred not only from point cloud but also from the texture appearances. Adding color is non-trivial. We compare against a variety of baselines designed for adding color to 3D, such as exhaustively adding per-pixel features or RGB values in an implicit manner. We leverage Predator [25] as the baseline method and incorporate our proposed module onto it. To validate the effectiveness of 2D features, we ablate different 2D pre-trained networks and show a positive correlation between the pre-trained weights and the task performance. Our experimental results indicate a significant improvement of 6.5% registration recall over the baseline method on the 3DLoMatch benchmark. We additionally evaluate our approach on SOTA methods and observe consistent improvements, such as an improvement of 2.4% registration recall over GeoTransformer as well as 3.5% over CoFiNet. Our study reveals a significant advantages of correlating explicit deep color features to the point cloud in the registration task.
Investigating Catastrophic Overfitting in Fast Adversarial Training: A Self-fitting Perspective
Feb 23, 2023



Although fast adversarial training provides an efficient approach for building robust networks, it may suffer from a serious problem known as catastrophic overfitting (CO), where the multi-step robust accuracy suddenly collapses to zero. In this paper, we for the first time decouple the FGSM examples into data-information and self-information, which reveals an interesting phenomenon called "self-fitting". Self-fitting, i.e., DNNs learn the self-information embedded in single-step perturbations, naturally leads to the occurrence of CO. When self-fitting occurs, the network experiences an obvious "channel differentiation" phenomenon that some convolution channels accounting for recognizing self-information become dominant, while others for data-information are suppressed. In this way, the network learns to only recognize images with sufficient self-information and loses generalization ability to other types of data. Based on self-fitting, we provide new insight into the existing methods to mitigate CO and extend CO to multi-step adversarial training. Our findings reveal a self-learning mechanism in adversarial training and open up new perspectives for suppressing different kinds of information to mitigate CO.
Self-Ensemble Protection: Training Checkpoints Are Good Data Protectors
Nov 22, 2022As data become increasingly vital for deep learning, a company would be very cautious about releasing data, because the competitors could use the released data to train high-performance models, thereby posing a tremendous threat to the company's commercial competence. To prevent training good models on the data, imperceptible perturbations could be added to it. Since such perturbations aim at hurting the entire training process, they should reflect the vulnerability of DNN training, rather than that of a single model. Based on this new idea, we seek adversarial examples that are always unrecognized (never correctly classified) in training. In this paper, we uncover them by modeling checkpoints' gradients, forming the proposed self-ensemble protection (SEP), which is very effective because (1) learning on examples ignored during normal training tends to yield DNNs ignoring normal examples; (2) checkpoints' cross-model gradients are close to orthogonal, meaning that they are as diverse as DNNs with different architectures in conventional ensemble. That is, our amazing performance of ensemble only requires the computation of training one model. By extensive experiments with 9 baselines on 3 datasets and 5 architectures, SEP is verified to be a new state-of-the-art, e.g., our small $\ell_\infty=2/255$ perturbations reduce the accuracy of a CIFAR-10 ResNet18 from 94.56\% to 14.68\%, compared to 41.35\% by the best-known method.Code is available at https://github.com/Sizhe-Chen/SEP.
Efficient Generalization Improvement Guided by Random Weight Perturbation
Nov 21, 2022



To fully uncover the great potential of deep neural networks (DNNs), various learning algorithms have been developed to improve the model's generalization ability. Recently, sharpness-aware minimization (SAM) establishes a generic scheme for generalization improvements by minimizing the sharpness measure within a small neighborhood and achieves state-of-the-art performance. However, SAM requires two consecutive gradient evaluations for solving the min-max problem and inevitably doubles the training time. In this paper, we resort to filter-wise random weight perturbations (RWP) to decouple the nested gradients in SAM. Different from the small adversarial perturbations in SAM, RWP is softer and allows a much larger magnitude of perturbations. Specifically, we jointly optimize the loss function with random perturbations and the original loss function: the former guides the network towards a wider flat region while the latter helps recover the necessary local information. These two loss terms are complementary to each other and mutually independent. Hence, the corresponding gradients can be efficiently computed in parallel, enabling nearly the same training speed as regular training. As a result, we achieve very competitive performance on CIFAR and remarkably better performance on ImageNet (e.g. $\mathbf{ +1.1\%}$) compared with SAM, but always require half of the training time. The code is released at https://github.com/nblt/RWP.
On Multi-head Ensemble of Smoothed Classifiers for Certified Robustness
Nov 20, 2022Randomized Smoothing (RS) is a promising technique for certified robustness, and recently in RS the ensemble of multiple deep neural networks (DNNs) has shown state-of-the-art performances. However, such an ensemble brings heavy computation burdens in both training and certification, and yet under-exploits individual DNNs and their mutual effects, as the communication between these classifiers is commonly ignored in optimization. In this work, starting from a single DNN, we augment the network with multiple heads, each of which pertains a classifier for the ensemble. A novel training strategy, namely Self-PAced Circular-TEaching (SPACTE), is proposed accordingly. SPACTE enables a circular communication flow among those augmented heads, i.e., each head teaches its neighbor with the self-paced learning using smoothed losses, which are specifically designed in relation to certified robustness. The deployed multi-head structure and the circular-teaching scheme of SPACTE jointly contribute to diversify and enhance the classifiers in augmented heads for ensemble, leading to even stronger certified robustness than ensembling multiple DNNs (effectiveness) at the cost of much less computational expenses (efficiency), verified by extensive experiments and discussions.
FG-UAP: Feature-Gathering Universal Adversarial Perturbation
Sep 27, 2022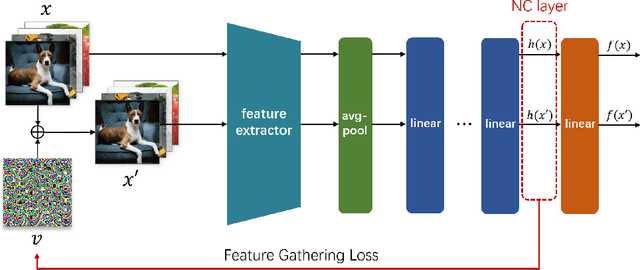
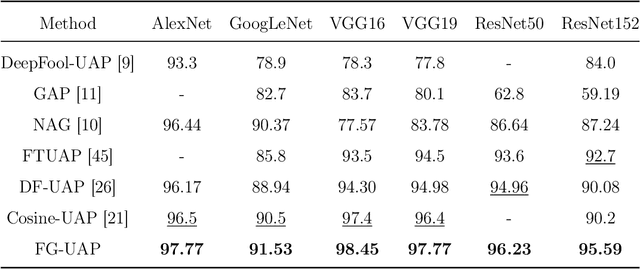

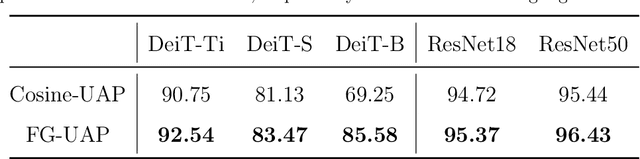
Deep Neural Networks (DNNs) are susceptible to elaborately designed perturbations, whether such perturbations are dependent or independent of images. The latter one, called Universal Adversarial Perturbation (UAP), is very attractive for model robustness analysis, since its independence of input reveals the intrinsic characteristics of the model. Relatively, another interesting observation is Neural Collapse (NC), which means the feature variability may collapse during the terminal phase of training. Motivated by this, we propose to generate UAP by attacking the layer where NC phenomenon happens. Because of NC, the proposed attack could gather all the natural images' features to its surrounding, which is hence called Feature-Gathering UAP (FG-UAP). We evaluate the effectiveness our proposed algorithm on abundant experiments, including untargeted and targeted universal attacks, attacks under limited dataset, and transfer-based black-box attacks among different architectures including Vision Transformers, which are believed to be more robust. Furthermore, we investigate FG-UAP in the view of NC by analyzing the labels and extracted features of adversarial examples, finding that collapse phenomenon becomes stronger after the model is corrupted. The code will be released when the paper is accepted.
Random Fourier Features for Asymmetric Kernels
Sep 18, 2022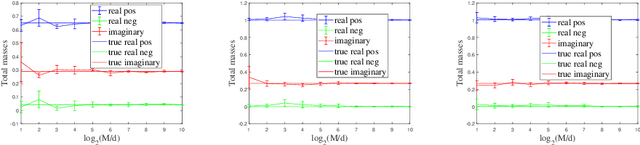
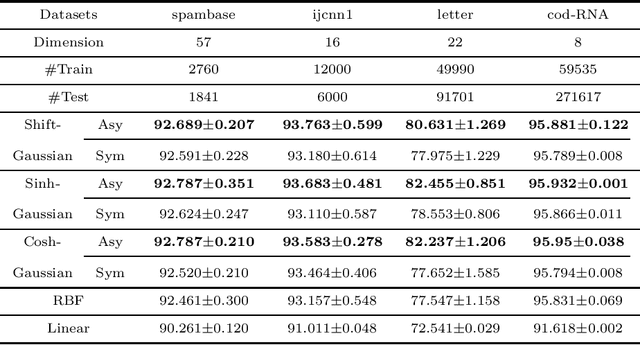
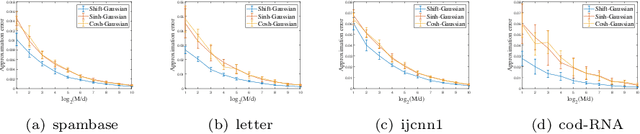
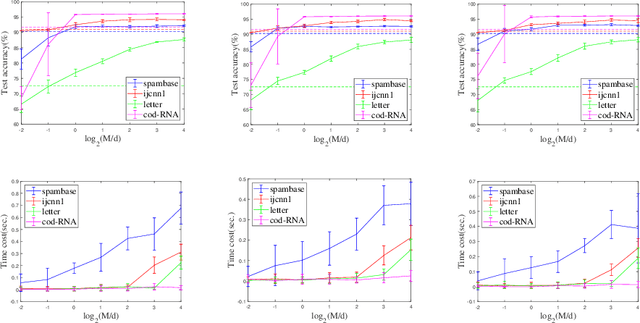
The random Fourier features (RFFs) method is a powerful and popular technique in kernel approximation for scalability of kernel methods. The theoretical foundation of RFFs is based on the Bochner theorem that relates symmetric, positive definite (PD) functions to probability measures. This condition naturally excludes asymmetric functions with a wide range applications in practice, e.g., directed graphs, conditional probability, and asymmetric kernels. Nevertheless, understanding asymmetric functions (kernels) and its scalability via RFFs is unclear both theoretically and empirically. In this paper, we introduce a complex measure with the real and imaginary parts corresponding to four finite positive measures, which expands the application scope of the Bochner theorem. By doing so, this framework allows for handling classical symmetric, PD kernels via one positive measure; symmetric, non-positive definite kernels via signed measures; and asymmetric kernels via complex measures, thereby unifying them into a general framework by RFFs, named AsK-RFFs. Such approximation scheme via complex measures enjoys theoretical guarantees in the perspective of the uniform convergence. In algorithmic implementation, to speed up the kernel approximation process, which is expensive due to the calculation of total mass, we employ a subset-based fast estimation method that optimizes total masses on a sub-training set, which enjoys computational efficiency in high dimensions. Our AsK-RFFs method is empirically validated on several typical large-scale datasets and achieves promising kernel approximation performance, which demonstrate the effectiveness of AsK-RFFs.
Unifying Gradients to Improve Real-world Robustness for Deep Networks
Aug 12, 2022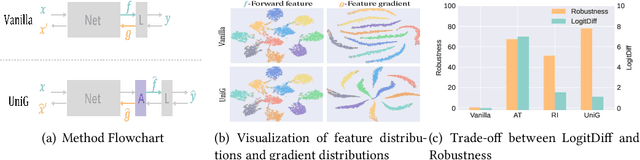
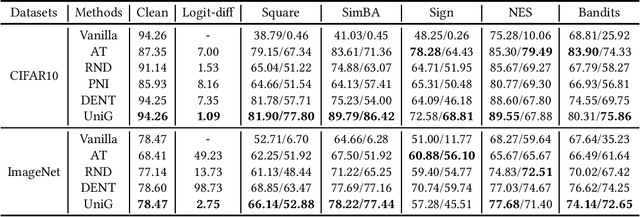
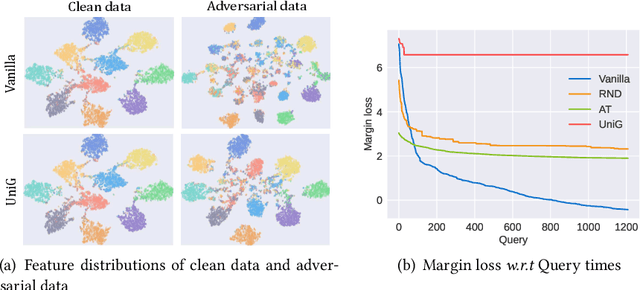

The wide application of deep neural networks (DNNs) demands an increasing amount of attention to their real-world robustness, i.e., whether a DNN resists black-box adversarial attacks, among them score-based query attacks (SQAs) are the most threatening ones because of their practicalities and effectiveness: the attackers only need dozens of queries on model outputs to seriously hurt a victim network. Defending against SQAs requires a slight but artful variation of outputs due to the service purpose for users, who share the same output information with attackers. In this paper, we propose a real-world defense, called Unifying Gradients (UniG), to unify gradients of different data so that attackers could only probe a much weaker attack direction that is similar for different samples. Since such universal attack perturbations have been validated as less aggressive than the input-specific perturbations, UniG protects real-world DNNs by indicating attackers a twisted and less informative attack direction. To enhance UniG's practical significance in real-world applications, we implement it as a Hadamard product module that is computationally-efficient and readily plugged into any model. According to extensive experiments on 5 SQAs and 4 defense baselines, UniG significantly improves real-world robustness without hurting clean accuracy on CIFAR10 and ImageNet. For instance, UniG maintains a CIFAR-10 model of 77.80% accuracy under 2500-query Square attack while the state-of-the-art adversarially-trained model only has 67.34% on CIFAR10. Simultaneously, UniG greatly surpasses all compared baselines in clean accuracy and the modification degree of outputs. The code would be released.