 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioFormer: Rethinking Cross-Subject Generalization via Spectral Structural Alignment in Biomedical Time-Series
May 21, 2026Cross-subject generalization in biomedical time-series refers to training on data from some subjects and testing on unseen subjects.The key challenge is to suppress subject specific variability in BTS representations.Most existing methods implicitly suppress the variability through model building or subject adversarial learning, but rarely model it explicitly.We introduce spectral drift as a new perspective to characterize subject specific variability.Specifically, BTS signals under the same label often share consistent oscillatory structure, yet exhibit subject-dependent magnitude or phase shifts in specific frequency components, which we interpret as subject-specific variability. Building on this insight, we propose BioFormer.At its core is a Frequency-Band Alignment Module(FBAM) that generates band-wise modulation factors from the spectral distribution and adaptively adjusts amplitude and phase to align spectral structure, thereby mitigating variability.We further pair FBAM with Sample Conditional Layer Normalization, which infers normalization parameters from intrinsic signal statistics rather than subject identity, stabilizing cross-subject representations.Extensive experiments on six datasets demonstrate that BioFormer outperforms 12 baselines, yielding absolute F1-score improvements of 6%.
DropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
Mar 08, 2025Spatio-temporal consistency is a critical research topic in video generation. A qualified generated video segment must ensure plot plausibility and coherence while maintaining visual consistency of objects and scenes across varying viewpoints. Prior research, especially in open-source projects, primarily focuses on either temporal or spatial consistency, or their basic combination, such as appending a description of a camera movement after a prompt without constraining the outcomes of this movement. However, camera movement may introduce new objects to the scene or eliminate existing ones, thereby overlaying and affecting the preceding narrative. Especially in videos with numerous camera movements, the interplay between multiple plots becomes increasingly complex. This paper introduces and examines integral spatio-temporal consistency, considering the synergy between plot progression and camera techniques, and the long-term impact of prior content on subsequent generation. Our research encompasses dataset construction through to the development of the model. Initially, we constructed a DropletVideo-10M dataset, which comprises 10 million videos featuring dynamic camera motion and object actions. Each video is annotated with an average caption of 206 words, detailing various camera movements and plot developments. Following this, we developed and trained the DropletVideo model, which excels in preserving spatio-temporal coherence during video generation. The DropletVideo dataset and model are accessible at https://dropletx.github.io.
Multi-modal Datasets for Super-resolution
Apr 13, 2020
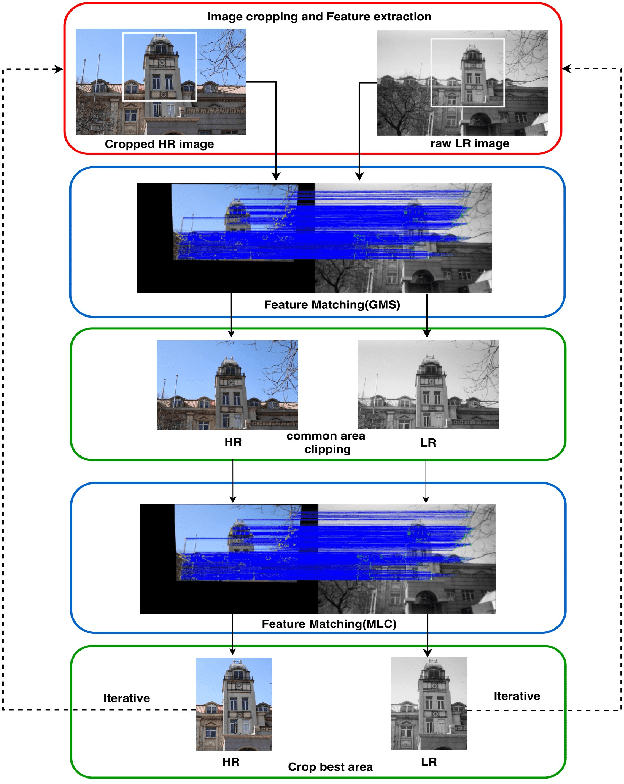
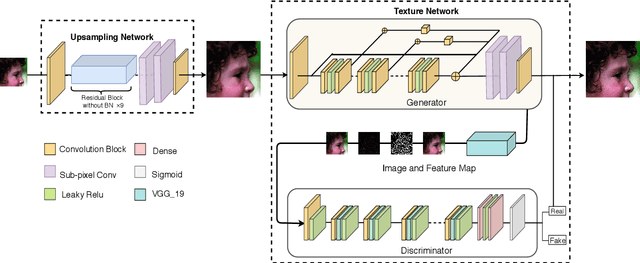

Nowdays, most datasets used to train and evaluate super-resolution models are single-modal simulation datasets. However, due to the variety of image degradation types in the real world, models trained on single-modal simulation datasets do not always have good robustness and generalization ability in different degradation scenarios. Previous work tended to focus only on true-color images. In contrast, we first proposed real-world black-and-white old photo datasets for super-resolution (OID-RW), which is constructed using two methods of manually filling pixels and shooting with different cameras. The dataset contains 82 groups of images, including 22 groups of character type and 60 groups of landscape and architecture. At the same time, we also propose a multi-modal degradation dataset (MDD400) to solve the super-resolution reconstruction in real-life image degradation scenarios. We managed to simulate the process of generating degraded images by the following four methods: interpolation algorithm, CNN network, GAN network and capturing videos with different bit rates. Our experiments demonstrate that not only the models trained on our dataset have better generalization capability and robustness, but also the trained images can maintain better edge contours and texture features.