 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpinionDigest: A Simple Framework for Opinion Summarization
May 05, 2020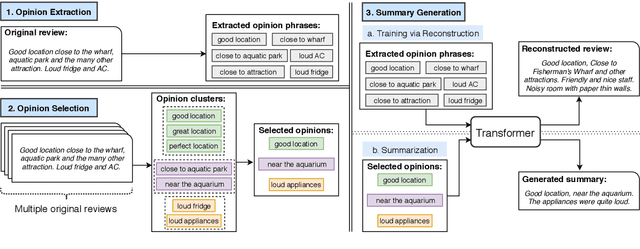
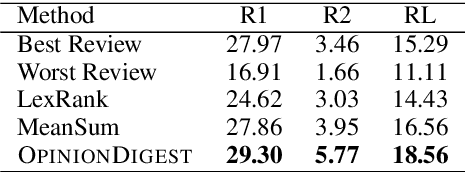
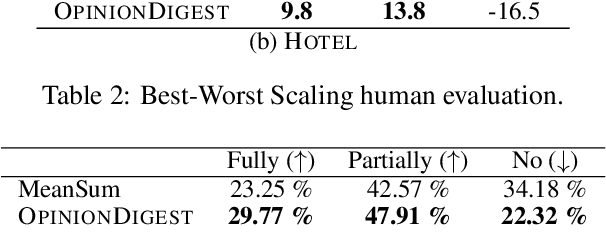
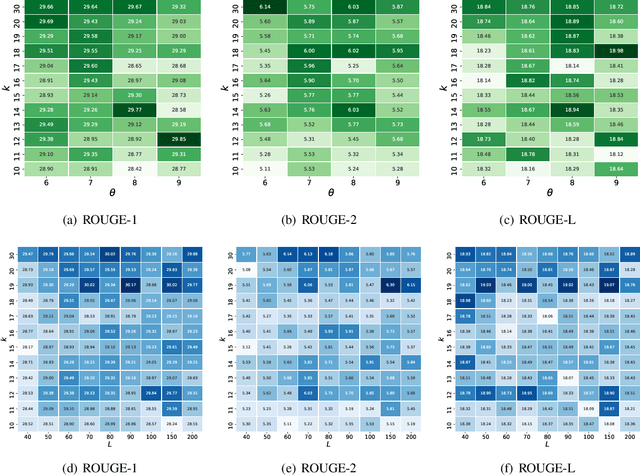
We present OpinionDigest, an abstractive opinion summarization framework, which does not rely on gold-standard summaries for training. The framework uses an Aspect-based Sentiment Analysis model to extract opinion phrases from reviews, and trains a Transformer model to reconstruct the original reviews from these extractions. At summarization time, we merge extractions from multiple reviews and select the most popular ones. The selected opinions are used as input to the trained Transformer model, which verbalizes them into an opinion summary. OpinionDigest can also generate customized summaries, tailored to specific user needs, by filtering the selected opinions according to their aspect and/or sentiment. Automatic evaluation on Yelp data shows that our framework outperforms competitive baselines. Human studies on two corpora verify that OpinionDigest produces informative summaries and shows promising customization capabilities.
Enhancing Review Comprehension with Domain-Specific Commonsense
Apr 06, 2020
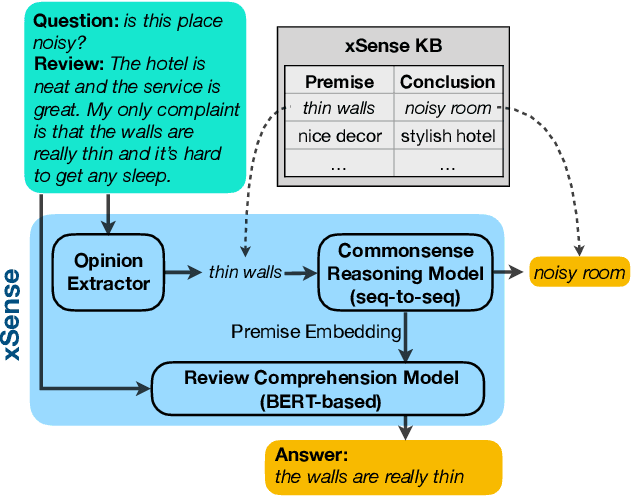
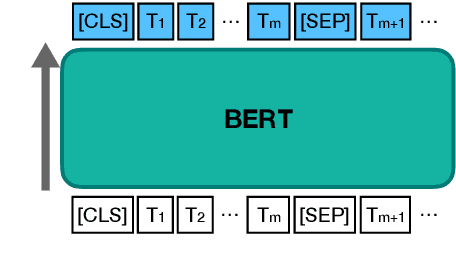
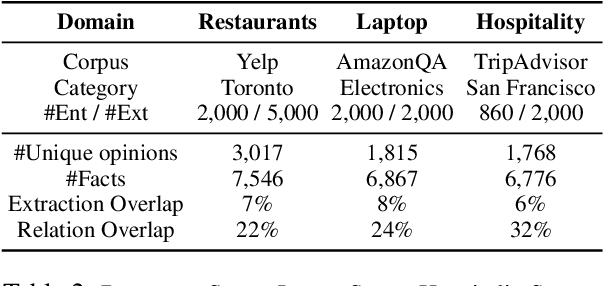
Review comprehension has played an increasingly important role in improving the quality of online services and products and commonsense knowledge can further enhance review comprehension. However, existing general-purpose commonsense knowledge bases lack sufficient coverage and precision to meaningfully improve the comprehension of domain-specific reviews. In this paper, we introduce xSense, an effective system for review comprehension using domain-specific commonsense knowledge bases (xSense KBs). We show that xSense KBs can be constructed inexpensively and present a knowledge distillation method that enables us to use xSense KBs along with BERT to boost the performance of various review comprehension tasks. We evaluate xSense over three review comprehension tasks: aspect extraction, aspect sentiment classification, and question answering. We find that xSense outperforms the state-of-the-art models for the first two tasks and improves the baseline BERT QA model significantly, demonstrating the usefulness of incorporating commonsense into review comprehension pipelines. To facilitate future research and applications, we publicly release three domain-specific knowledge bases and a domain-specific question answering benchmark along with this paper.
Snippext: Semi-supervised Opinion Mining with Augmented Data
Feb 07, 2020
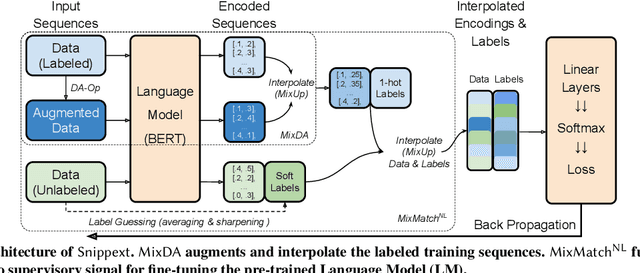
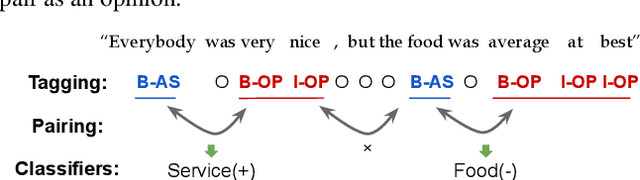
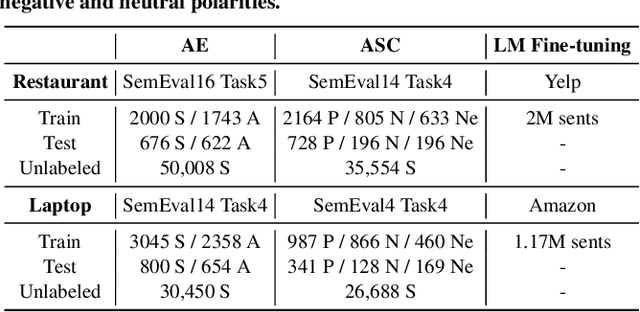
Online services are interested in solutions to opinion mining, which is the problem of extracting aspects, opinions, and sentiments from text. One method to mine opinions is to leverage the recent success of pre-trained language models which can be fine-tuned to obtain high-quality extractions from reviews. However, fine-tuning language models still requires a non-trivial amount of training data. In this paper, we study the problem of how to significantly reduce the amount of labeled training data required in fine-tuning language models for opinion mining. We describe Snippext, an opinion mining system developed over a language model that is fine-tuned through semi-supervised learning with augmented data. A novelty of Snippext is its clever use of a two-prong approach to achieve state-of-the-art (SOTA) performance with little labeled training data through: (1) data augmentation to automatically generate more labeled training data from existing ones, and (2) a semi-supervised learning technique to leverage the massive amount of unlabeled data in addition to the (limited amount of) labeled data. We show with extensive experiments that Snippext performs comparably and can even exceed previous SOTA results on several opinion mining tasks with only half the training data required. Furthermore, it achieves new SOTA results when all training data are leveraged. By comparison to a baseline pipeline, we found that Snippext extracts significantly more fine-grained opinions which enable new opportunities of downstream applications.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019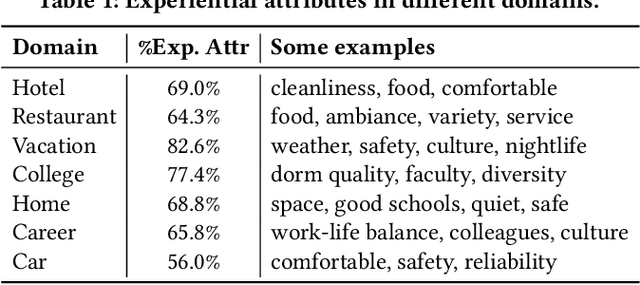
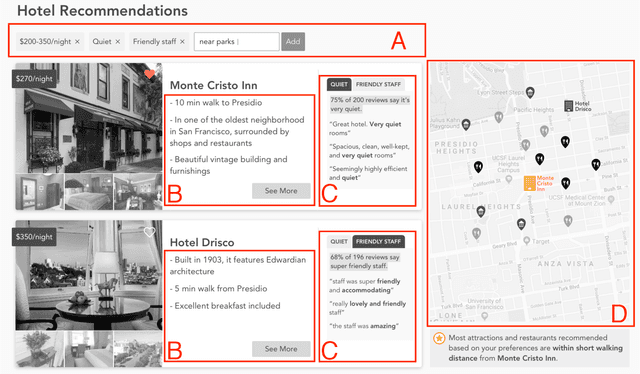
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.
Scalable Semantic Querying of Text
May 03, 2018
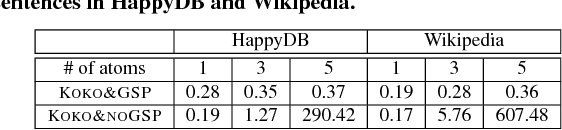
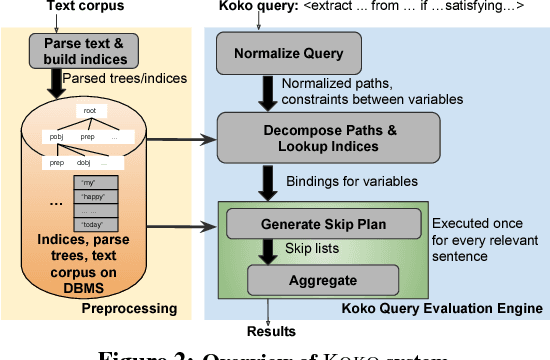
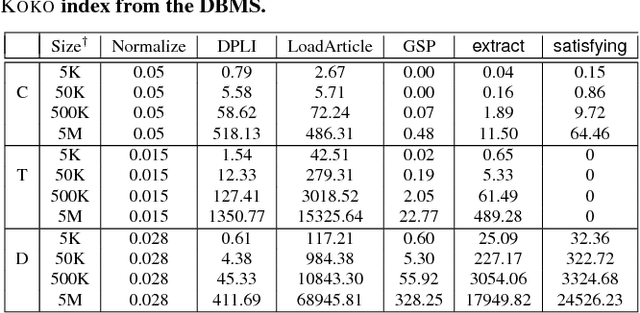
We present the KOKO system that takes declarative information extraction to a new level by incorporating advances in natural language processing techniques in its extraction language. KOKO is novel in that its extraction language simultaneously supports conditions on the surface of the text and on the structure of the dependency parse tree of sentences, thereby allowing for more refined extractions. KOKO also supports conditions that are forgiving to linguistic variation of expressing concepts and allows to aggregate evidence from the entire document in order to filter extractions. To scale up, KOKO exploits a multi-indexing scheme and heuristics for efficient extractions. We extensively evaluate KOKO over publicly available text corpora. We show that KOKO indices take up the smallest amount of space, are notably faster and more effective than a number of prior indexing schemes. Finally, we demonstrate KOKO's scale up on a corpus of 5 million Wikipedia articles.