 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable modeling to unify machine learning and physical models and advance Geosciences
Jan 10, 2023



Process-Based Modeling (PBM) and Machine Learning (ML) are often perceived as distinct paradigms in the geosciences. Here we present differentiable geoscientific modeling as a powerful pathway toward dissolving the perceived barrier between them and ushering in a paradigm shift. For decades, PBM offered benefits in interpretability and physical consistency but struggled to efficiently leverage large datasets. ML methods, especially deep networks, presented strong predictive skills yet lacked the ability to answer specific scientific questions. While various methods have been proposed for ML-physics integration, an important underlying theme -- differentiable modeling -- is not sufficiently recognized. Here we outline the concepts, applicability, and significance of differentiable geoscientific modeling (DG). "Differentiable" refers to accurately and efficiently calculating gradients with respect to model variables, critically enabling the learning of high-dimensional unknown relationships. DG refers to a range of methods connecting varying amounts of prior knowledge to neural networks and training them together, capturing a different scope than physics-guided machine learning and emphasizing first principles. Preliminary evidence suggests DG offers better interpretability and causality than ML, improved generalizability and extrapolation capability, and strong potential for knowledge discovery, while approaching the performance of purely data-driven ML. DG models require less training data while scaling favorably in performance and efficiency with increasing amounts of data. With DG, geoscientists may be better able to frame and investigate questions, test hypotheses, and discover unrecognized linkages.
Infrared Image Super-Resolution: Systematic Review, and Future Trends
Dec 22, 2022



Image Super-Resolution (SR) is essential for a wide range of computer vision and image processing tasks. Investigating infrared (IR) image (or thermal images) super-resolution is a continuing concern within the development of deep learning. This survey aims to provide a comprehensive perspective of IR image super-resolution, including its applications, hardware imaging system dilemmas, and taxonomy of image processing methodologies. In addition, the datasets and evaluation metrics in IR image super-resolution tasks are also discussed. Furthermore, the deficiencies in current technologies and possible promising directions for the community to explore are highlighted. To cope with the rapid development in this field, we intend to regularly update the relevant excellent work at \url{https://github.com/yongsongH/Infrared_Image_SR_Survey
Memory Consistent Unsupervised Off-the-Shelf Model Adaptation for Source-Relaxed Medical Image Segmentation
Sep 16, 2022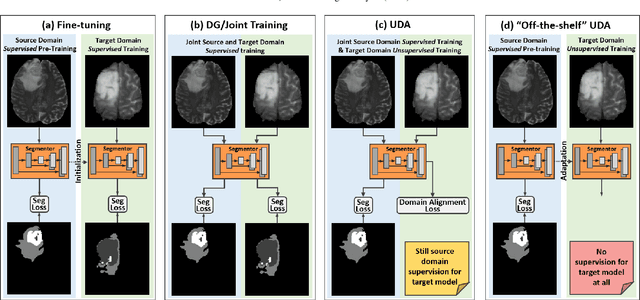
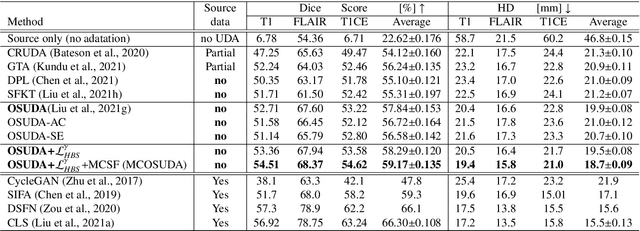
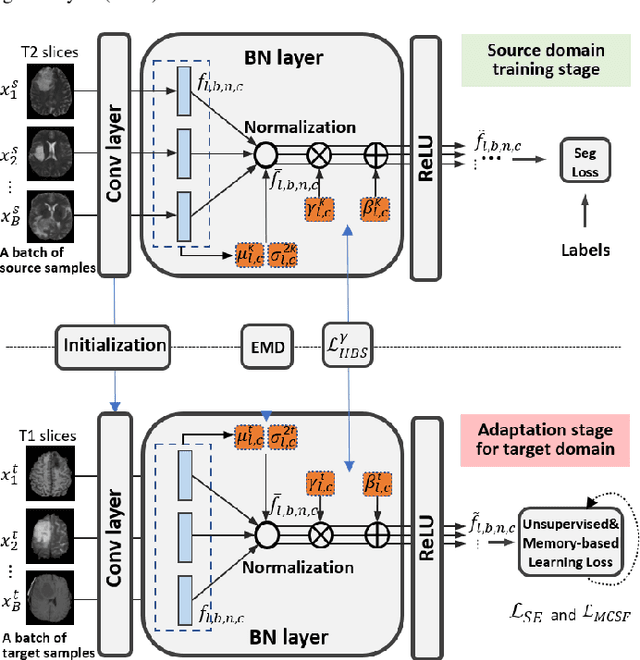
Unsupervised domain adaptation (UDA) has been a vital protocol for migrating information learned from a labeled source domain to facilitate the implementation in an unlabeled heterogeneous target domain. Although UDA is typically jointly trained on data from both domains, accessing the labeled source domain data is often restricted, due to concerns over patient data privacy or intellectual property. To sidestep this, we propose "off-the-shelf (OS)" UDA (OSUDA), aimed at image segmentation, by adapting an OS segmentor trained in a source domain to a target domain, in the absence of source domain data in adaptation. Toward this goal, we aim to develop a novel batch-wise normalization (BN) statistics adaptation framework. In particular, we gradually adapt the domain-specific low-order BN statistics, e.g., mean and variance, through an exponential momentum decay strategy, while explicitly enforcing the consistency of the domain shareable high-order BN statistics, e.g., scaling and shifting factors, via our optimization objective. We also adaptively quantify the channel-wise transferability to gauge the importance of each channel, via both low-order statistics divergence and a scaling factor.~Furthermore, we incorporate unsupervised self-entropy minimization into our framework to boost performance alongside a novel queued, memory-consistent self-training strategy to utilize the reliable pseudo label for stable and efficient unsupervised adaptation. We evaluated our OSUDA-based framework on both cross-modality and cross-subtype brain tumor segmentation and cardiac MR to CT segmentation tasks. Our experimental results showed that our memory consistent OSUDA performs better than existing source-relaxed UDA methods and yields similar performance to UDA methods with source data.
Tensor Decomposition based Personalized Federated Learning
Aug 27, 2022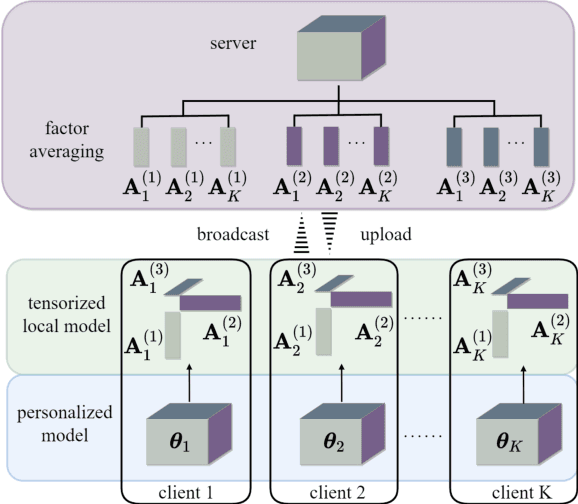
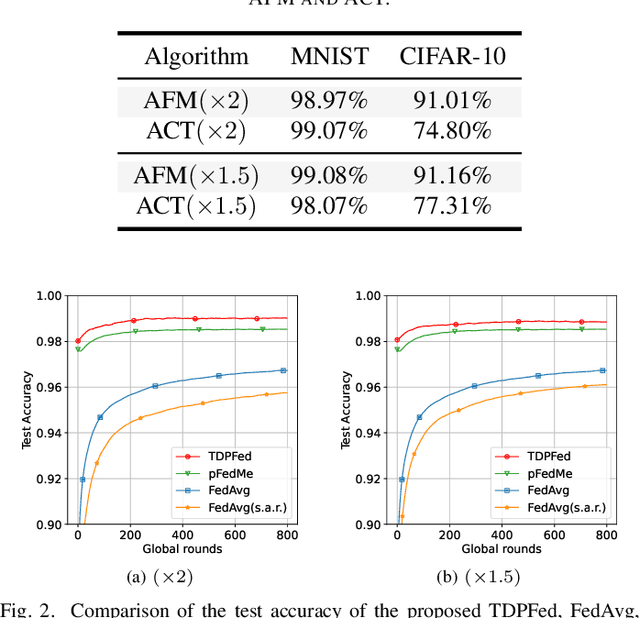
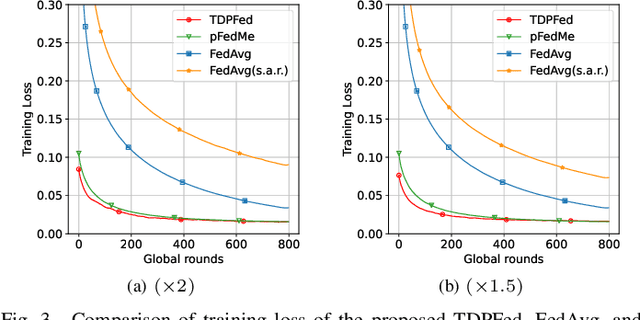
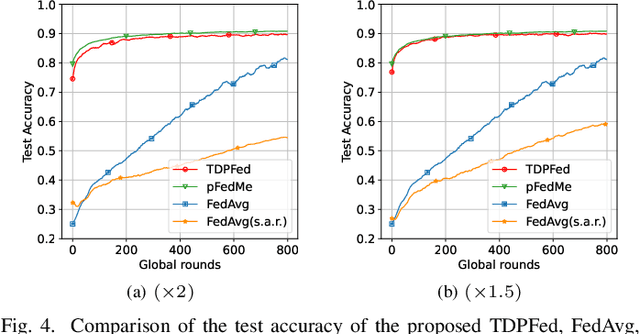
Federated learning (FL) is a new distributed machine learning framework that can achieve reliably collaborative training without collecting users' private data. However, due to FL's frequent communication and average aggregation strategy, they experience challenges scaling to statistical diversity data and large-scale models. In this paper, we propose a personalized FL framework, named Tensor Decomposition based Personalized Federated learning (TDPFed), in which we design a novel tensorized local model with tensorized linear layers and convolutional layers to reduce the communication cost. TDPFed uses a bi-level loss function to decouple personalized model optimization from the global model learning by controlling the gap between the personalized model and the tensorized local model. Moreover, an effective distributed learning strategy and two different model aggregation strategies are well designed for the proposed TDPFed framework. Theoretical convergence analysis and thorough experiments demonstrate that our proposed TDPFed framework achieves state-of-the-art performance while reducing the communication cost.
Constraining Pseudo-label in Self-training Unsupervised Domain Adaptation with Energy-based Model
Aug 26, 2022Deep learning is usually data starved, and the unsupervised domain adaptation (UDA) is developed to introduce the knowledge in the labeled source domain to the unlabeled target domain. Recently, deep self-training presents a powerful means for UDA, involving an iterative process of predicting the target domain and then taking the confident predictions as hard pseudo-labels for retraining. However, the pseudo-labels are usually unreliable, thus easily leading to deviated solutions with propagated errors. In this paper, we resort to the energy-based model and constrain the training of the unlabeled target sample with an energy function minimization objective. It can be achieved via a simple additional regularization or an energy-based loss. This framework allows us to gain the benefits of the energy-based model, while retaining strong discriminative performance following a plug-and-play fashion. The convergence property and its connection with classification expectation minimization are investigated. We deliver extensive experiments on the most popular and large-scale UDA benchmarks of image classification as well as semantic segmentation to demonstrate its generality and effectiveness.
Unsupervised Domain Adaptation for Segmentation with Black-box Source Model
Aug 16, 2022Unsupervised domain adaptation (UDA) has been widely used to transfer knowledge from a labeled source domain to an unlabeled target domain to counter the difficulty of labeling in a new domain. The training of conventional solutions usually relies on the existence of both source and target domain data. However, privacy of the large-scale and well-labeled data in the source domain and trained model parameters can become the major concern of cross center/domain collaborations. In this work, to address this, we propose a practical solution to UDA for segmentation with a black-box segmentation model trained in the source domain only, rather than original source data or a white-box source model. Specifically, we resort to a knowledge distillation scheme with exponential mixup decay (EMD) to gradually learn target-specific representations. In addition, unsupervised entropy minimization is further applied to regularization of the target domain confidence. We evaluated our framework on the BraTS 2018 database, achieving performance on par with white-box source model adaptation approaches.
Subtype-Aware Dynamic Unsupervised Domain Adaptation
Aug 16, 2022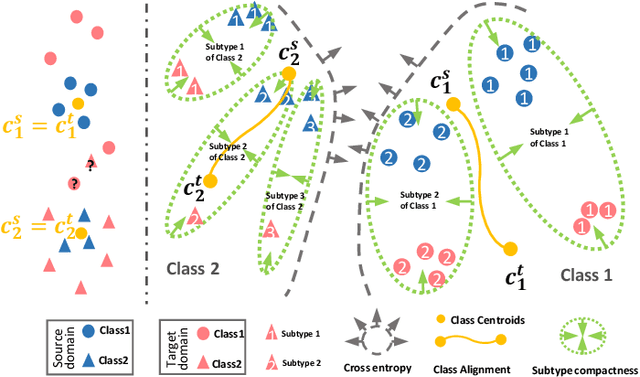
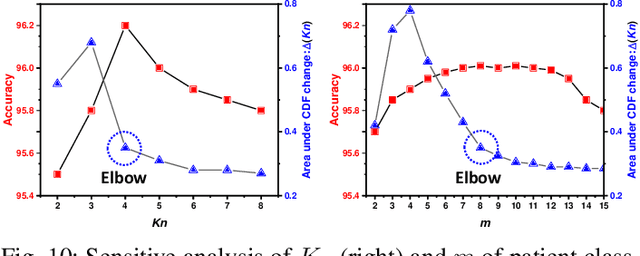
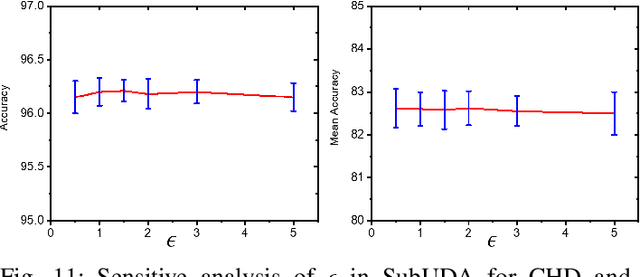
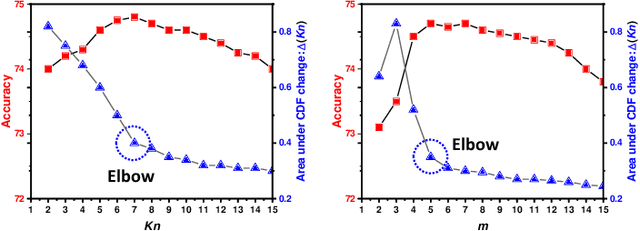
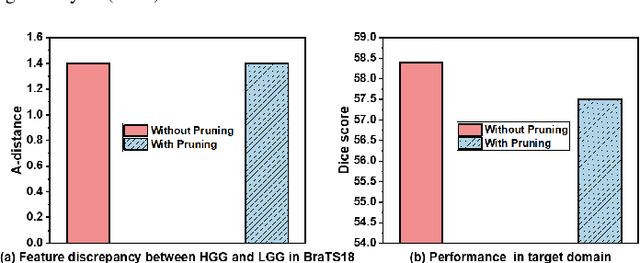
Unsupervised domain adaptation (UDA) has been successfully applied to transfer knowledge from a labeled source domain to target domains without their labels. Recently introduced transferable prototypical networks (TPN) further addresses class-wise conditional alignment. In TPN, while the closeness of class centers between source and target domains is explicitly enforced in a latent space, the underlying fine-grained subtype structure and the cross-domain within-class compactness have not been fully investigated. To counter this, we propose a new approach to adaptively perform a fine-grained subtype-aware alignment to improve performance in the target domain without the subtype label in both domains. The insight of our approach is that the unlabeled subtypes in a class have the local proximity within a subtype, while exhibiting disparate characteristics, because of different conditional and label shifts. Specifically, we propose to simultaneously enforce subtype-wise compactness and class-wise separation, by utilizing intermediate pseudo-labels. In addition, we systematically investigate various scenarios with and without prior knowledge of subtype numbers, and propose to exploit the underlying subtype structure. Furthermore, a dynamic queue framework is developed to evolve the subtype cluster centroids steadily using an alternative processing scheme. Experimental results, carried out with multi-view congenital heart disease data and VisDA and DomainNet, show the effectiveness and validity of our subtype-aware UDA, compared with state-of-the-art UDA methods.
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022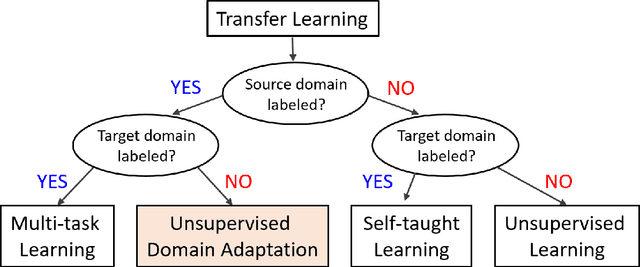

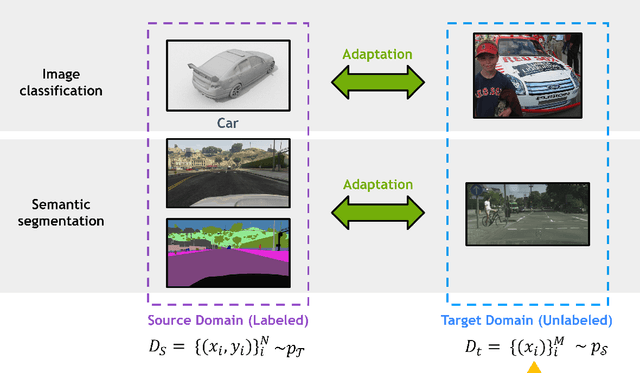
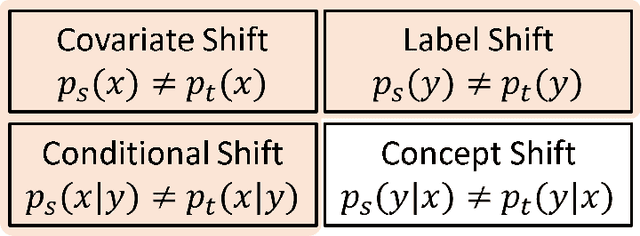
Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.
AI Enlightens Wireless Communication: A Transformer Backbone for CSI Feedback
Jun 16, 2022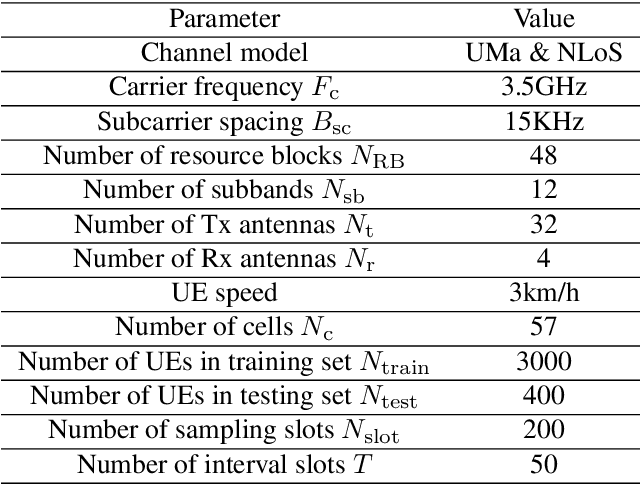

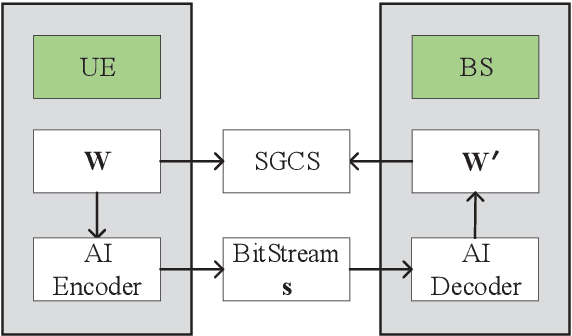
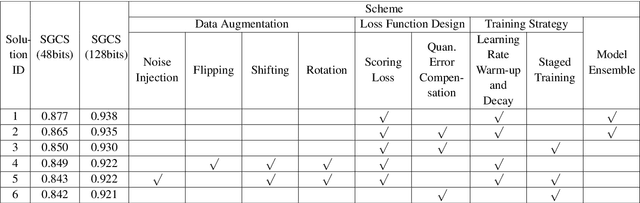
This paper is based on the background of the 2nd Wireless Communication Artificial Intelligence (AI) Competition (WAIC) which is hosted by IMT-2020(5G) Promotion Group 5G+AIWork Group, where the framework of the eigenvector-based channel state information (CSI) feedback problem is firstly provided. Then a basic Transformer backbone for CSI feedback referred to EVCsiNet-T is proposed. Moreover, a series of potential enhancements for deep learning based (DL-based) CSI feedback including i) data augmentation, ii) loss function design, iii) training strategy, and iv) model ensemble are introduced. The experimental results involving the comparison between EVCsiNet-T and traditional codebook methods over different channels are further provided, which show the advanced performance and a promising prospect of Transformer on DL-based CSI feedback problem.
ACT: Semi-supervised Domain-adaptive Medical Image Segmentation with Asymmetric Co-training
Jun 09, 2022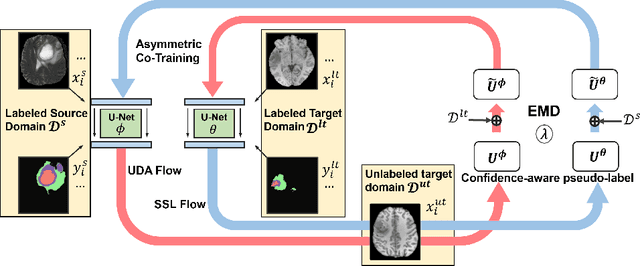
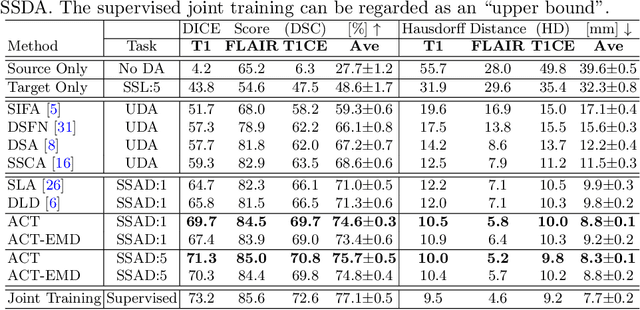
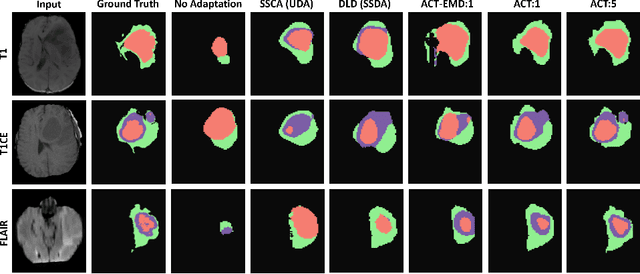
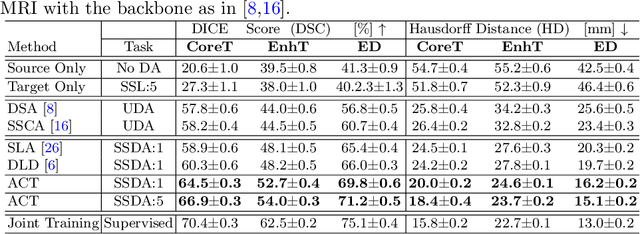
Unsupervised domain adaptation (UDA) has been vastly explored to alleviate domain shifts between source and target domains, by applying a well-performed model in an unlabeled target domain via supervision of a labeled source domain. Recent literature, however, has indicated that the performance is still far from satisfactory in the presence of significant domain shifts. Nonetheless, delineating a few target samples is usually manageable and particularly worthwhile, due to the substantial performance gain. Inspired by this, we aim to develop semi-supervised domain adaptation (SSDA) for medical image segmentation, which is largely underexplored. We, thus, propose to exploit both labeled source and target domain data, in addition to unlabeled target data in a unified manner. Specifically, we present a novel asymmetric co-training (ACT) framework to integrate these subsets and avoid the domination of the source domain data. Following a divide-and-conquer strategy, we explicitly decouple the label supervisions in SSDA into two asymmetric sub-tasks, including semi-supervised learning (SSL) and UDA, and leverage different knowledge from two segmentors to take into account the distinction between the source and target label supervisions. The knowledge learned in the two modules is then adaptively integrated with ACT, by iteratively teaching each other, based on the confidence-aware pseudo-label. In addition, pseudo label noise is well-controlled with an exponential MixUp decay scheme for smooth propagation. Experiments on cross-modality brain tumor MRI segmentation tasks using the BraTS18 database showed, even with limited labeled target samples, ACT yielded marked improvements over UDA and state-of-the-art SSDA methods and approached an "upper bound" of supervised joint training.