 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on 3GPP Rel-19 Channel Modeling for 6G FR3 (7-24 GHz): From Standard Specification to Simulation Implementation
Feb 07, 2026The upper-mid band (7-24 GHz), designated as Frequency Range 3 (FR3), has emerged as a definitive ``golden band" for 6G networks, strategically balancing the wide coverage of sub-6 GHz with the high capacity of mmWave. To compensate for the severe path loss inherent to this band, the deployment of Extremely Large Aperture Arrays (ELAA) is indispensable. However, the legacy 3GPP TR 38.901 channel model faces critical validity challenges when applied to 6G FR3, stemming from both the distinct propagation characteristics of this frequency band and the fundamental physical paradigm shift induced by ELAA. In response, 3GPP Release 19 (Rel-19) has validated the model through extensive new measurements and introduced significant enhancements. This tutorial provides a comprehensive guide to the Rel-19 channel model for 6G FR3, bridging the gap between standardization specifications and practical simulation implementation. First, we provide a high-level overview of the fundamental principles of the 3GPP channel modeling framework. Second, we detail the specific enhancements and modifications introduced in Rel-19, including the rationale behind the new Suburban Macro (SMa) scenario, the mathematical modeling of ELAA-driven features such as near-field and spatial non-stationarity, and the recalibration of large-scale parameters. Overall, this tutorial serves as an essential guide for researchers and engineers to master the latest 3GPP channel modeling methodology, laying a solid foundation for the accurate design and performance evaluation of future 6G FR3 networks.
Synonym Detection Using Syntactic Dependency And Neural Embeddings
Sep 30, 2022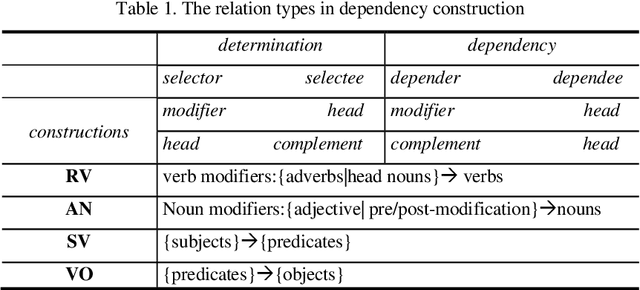
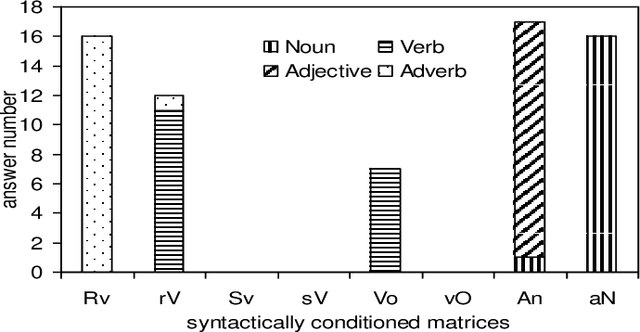
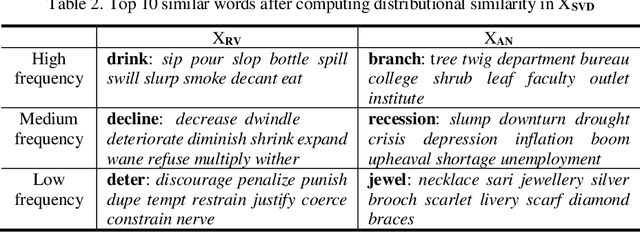
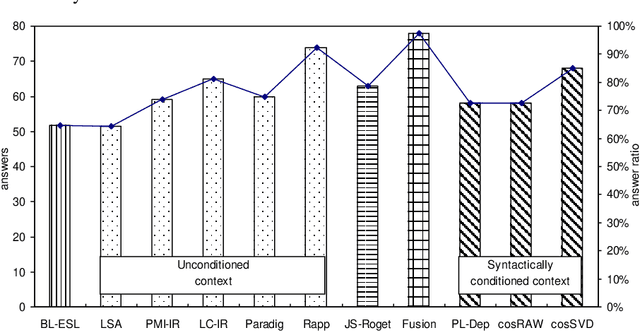
Recent advances on the Vector Space Model have significantly improved some NLP applications such as neural machine translation and natural language generation. Although word co-occurrences in context have been widely used in counting-/predicting-based distributional models, the role of syntactic dependencies in deriving distributional semantics has not yet been thoroughly investigated. By comparing various Vector Space Models in detecting synonyms in TOEFL, we systematically study the salience of syntactic dependencies in accounting for distributional similarity. We separate syntactic dependencies into different groups according to their various grammatical roles and then use context-counting to construct their corresponding raw and SVD-compressed matrices. Moreover, using the same training hyperparameters and corpora, we study typical neural embeddings in the evaluation. We further study the effectiveness of injecting human-compiled semantic knowledge into neural embeddings on computing distributional similarity. Our results show that the syntactically conditioned contexts can interpret lexical semantics better than the unconditioned ones, whereas retrofitting neural embeddings with semantic knowledge can significantly improve synonym detection.