 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Policy Selection and Fine-Tuning under Interaction Budgets for Offline-to-Online Reinforcement Learning
May 06, 2026In offline-to-online reinforcement learning (O2O-RL), policies are first safely trained offline using previously collected datasets and then further fine-tuned for tasks via limited online interactions. In a typical O2O-RL pipeline, candidate policies trained with offline RL are evaluated via either off-policy evaluation (OPE) or online evaluation (OE). The policy with the highest estimated value is then deployed and continually fine-tuned. However, this setup has two main issues. First, OPE can be unreliable, making it risky to deploy a policy based solely on those estimates, whereas OE may identify a viable policy with substantial online interaction, which could have been used for fine-tuning. Second--and more importantly--it is also often not possible to determine a priori whether a pretrained policy will improve with post-deployment fine-tuning, especially in non-stationary environments. As a result, procedures committing to a single deployed policy are impractical in many real-world settings. Moreover, a naive remedy that exhaustively fine-tunes all candidates would violate interaction budget constraints and is likewise infeasible. In this paper, we propose a novel adaptive approach for policy selection and fine-tuning under online interaction budgets in O2O-RL. Following the standard pipeline, we first train a set of candidate policies with different offline RL algorithms and hyperparameters; we then perform OPE to obtain initial performance estimates. We next adaptively select and fine-tune the policies based on their predicted performance via an upper-confidence-bound approach thereby making efficient use of online interactions. We demonstrate that our approach improves upon O2O-RL baselines with various benchmarks.
Neuro-Logic Lifelong Learning
Nov 16, 2025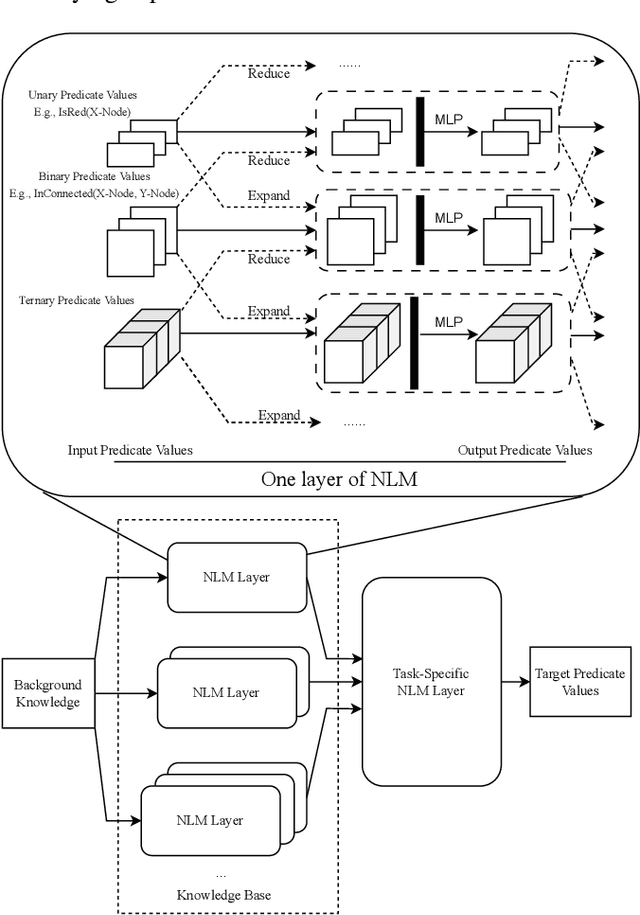
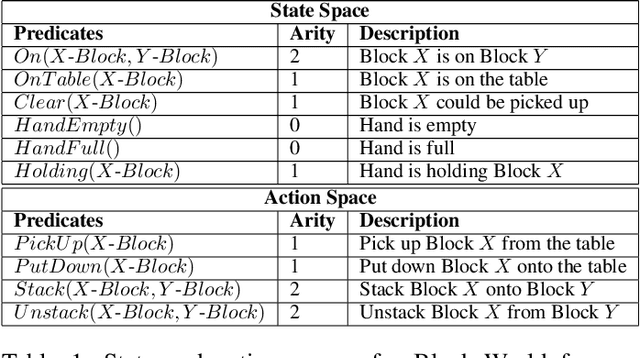
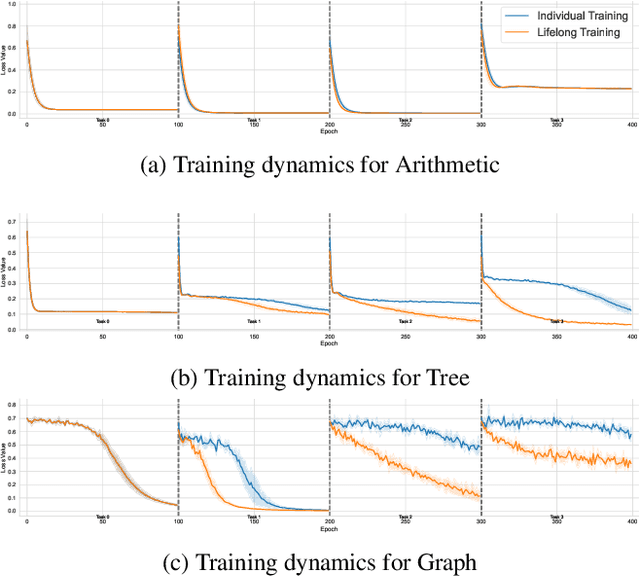
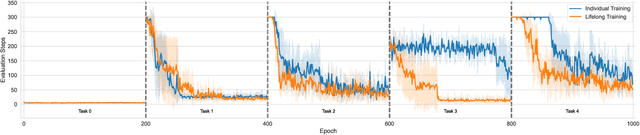
Solving Inductive Logic Programming (ILP) problems with neural networks is a key challenge in Neural-Symbolic Ar- tificial Intelligence (AI). While most research has focused on designing novel network architectures for individual prob- lems, less effort has been devoted to exploring new learning paradigms involving a sequence of problems. In this work, we investigate lifelong learning ILP, which leverages the com- positional and transferable nature of logic rules for efficient learning of new problems. We introduce a compositional framework, demonstrating how logic rules acquired from ear- lier tasks can be efficiently reused in subsequent ones, leading to improved scalability and performance. We formalize our approach and empirically evaluate it on sequences of tasks. Experimental results validate the feasibility and advantages of this paradigm, opening new directions for continual learn- ing in Neural-Symbolic AI.