 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Difference Guided Motion Deblurring with the Complementary Vision Sensor
Apr 12, 2026Motion blur arises when rapid scene changes occur during the exposure period, collapsing rich intra-exposure motion into a single RGB frame. Without explicit structural or temporal cues, RGB-only deblurring is highly ill-posed and often fails under extreme motion. Inspired by the human visual system, brain-inspired vision sensors introduce temporally dense information to alleviate this problem. However, event cameras still suffer from event rate saturation under rapid motion, while the event modality entangles edge features and motion cues, which limits their effectiveness. As a recent breakthrough, the complementary vision sensor (CVS), Tianmouc, captures synchronized RGB frames together with high-frame-rate, multi-bit spatial difference (SD, encoding structural edges) and temporal difference (TD, encoding motion cues) data within a single RGB exposure, offering a promising solution for RGB deblurring under extreme dynamic scenes. To fully leverage these complementary modalities, we propose Spatio-Temporal Difference Guided Deblur Net (STGDNet), which adopts a recurrent multi-branch architecture that iteratively encodes and fuses SD and TD sequences to restore structure and color details lost in blurry RGB inputs. Our method outperforms current RGB or event-based approaches in both synthetic CVS dataset and real-world evaluations. Moreover, STGDNet exhibits strong generalization capability across over 100 extreme real-world scenarios. Project page: https://tmcDeblur.github.io/
Optimizing the Whole-life Cost in End-to-end CNN Acceleration
Apr 12, 2021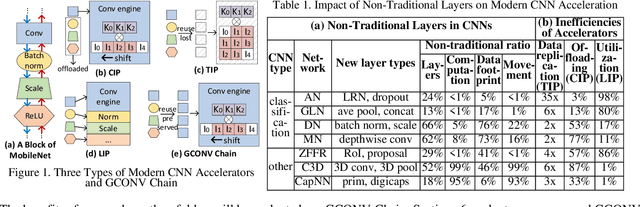
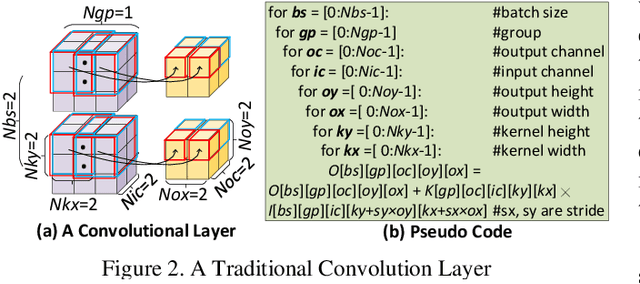
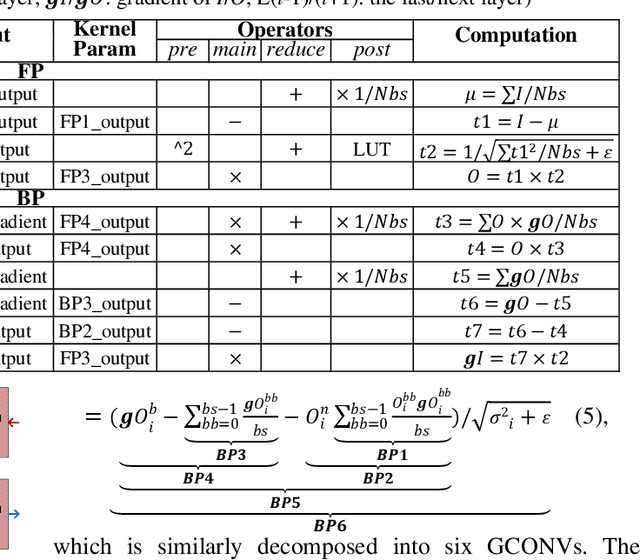

The acceleration of CNNs has gained increasing atten-tion since their success in computer vision. With the heterogeneous functional layers that cannot be pro-cessed by the accelerators proposed for convolution layers only, modern end-to-end CNN acceleration so-lutions either transform the diverse computation into matrix/vector arithmetic, which loses data reuse op-portunities in convolution, or introduce dedicated functional unit to each kind of layer, which results in underutilization and high update expense. To enhance the whole-life cost efficiency, we need an acceleration solution that is efficient in processing CNN layers and has the generality to apply to all kinds of existing and emerging layers. To this end, we pro-pose GCONV Chain, a method to convert the entire CNN computation into a chain of standard general convolutions (GCONV) that can be efficiently pro-cessed by the existing CNN accelerators. This paper comprehensively analyzes the GCONV Chain model and proposes a full-stack implementation to support GCONV Chain. On one hand, the results on seven var-ious CNNs demonstrate that GCONV Chain improves the performance and energy efficiency of existing CNN accelerators by an average of 3.4x and 3.2x re-spectively. On the other hand, we show that GCONV Chain provides low whole-life costs for CNN accelera-tion, including both developer efforts and total cost of ownership for the users.