 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA review of heterogeneous data mining for brain disorders
Aug 05, 2015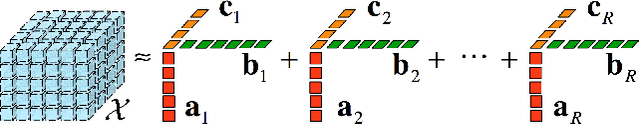
With rapid advances in neuroimaging techniques, the research on brain disorder identification has become an emerging area in the data mining community. Brain disorder data poses many unique challenges for data mining research. For example, the raw data generated by neuroimaging experiments is in tensor representations, with typical characteristics of high dimensionality, structural complexity and nonlinear separability. Furthermore, brain connectivity networks can be constructed from the tensor data, embedding subtle interactions between brain regions. Other clinical measures are usually available reflecting the disease status from different perspectives. It is expected that integrating complementary information in the tensor data and the brain network data, and incorporating other clinical parameters will be potentially transformative for investigating disease mechanisms and for informing therapeutic interventions. Many research efforts have been devoted to this area. They have achieved great success in various applications, such as tensor-based modeling, subgraph pattern mining, multi-view feature analysis. In this paper, we review some recent data mining methods that are used for analyzing brain disorders.
DuSK: A Dual Structure-preserving Kernel for Supervised Tensor Learning with Applications to Neuroimages
Aug 05, 2014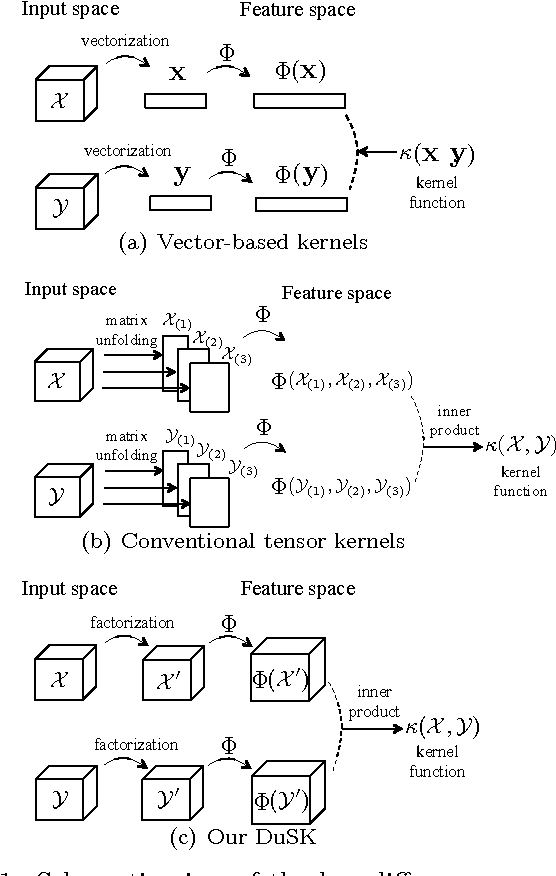

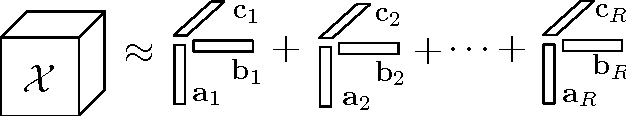
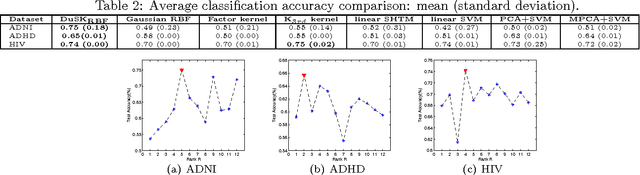
With advances in data collection technologies, tensor data is assuming increasing prominence in many applications and the problem of supervised tensor learning has emerged as a topic of critical significance in the data mining and machine learning community. Conventional methods for supervised tensor learning mainly focus on learning kernels by flattening the tensor into vectors or matrices, however structural information within the tensors will be lost. In this paper, we introduce a new scheme to design structure-preserving kernels for supervised tensor learning. Specifically, we demonstrate how to leverage the naturally available structure within the tensorial representation to encode prior knowledge in the kernel. We proposed a tensor kernel that can preserve tensor structures based upon dual-tensorial mapping. The dual-tensorial mapping function can map each tensor instance in the input space to another tensor in the feature space while preserving the tensorial structure. Theoretically, our approach is an extension of the conventional kernels in the vector space to tensor space. We applied our novel kernel in conjunction with SVM to real-world tensor classification problems including brain fMRI classification for three different diseases (i.e., Alzheimer's disease, ADHD and brain damage by HIV). Extensive empirical studies demonstrate that our proposed approach can effectively boost tensor classification performances, particularly with small sample sizes.
Large-Scale Multi-Label Learning with Incomplete Label Assignments
Jul 06, 2014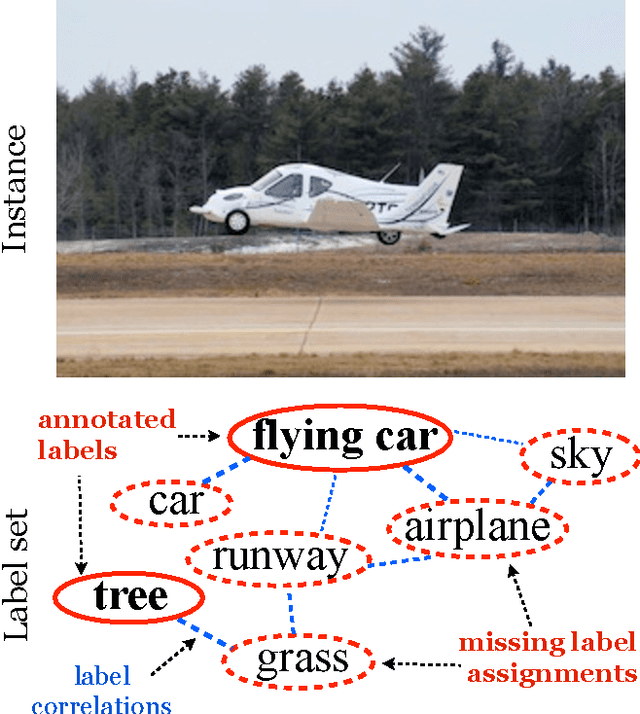

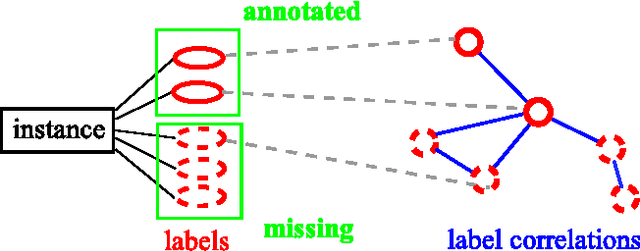

Multi-label learning deals with the classification problems where each instance can be assigned with multiple labels simultaneously. Conventional multi-label learning approaches mainly focus on exploiting label correlations. It is usually assumed, explicitly or implicitly, that the label sets for training instances are fully labeled without any missing labels. However, in many real-world multi-label datasets, the label assignments for training instances can be incomplete. Some ground-truth labels can be missed by the labeler from the label set. This problem is especially typical when the number instances is very large, and the labeling cost is very high, which makes it almost impossible to get a fully labeled training set. In this paper, we study the problem of large-scale multi-label learning with incomplete label assignments. We propose an approach, called MPU, based upon positive and unlabeled stochastic gradient descent and stacked models. Unlike prior works, our method can effectively and efficiently consider missing labels and label correlations simultaneously, and is very scalable, that has linear time complexities over the size of the data. Extensive experiments on two real-world multi-label datasets show that our MPU model consistently outperform other commonly-used baselines.
Multilabel Consensus Classification
Oct 16, 2013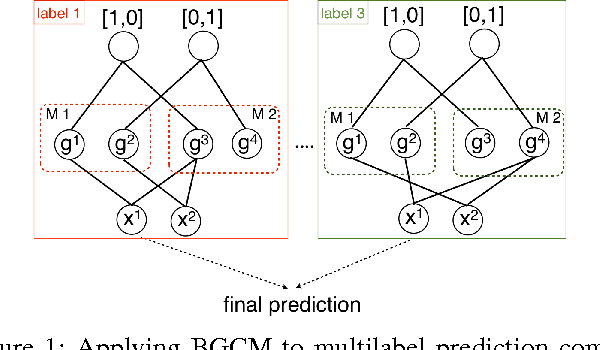
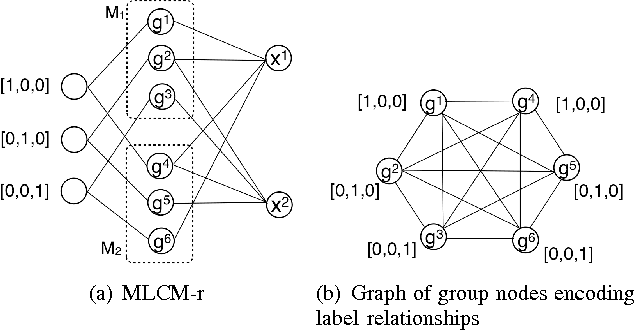
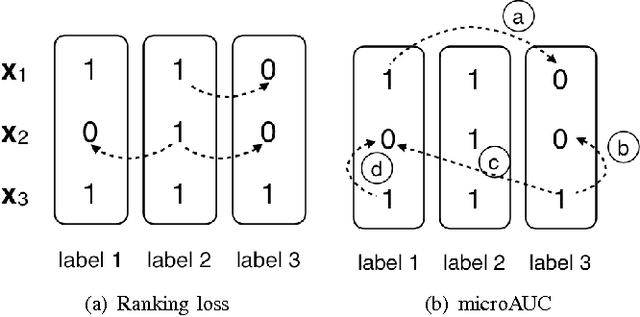
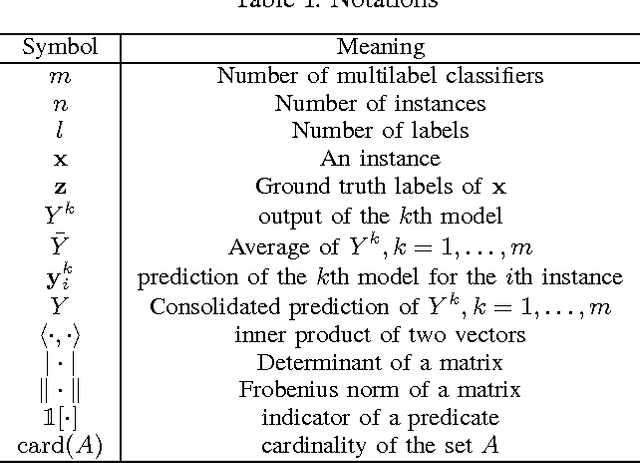
In the era of big data, a large amount of noisy and incomplete data can be collected from multiple sources for prediction tasks. Combining multiple models or data sources helps to counteract the effects of low data quality and the bias of any single model or data source, and thus can improve the robustness and the performance of predictive models. Out of privacy, storage and bandwidth considerations, in certain circumstances one has to combine the predictions from multiple models or data sources to obtain the final predictions without accessing the raw data. Consensus-based prediction combination algorithms are effective for such situations. However, current research on prediction combination focuses on the single label setting, where an instance can have one and only one label. Nonetheless, data nowadays are usually multilabeled, such that more than one label have to be predicted at the same time. Direct applications of existing prediction combination methods to multilabel settings can lead to degenerated performance. In this paper, we address the challenges of combining predictions from multiple multilabel classifiers and propose two novel algorithms, MLCM-r (MultiLabel Consensus Maximization for ranking) and MLCM-a (MLCM for microAUC). These algorithms can capture label correlations that are common in multilabel classifications, and optimize corresponding performance metrics. Experimental results on popular multilabel classification tasks verify the theoretical analysis and effectiveness of the proposed methods.
Predicting Social Links for New Users across Aligned Heterogeneous Social Networks
Oct 13, 2013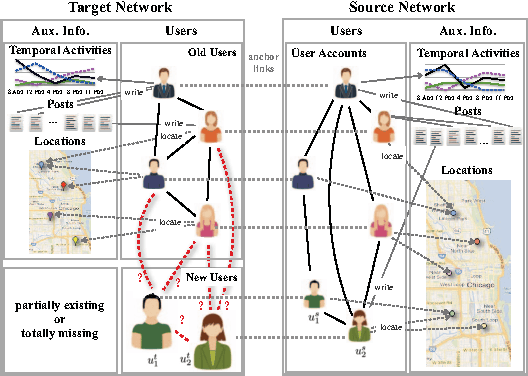
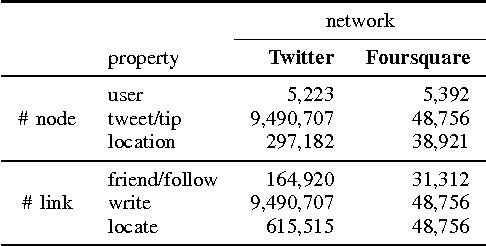
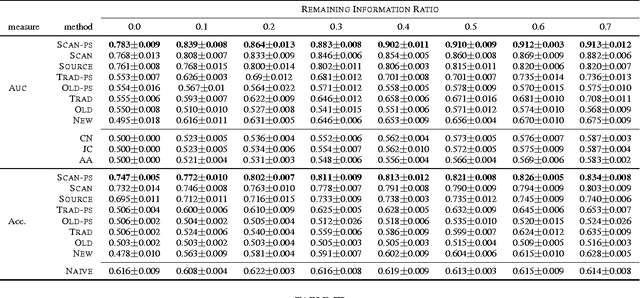
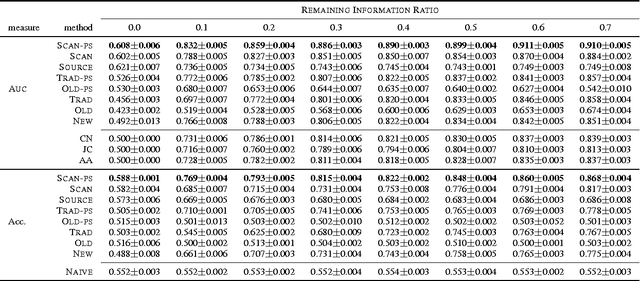
Online social networks have gained great success in recent years and many of them involve multiple kinds of nodes and complex relationships. Among these relationships, social links among users are of great importance. Many existing link prediction methods focus on predicting social links that will appear in the future among all users based upon a snapshot of the social network. In real-world social networks, many new users are joining in the service every day. Predicting links for new users are more important. Different from conventional link prediction problems, link prediction for new users are more challenging due to the following reasons: (1) differences in information distributions between new users and the existing active users (i.e., old users); (2) lack of information from the new users in the network. We propose a link prediction method called SCAN-PS (Supervised Cross Aligned Networks link prediction with Personalized Sampling), to solve the link prediction problem for new users with information transferred from both the existing active users in the target network and other source networks through aligned accounts. We proposed a within-target-network personalized sampling method to process the existing active users' information in order to accommodate the differences in information distributions before the intra-network knowledge transfer. SCAN-PS can also exploit information in other source networks, where the user accounts are aligned with the target network. In this way, SCAN-PS could solve the cold start problem when information of these new users is total absent in the target network.
HeteSim: A General Framework for Relevance Measure in Heterogeneous Networks
Sep 28, 2013
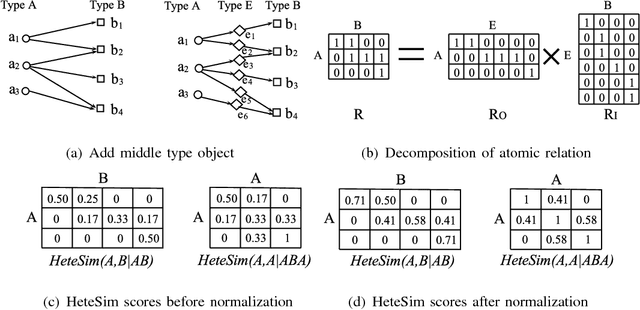

Similarity search is an important function in many applications, which usually focuses on measuring the similarity between objects with the same type. However, in many scenarios, we need to measure the relatedness between objects with different types. With the surge of study on heterogeneous networks, the relevance measure on objects with different types becomes increasingly important. In this paper, we study the relevance search problem in heterogeneous networks, where the task is to measure the relatedness of heterogeneous objects (including objects with the same type or different types). A novel measure HeteSim is proposed, which has the following attributes: (1) a uniform measure: it can measure the relatedness of objects with the same or different types in a uniform framework; (2) a path-constrained measure: the relatedness of object pairs are defined based on the search path that connect two objects through following a sequence of node types; (3) a semi-metric measure: HeteSim has some good properties (e.g., self-maximum and symmetric), that are crucial to many data mining tasks. Moreover, we analyze the computation characteristics of HeteSim and propose the corresponding quick computation strategies. Empirical studies show that HeteSim can effectively and efficiently evaluate the relatedness of heterogeneous objects.
Meta Path-Based Collective Classification in Heterogeneous Information Networks
May 20, 2013
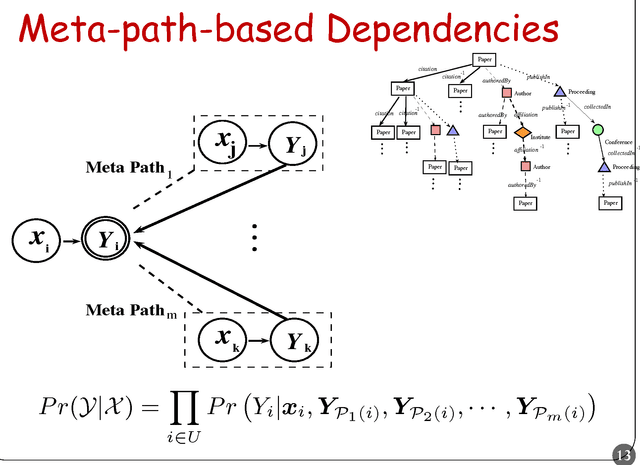
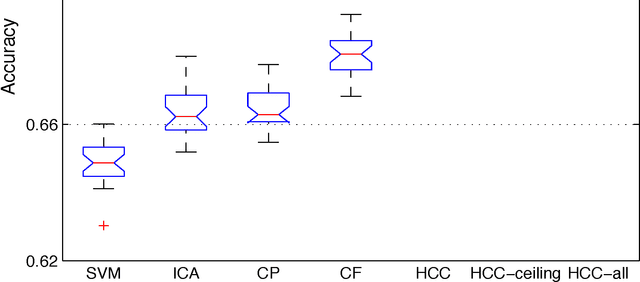
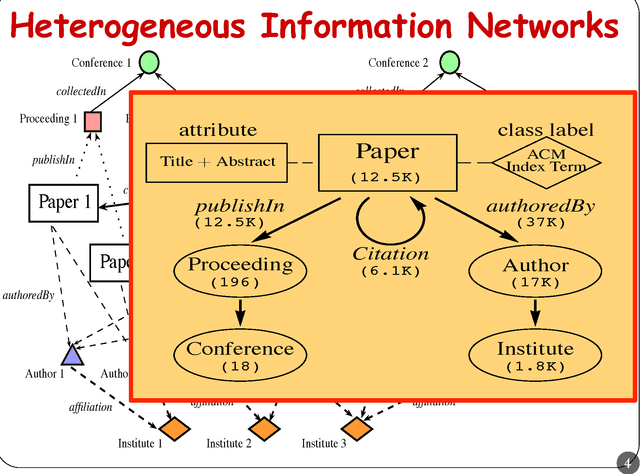
Collective classification has been intensively studied due to its impact in many important applications, such as web mining, bioinformatics and citation analysis. Collective classification approaches exploit the dependencies of a group of linked objects whose class labels are correlated and need to be predicted simultaneously. In this paper, we focus on studying the collective classification problem in heterogeneous networks, which involves multiple types of data objects interconnected by multiple types of links. Intuitively, two objects are correlated if they are linked by many paths in the network. However, most existing approaches measure the dependencies among objects through directly links or indirect links without considering the different semantic meanings behind different paths. In this paper, we study the collective classification problem taht is defined among the same type of objects in heterogenous networks. Moreover, by considering different linkage paths in the network, one can capture the subtlety of different types of dependencies among objects. We introduce the concept of meta-path based dependencies among objects, where a meta path is a path consisting a certain sequence of linke types. We show that the quality of collective classification results strongly depends upon the meta paths used. To accommodate the large network size, a novel solution, called HCC (meta-path based Heterogenous Collective Classification), is developed to effectively assign labels to a group of instances that are interconnected through different meta-paths. The proposed HCC model can capture different types of dependencies among objects with respect to different meta paths. Empirical studies on real-world networks demonstrate that effectiveness of the proposed meta path-based collective classification approach.
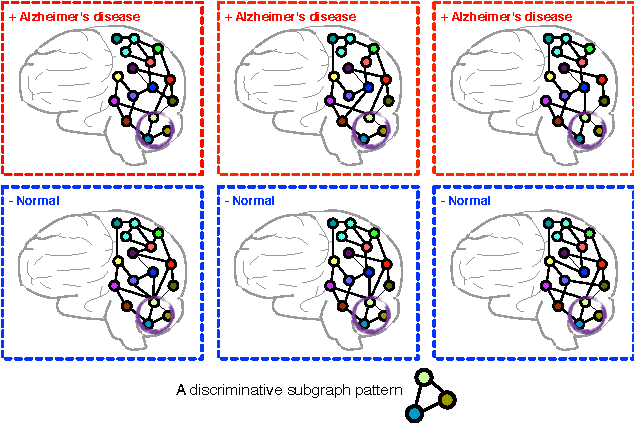
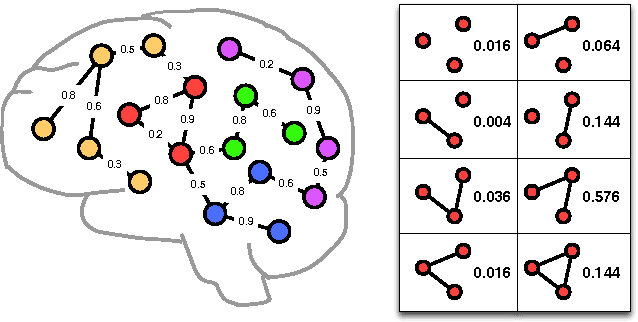
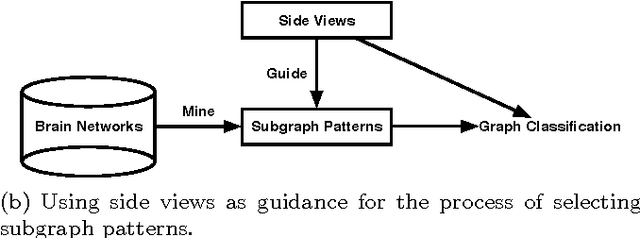
Discriminative Feature Selection for Uncertain Graph Classification
Jan 28, 2013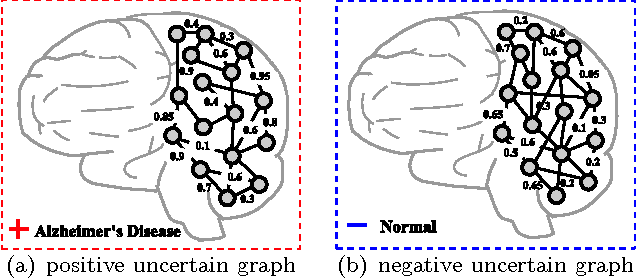

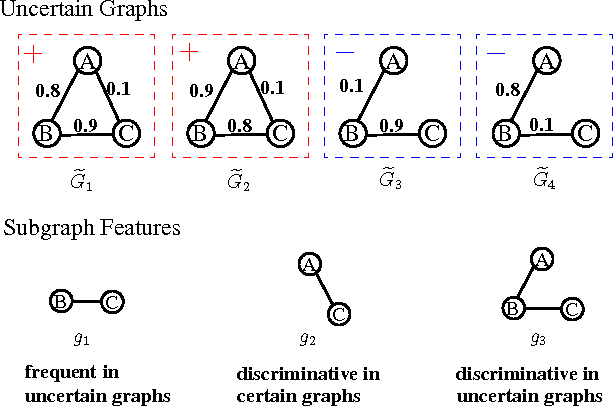

Mining discriminative features for graph data has attracted much attention in recent years due to its important role in constructing graph classifiers, generating graph indices, etc. Most measurement of interestingness of discriminative subgraph features are defined on certain graphs, where the structure of graph objects are certain, and the binary edges within each graph represent the "presence" of linkages among the nodes. In many real-world applications, however, the linkage structure of the graphs is inherently uncertain. Therefore, existing measurements of interestingness based upon certain graphs are unable to capture the structural uncertainty in these applications effectively. In this paper, we study the problem of discriminative subgraph feature selection from uncertain graphs. This problem is challenging and different from conventional subgraph mining problems because both the structure of the graph objects and the discrimination score of each subgraph feature are uncertain. To address these challenges, we propose a novel discriminative subgraph feature selection method, DUG, which can find discriminative subgraph features in uncertain graphs based upon different statistical measures including expectation, median, mode and phi-probability. We first compute the probability distribution of the discrimination scores for each subgraph feature based on dynamic programming. Then a branch-and-bound algorithm is proposed to search for discriminative subgraphs efficiently. Extensive experiments on various neuroimaging applications (i.e., Alzheimer's Disease, ADHD and HIV) have been performed to analyze the gain in performance by taking into account structural uncertainties in identifying discriminative subgraph features for graph classification.