 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Apr 20, 2026Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Here we leveraged a dataset of 3.1 million neurons from the visual cortex of 73 mice across 323 sessions, totaling more than 150 billion neural tokens recorded during natural movies, images and parametric stimuli, and behavior. We train multi-modal, multi-task models that support three regimes flexibly at test time: neural prediction, behavioral decoding, neural forecasting, or any combination of the three. OmniMouse achieves state-of-the-art performance, outperforming specialized baselines across nearly all evaluation regimes. We find that performance scales reliably with more data, but gains from increasing model size saturate. This inverts the standard AI scaling story: in language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling -- even in the mouse visual cortex, a relatively simple system -- models remain data-limited despite vast recordings. The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. Code available at https://github.com/enigma-brain/omnimouse.
Two-argument activation functions learn soft XOR operations like cortical neurons
Oct 15, 2021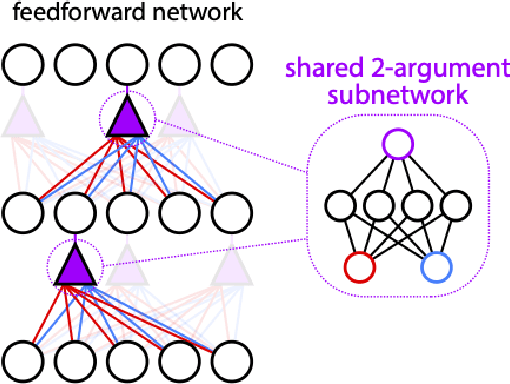
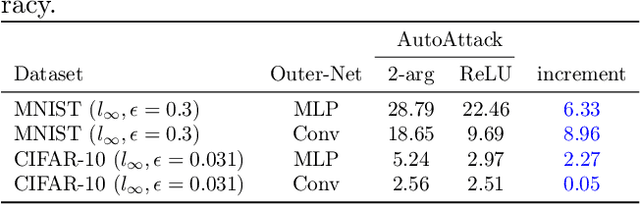
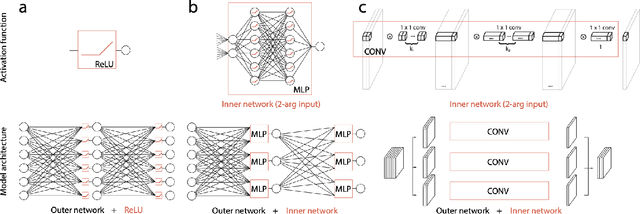
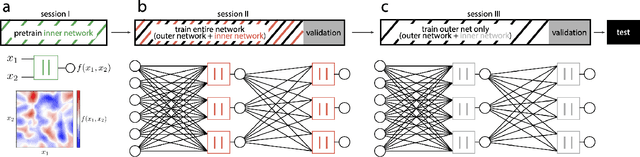
Neurons in the brain are complex machines with distinct functional compartments that interact nonlinearly. In contrast, neurons in artificial neural networks abstract away this complexity, typically down to a scalar activation function of a weighted sum of inputs. Here we emulate more biologically realistic neurons by learning canonical activation functions with two input arguments, analogous to basal and apical dendrites. We use a network-in-network architecture where each neuron is modeled as a multilayer perceptron with two inputs and a single output. This inner perceptron is shared by all units in the outer network. Remarkably, the resultant nonlinearities often produce soft XOR functions, consistent with recent experimental observations about interactions between inputs in human cortical neurons. When hyperparameters are optimized, networks with these nonlinearities learn faster and perform better than conventional ReLU nonlinearities with matched parameter counts, and they are more robust to natural and adversarial perturbations.