 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaFirewall: An open source guardrail system for building secure AI agents
May 06, 2025



Large language models (LLMs) have evolved from simple chatbots into autonomous agents capable of performing complex tasks such as editing production code, orchestrating workflows, and taking higher-stakes actions based on untrusted inputs like webpages and emails. These capabilities introduce new security risks that existing security measures, such as model fine-tuning or chatbot-focused guardrails, do not fully address. Given the higher stakes and the absence of deterministic solutions to mitigate these risks, there is a critical need for a real-time guardrail monitor to serve as a final layer of defense, and support system level, use case specific safety policy definition and enforcement. We introduce LlamaFirewall, an open-source security focused guardrail framework designed to serve as a final layer of defense against security risks associated with AI Agents. Our framework mitigates risks such as prompt injection, agent misalignment, and insecure code risks through three powerful guardrails: PromptGuard 2, a universal jailbreak detector that demonstrates clear state of the art performance; Agent Alignment Checks, a chain-of-thought auditor that inspects agent reasoning for prompt injection and goal misalignment, which, while still experimental, shows stronger efficacy at preventing indirect injections in general scenarios than previously proposed approaches; and CodeShield, an online static analysis engine that is both fast and extensible, aimed at preventing the generation of insecure or dangerous code by coding agents. Additionally, we include easy-to-use customizable scanners that make it possible for any developer who can write a regular expression or an LLM prompt to quickly update an agent's security guardrails.
An Order-Complexity Aesthetic Assessment Model for Aesthetic-aware Music Recommendation
Feb 13, 2024



Computational aesthetic evaluation has made remarkable contribution to visual art works, but its application to music is still rare. Currently, subjective evaluation is still the most effective form of evaluating artistic works. However, subjective evaluation of artistic works will consume a lot of human and material resources. The popular AI generated content (AIGC) tasks nowadays have flooded all industries, and music is no exception. While compared to music produced by humans, AI generated music still sounds mechanical, monotonous, and lacks aesthetic appeal. Due to the lack of music datasets with rating annotations, we have to choose traditional aesthetic equations to objectively measure the beauty of music. In order to improve the quality of AI music generation and further guide computer music production, synthesis, recommendation and other tasks, we use Birkhoff's aesthetic measure to design a aesthetic model, objectively measuring the aesthetic beauty of music, and form a recommendation list according to the aesthetic feeling of music. Experiments show that our objective aesthetic model and recommendation method are effective.
Empowering high-dimensional optical fiber communications with integrated photonic processors
Nov 09, 2023Mode division multiplexing (MDM) in optical fibers enables multichannel capabilities for various applications, including data transmission, quantum networks, imaging, and sensing. However, MDM optical fiber systems, usually necessities bulk-optics approaches for launching different orthogonal fiber modes into the multimode optical fiber, and multiple-input multiple-output digital electronic signal processing at the receiver side to undo the arbitrary mode scrambling in a circular-core optical fiber. Here we show that a high-dimensional optical fiber communication system can be entirely implemented by a reconfigurable integrated photonic processor, featuring kernels of multichannel mode multiplexing transmitter and all-optical descrambling receiver. High-speed and inter-chip communications involving six spatial- and polarization modes have been experimentally demonstrated with high efficiency and high-quality eye diagrams, despite the presence of random mode scrambling and polarization rotation in a circular-core few-mode fiber. The proposed photonic integration approach holds promising prospects for future space-division multiplexing applications.
Teeth And Root Canals Segmentation Using ZXYFormer With Uncertainty Guidance And Weight Transfer
Aug 14, 2023



This study attempts to segment teeth and root-canals simultaneously from CBCT images, but there are very challenging problems in this process. First, the clinical CBCT image data is very large (e.g., 672 *688 * 688), and the use of downsampling operation will lose useful information about teeth and root canals. Second, teeth and root canals are very different in morphology, and it is difficult for a simple network to identify them precisely. In addition, there are weak edges at the tooth, between tooth and root canal, which makes it very difficult to segment such weak edges. To this end, we propose a coarse-to-fine segmentation method based on inverse feature fusion transformer and uncertainty estimation to address above challenging problems. First, we use the downscaled volume data (e.g., 128 * 128 * 128) to conduct coarse segmentation and map it to the original volume to obtain the area of teeth and root canals. Then, we design a transformer with reverse feature fusion, which can bring better segmentation effect of different morphological objects by transferring deeper features to shallow features. Finally, we design an auxiliary branch to calculate and refine the difficult areas in order to improve the weak edge segmentation performance of teeth and root canals. Through the combined tooth and root canal segmentation experiment of 157 clinical high-resolution CBCT data, it is verified that the proposed method is superior to the existing tooth or root canal segmentation methods.
An Order-Complexity Model for Aesthetic Quality Assessment of Homophony Music Performance
Apr 23, 2023



Although computational aesthetics evaluation has made certain achievements in many fields, its research of music performance remains to be explored. At present, subjective evaluation is still a ultimate method of music aesthetics research, but it will consume a lot of human and material resources. In addition, the music performance generated by AI is still mechanical, monotonous and lacking in beauty. In order to guide the generation task of AI music performance, and to improve the performance effect of human performers, this paper uses Birkhoff's aesthetic measure to propose a method of objective measurement of beauty. The main contributions of this paper are as follows: Firstly, we put forward an objective aesthetic evaluation method to measure the music performance aesthetic; Secondly, we propose 10 basic music features and 4 aesthetic music features. Experiments show that our method performs well on performance assessment.
An Order-Complexity Model for Aesthetic Quality Assessment of Symbolic Homophony Music Scores
Jan 14, 2023



Computational aesthetics evaluation has made great achievements in the field of visual arts, but the research work on music still needs to be explored. Although the existing work of music generation is very substantial, the quality of music score generated by AI is relatively poor compared with that created by human composers. The music scores created by AI are usually monotonous and devoid of emotion. Based on Birkhoff's aesthetic measure, this paper proposes an objective quantitative evaluation method for homophony music score aesthetic quality assessment. The main contributions of our work are as follows: first, we put forward a homophony music score aesthetic model to objectively evaluate the quality of music score as a baseline model; second, we put forward eight basic music features and four music aesthetic features.
Aesthetic Visual Question Answering of Photographs
Aug 10, 2022


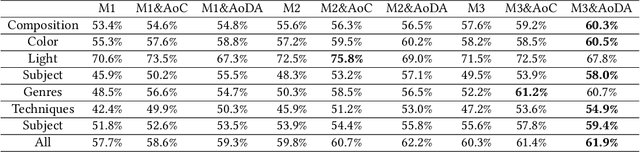
Aesthetic assessment of images can be categorized into two main forms: numerical assessment and language assessment. Aesthetics caption of photographs is the only task of aesthetic language assessment that has been addressed. In this paper, we propose a new task of aesthetic language assessment: aesthetic visual question and answering (AVQA) of images. If we give a question of images aesthetics, model can predict the answer. We use images from \textit{www.flickr.com}. The objective QA pairs are generated by the proposed aesthetic attributes analysis algorithms. Moreover, we introduce subjective QA pairs that are converted from aesthetic numerical labels and sentiment analysis from large-scale pre-train models. We build the first aesthetic visual question answering dataset, AesVQA, that contains 72,168 high-quality images and 324,756 pairs of aesthetic questions. Two methods for adjusting the data distribution have been proposed and proved to improve the accuracy of existing models. This is the first work that both addresses the task of aesthetic VQA and introduces subjectiveness into VQA tasks. The experimental results reveal that our methods outperform other VQA models on this new task.