 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongitudinal Acoustic Speech Tracking Following Pediatric Traumatic Brain Injury
Sep 09, 2022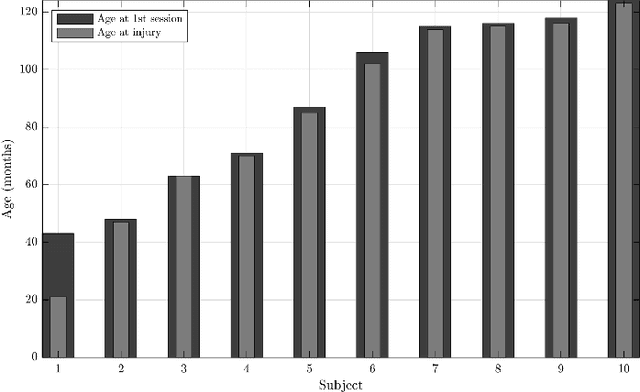
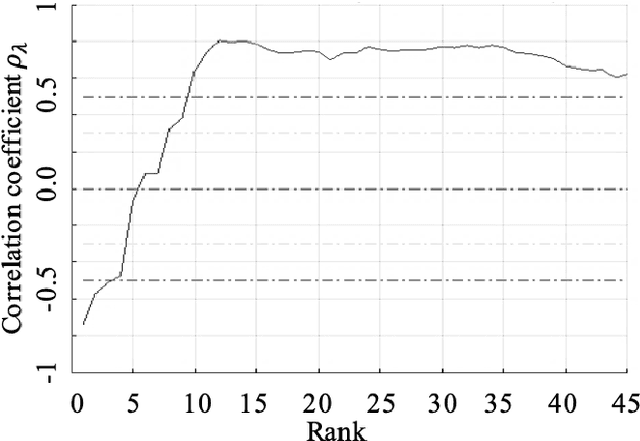
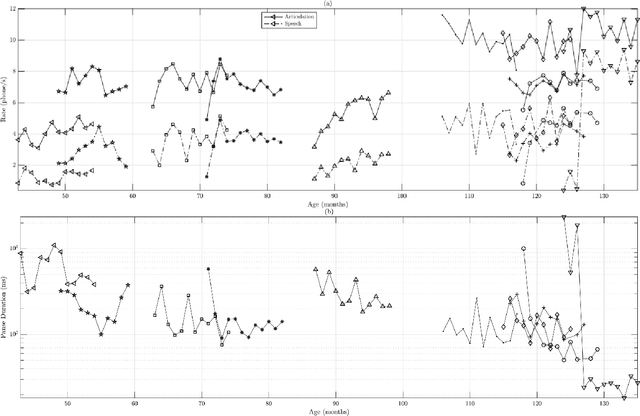
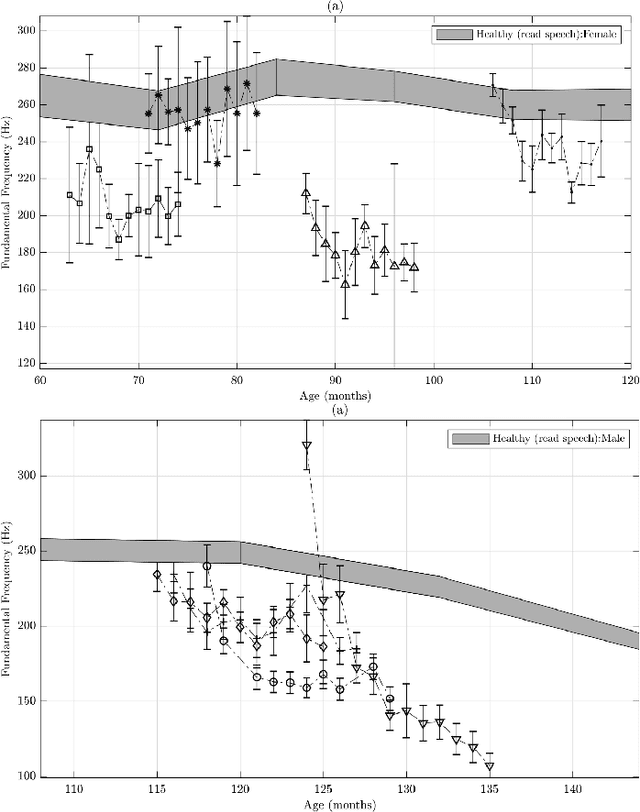
Recommendations for common outcome measures following pediatric traumatic brain injury (TBI) support the integration of instrumental measurements alongside perceptual assessment in recovery and treatment plans. A comprehensive set of sensitive, robust and non-invasive measurements is therefore essential in assessing variations in speech characteristics over time following pediatric TBI. In this article, we study the changes in the acoustic speech patterns of a pediatric cohort of ten subjects diagnosed with severe TBI. We extract a diverse set of both well-known and novel acoustic features from child speech recorded throughout the year after the child produced intelligible words. These features are analyzed individually and by speech subsystem, within-subject and across the cohort. As a group, older children exhibit highly significant (p<0.01) increases in pitch variation and phoneme diversity, shortened pause length, and steadying articulation rate variability. Younger children exhibit similar steadied rate variability alongside an increase in formant-based articulation complexity. Correlation analysis of the feature set with age and comparisons to normative developmental data confirm that age at injury plays a significant role in framing the recovery trajectory. Nearly all speech features significantly change (p<0.05) for the cohort as a whole, confirming that acoustic measures supplementing perceptual assessment are needed to identify efficacious treatment targets for speech therapy following TBI.
Multimodal Sparse Coding for Event Detection
May 17, 2016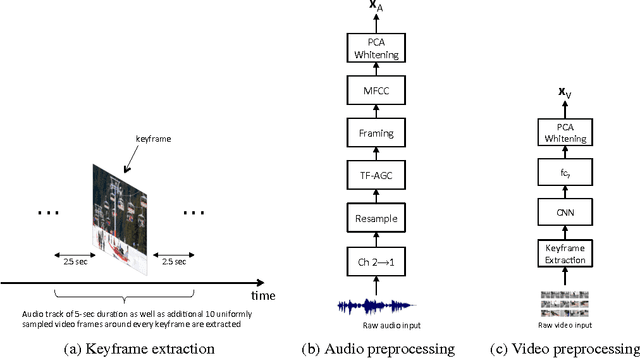
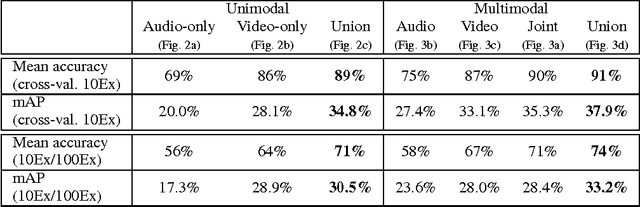
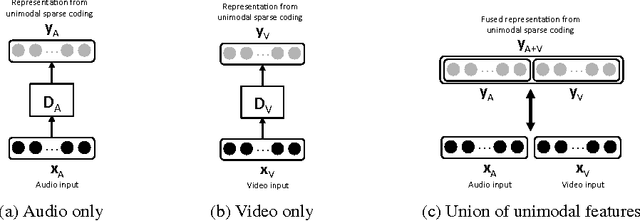
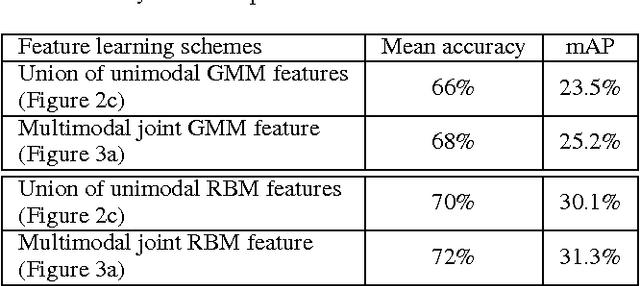
Unsupervised feature learning methods have proven effective for classification tasks based on a single modality. We present multimodal sparse coding for learning feature representations shared across multiple modalities. The shared representations are applied to multimedia event detection (MED) and evaluated in comparison to unimodal counterparts, as well as other feature learning methods such as GMM supervectors and sparse RBM. We report the cross-validated classification accuracy and mean average precision of the MED system trained on features learned from our unimodal and multimodal settings for a subset of the TRECVID MED 2014 dataset.