 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Conformal Anomaly Detection with Time Series Foundation Models for Signal Monitoring
Apr 22, 2026We propose a post-hoc adaptive conformal anomaly detection method for monitoring time series that leverages predictions from pre-trained foundation models without requiring additional fine-tuning. Our method yields an interpretable anomaly score directly interpretable as a false alarm rate (p-value), facilitating transparent and actionable decision-making. It employs weighted quantile conformal prediction bounds and adaptively learns optimal weighting parameters from past predictions, enabling calibration under distribution shifts and stable false alarm control, while preserving out-of-sample guarantees. As a model-agnostic solution, it integrates seamlessly with foundation models and supports rapid deployment in resource-constrained environments. This approach addresses key industrial challenges such as limited data availability, lack of training expertise, and the need for immediate inference, while taking advantage of the growing accessibility of time series foundation models. Experiments on both synthetic and real-world datasets show that the proposed approach delivers strong performance, combining simplicity, interpretability, robustness, and adaptivity.
Revisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models
Feb 06, 2026The recent surge in Time Series Foundation Models has rapidly advanced the field, yet the heterogeneous training setups across studies make it difficult to attribute improvements to architectural innovations versus data engineering. In this work, we investigate the potential of a standard patch Transformer, demonstrating that this generic architecture achieves state-of-the-art zero-shot forecasting performance using a straightforward training protocol. We conduct a comprehensive ablation study that covers model scaling, data composition, and training techniques to isolate the essential ingredients for high performance. Our findings identify the key drivers of performance, while confirming that the generic architecture itself demonstrates excellent scalability. By strictly controlling these variables, we provide comprehensive empirical results on model scaling across multiple dimensions. We release our open-source model and detailed findings to establish a transparent, reproducible baseline for future research.
TSPulse: Dual Space Tiny Pre-Trained Models for Rapid Time-Series Analysis
May 19, 2025



The rise of time-series pre-trained models has advanced temporal representation learning, but current state-of-the-art models are often large-scale, requiring substantial compute. We introduce TSPulse, ultra-compact time-series pre-trained models with only 1M parameters, specialized to perform strongly across classification, anomaly detection, imputation, and retrieval tasks. TSPulse introduces innovations at both the architecture and task levels. At the architecture level, it employs a dual-space masked reconstruction, learning from both time and frequency domains to capture complementary signals. This is further enhanced by a dual-embedding disentanglement, generating both detailed embeddings for fine-grained analysis and high-level semantic embeddings for broader task understanding. Notably, TSPulse's semantic embeddings are robust to shifts in time, magnitude, and noise, which is important for robust retrieval. At the task level, TSPulse incorporates TSLens, a fine-tuning component enabling task-specific feature attention. It also introduces a multi-head triangulation technique that correlates deviations from multiple prediction heads, enhancing anomaly detection by fusing complementary model outputs. Additionally, a hybrid mask pretraining is proposed to improves zero-shot imputation by reducing pre-training bias. These architecture and task innovations collectively contribute to TSPulse's significant performance gains: 5-16% on the UEA classification benchmarks, +20% on the TSB-AD anomaly detection leaderboard, +50% in zero-shot imputation, and +25% in time-series retrieval. Remarkably, these results are achieved with just 1M parameters, making TSPulse 10-100X smaller than existing pre-trained models. Its efficiency enables GPU-free inference and rapid pre-training, setting a new standard for efficient time-series pre-trained models. Models will be open-sourced soon.
Cascading Failure Prediction via Causal Inference
Oct 24, 2024



Causal inference provides an analytical framework to identify and quantify cause-and-effect relationships among a network of interacting agents. This paper offers a novel framework for analyzing cascading failures in power transmission networks. This framework generates a directed latent graph in which the nodes represent the transmission lines and the directed edges encode the cause-effect relationships. This graph has a structure distinct from the system's topology, signifying the intricate fact that both local and non-local interdependencies exist among transmission lines, which are more general than only the local interdependencies that topological graphs can present. This paper formalizes a causal inference framework for predicting how an emerging anomaly propagates throughout the system. Using this framework, two algorithms are designed, providing an analytical framework to identify the most likely and most costly cascading scenarios. The framework's effectiveness is evaluated compared to the pertinent literature on the IEEE 14-bus, 39-bus, and 118-bus systems.
Tiny Time Mixers : Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series
Jan 17, 2024Large pre-trained models for zero/few-shot learning excel in language and vision domains but encounter challenges in multivariate time series (TS) due to the diverse nature and scarcity of publicly available pre-training data. Consequently, there has been a recent surge in utilizing pre-trained large language models (LLMs) with token adaptations for TS forecasting. These approaches employ cross-domain transfer learning and surprisingly yield impressive results. However, these models are typically very slow and large (~billion parameters) and do not consider cross-channel correlations. To address this, we present Tiny Time Mixers (TTM), a significantly small model based on the lightweight TSMixer architecture. TTM marks the first success in developing fast and tiny general pre-trained models (<1M parameters), exclusively trained on public TS datasets, with effective transfer learning capabilities for forecasting. To tackle the complexity of pre-training on multiple datasets with varied temporal resolutions, we introduce several novel enhancements such as adaptive patching, dataset augmentation via downsampling, and resolution prefix tuning. Moreover, we employ a multi-level modeling strategy to effectively model channel correlations and infuse exogenous signals during fine-tuning, a crucial capability lacking in existing benchmarks. TTM shows significant accuracy gains (12-38\%) over popular benchmarks in few/zero-shot forecasting. It also drastically reduces the compute needs as compared to LLM-TS methods, with a 14X cut in learnable parameters, 106X less total parameters, and substantial reductions in fine-tuning (65X) and inference time (54X). In fact, TTM's zero-shot often surpasses the few-shot results in many popular benchmarks, highlighting the efficacy of our approach. Code and pre-trained models will be open-sourced.
Hierarchy-guided Model Selection for Time Series Forecasting
Nov 28, 2022



Generalizability of time series forecasting models depends on the quality of model selection. Temporal cross validation (TCV) is a standard technique to perform model selection in forecasting tasks. TCV sequentially partitions the training time series into train and validation windows, and performs hyperparameter optmization (HPO) of the forecast model to select the model with the best validation performance. Model selection with TCV often leads to poor test performance when the test data distribution differs from that of the validation data. We propose a novel model selection method, H-Pro that exploits the data hierarchy often associated with a time series dataset. Generally, the aggregated data at the higher levels of the hierarchy show better predictability and more consistency compared to the bottom-level data which is more sparse and (sometimes) intermittent. H-Pro performs the HPO of the lowest-level student model based on the test proxy forecasts obtained from a set of teacher models at higher levels in the hierarchy. The consistency of the teachers' proxy forecasts help select better student models at the lowest-level. We perform extensive empirical studies on multiple datasets to validate the efficacy of the proposed method. H-Pro along with off-the-shelf forecasting models outperform existing state-of-the-art forecasting methods including the winning models of the M5 point-forecasting competition.
Generative Adversarial Network for Probabilistic Forecast of Random Dynamical System
Nov 04, 2021
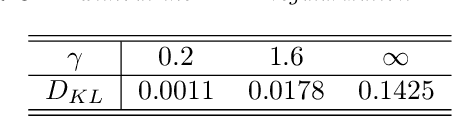
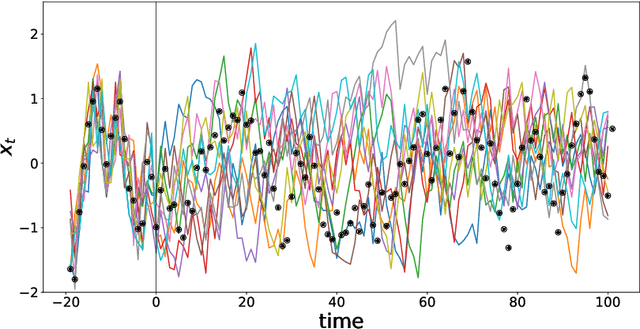
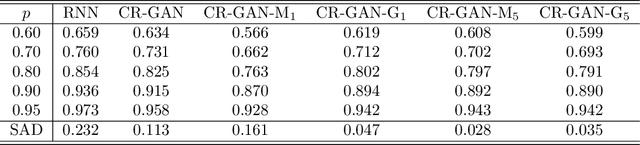
We present a deep learning model for data-driven simulations of random dynamical systems without a distributional assumption. The deep learning model consists of a recurrent neural network, which aims to learn the time marching structure, and a generative adversarial network to learn and sample from the probability distribution of the random dynamical system. Although generative adversarial networks provide a powerful tool to model a complex probability distribution, the training often fails without a proper regularization. Here, we propose a regularization strategy for a generative adversarial network based on consistency conditions for the sequential inference problems. First, the maximum mean discrepancy (MMD) is used to enforce the consistency between conditional and marginal distributions of a stochastic process. Then, the marginal distributions of the multiple-step predictions are regularized by using MMD or from multiple discriminators. The behavior of the proposed model is studied by using three stochastic processes with complex noise structures.
AutoAI-TS: AutoAI for Time Series Forecasting
Mar 08, 2021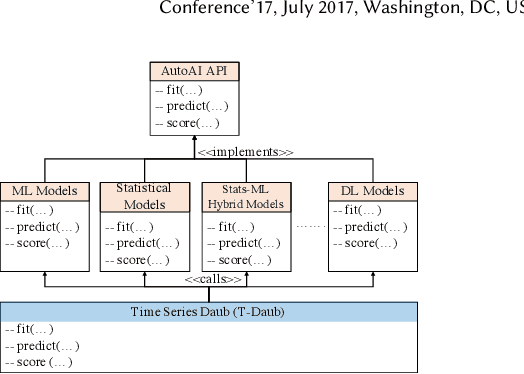
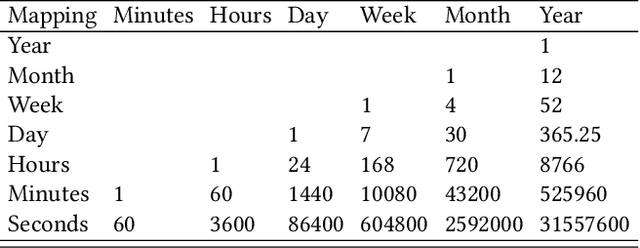
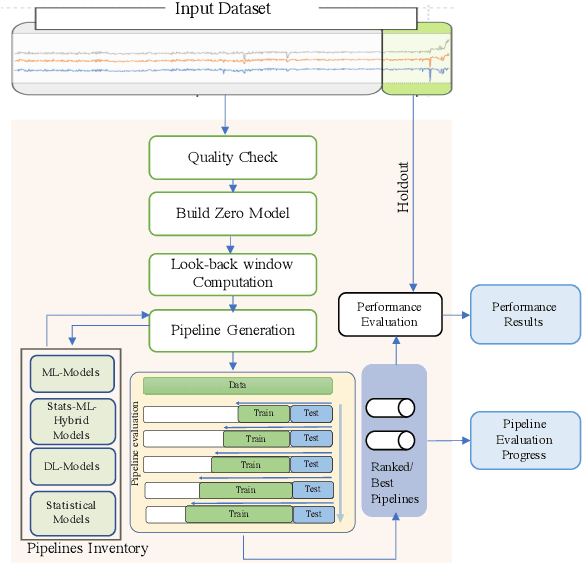
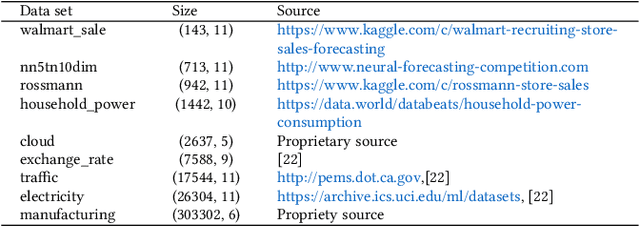
A large number of time series forecasting models including traditional statistical models, machine learning models and more recently deep learning have been proposed in the literature. However, choosing the right model along with good parameter values that performs well on a given data is still challenging. Automatically providing a good set of models to users for a given dataset saves both time and effort from using trial-and-error approaches with a wide variety of available models along with parameter optimization. We present AutoAI for Time Series Forecasting (AutoAI-TS) that provides users with a zero configuration (zero-conf ) system to efficiently train, optimize and choose best forecasting model among various classes of models for the given dataset. With its flexible zero-conf design, AutoAI-TS automatically performs all the data preparation, model creation, parameter optimization, training and model selection for users and provides a trained model that is ready to use. For given data, AutoAI-TS utilizes a wide variety of models including classical statistical models, Machine Learning (ML) models, statistical-ML hybrid models and deep learning models along with various transformations to create forecasting pipelines. It then evaluates and ranks pipelines using the proposed T-Daub mechanism to choose the best pipeline. The paper describe in detail all the technical aspects of AutoAI-TS along with extensive benchmarking on a variety of real world data sets for various use-cases. Benchmark results show that AutoAI-TS, with no manual configuration from the user, automatically trains and selects pipelines that on average outperform existing state-of-the-art time series forecasting toolkits.