 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVD-Preconditioned Gradient Descent Method for Solving Nonlinear Least Squares Problems
Feb 07, 2026This paper introduces a novel optimization algorithm designed for nonlinear least-squares problems. The method is derived by preconditioning the gradient descent direction using the Singular Value Decomposition (SVD) of the Jacobian. This SVD-based preconditioner is then integrated with the first- and second-moment adaptive learning rate mechanism of the Adam optimizer. We establish the local linear convergence of the proposed method under standard regularity assumptions and prove global convergence for a modified version of the algorithm under suitable conditions. The effectiveness of the approach is demonstrated experimentally across a range of tasks, including function approximation, partial differential equation (PDE) solving, and image classification on the CIFAR-10 dataset. Results show that the proposed method consistently outperforms standard Adam, achieving faster convergence and lower error in both regression and classification settings.
Fisher-Informed Parameterwise Aggregation for Federated Learning with Heterogeneous Data
Jan 20, 2026Federated learning aggregates model updates from distributed clients, but standard first order methods such as FedAvg apply the same scalar weight to all parameters from each client. Under non-IID data, these uniformly weighted updates can be strongly misaligned across clients, causing client drift and degrading the global model. Here we propose Fisher-Informed Parameterwise Aggregation (FIPA), a second-order aggregation method that replaces client-level scalar weights with parameter-specific Fisher Information Matrix (FIM) weights, enabling true parameter-level scaling that captures how each client's data uniquely influences different parameters. With low-rank approximation, FIPA remains communication- and computation-efficient. Across nonlinear function regression, PDE learning, and image classification, FIPA consistently improves over averaging-based aggregation, and can be effectively combined with state-of-the-art client-side optimization algorithms to further improve image classification accuracy. These results highlight the benefits of FIPA for federated learning under heterogeneous data distributions.
ZENN: A Thermodynamics-Inspired Computational Framework for Heterogeneous Data-Driven Modeling
May 14, 2025Traditional entropy-based methods - such as cross-entropy loss in classification problems - have long been essential tools for quantifying uncertainty and disorder in data and developing artificial intelligence algorithms. However, the rapid growth of data across various domains has introduced new challenges, particularly the integration of heterogeneous datasets with intrinsic disparities. In this paper, we extend zentropy theory into the data science domain by introducing intrinsic entropy, enabling more effective learning from heterogeneous data sources. We propose a zentropy-enhanced neural network (ZENN) that simultaneously learns both energy and intrinsic entropy components, capturing the underlying structure of multi-source data. To support this, we redesign the neural network architecture to better reflect the intrinsic properties and variability inherent in diverse datasets. We demonstrate the effectiveness of ZENN on classification tasks and energy landscape reconstructions, showing its superior generalization capabilities and robustness-particularly in predicting high-order derivatives. As a practical application, we employ ZENN to reconstruct the Helmholtz energy landscape of Fe3Pt using data generated from DFT and capture key material behaviors, including negative thermal expansion and the critical point in the temperature-pressure space. Overall, our study introduces a novel approach for data-driven machine learning grounded in zentropy theory, highlighting ZENN as a versatile and robust deep learning framework for scientific problems involving complex, heterogeneous datasets.
An Imbalanced Learning-based Sampling Method for Physics-informed Neural Networks
Jan 20, 2025
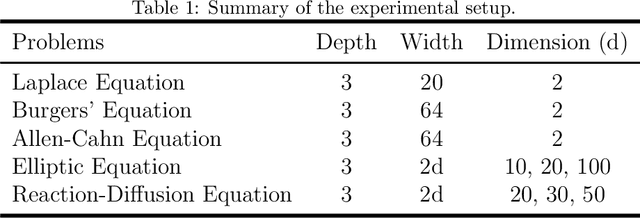


This paper introduces Residual-based Smote (RSmote), an innovative local adaptive sampling technique tailored to improve the performance of Physics-Informed Neural Networks (PINNs) through imbalanced learning strategies. Traditional residual-based adaptive sampling methods, while effective in enhancing PINN accuracy, often struggle with efficiency and high memory consumption, particularly in high-dimensional problems. RSmote addresses these challenges by targeting regions with high residuals and employing oversampling techniques from imbalanced learning to refine the sampling process. Our approach is underpinned by a rigorous theoretical analysis that supports the effectiveness of RSmote in managing computational resources more efficiently. Through extensive evaluations, we benchmark RSmote against the state-of-the-art Residual-based Adaptive Distribution (RAD) method across a variety of dimensions and differential equations. The results demonstrate that RSmote not only achieves or exceeds the accuracy of RAD but also significantly reduces memory usage, making it particularly advantageous in high-dimensional scenarios. These contributions position RSmote as a robust and resource-efficient solution for solving complex partial differential equations, especially when computational constraints are a critical consideration.
Automatic Differentiation is Essential in Training Neural Networks for Solving Differential Equations
May 23, 2024



Neural network-based approaches have recently shown significant promise in solving partial differential equations (PDEs) in science and engineering, especially in scenarios featuring complex domains or the incorporation of empirical data. One advantage of the neural network method for PDEs lies in its automatic differentiation (AD), which necessitates only the sample points themselves, unlike traditional finite difference (FD) approximations that require nearby local points to compute derivatives. In this paper, we quantitatively demonstrate the advantage of AD in training neural networks. The concept of truncated entropy is introduced to characterize the training property. Specifically, through comprehensive experimental and theoretical analyses conducted on random feature models and two-layer neural networks, we discover that the defined truncated entropy serves as a reliable metric for quantifying the residual loss of random feature models and the training speed of neural networks for both AD and FD methods. Our experimental and theoretical analyses demonstrate that, from a training perspective, AD outperforms FD in solving partial differential equations.
Newton Informed Neural Operator for Computing Multiple Solutions of Nonlinear Partials Differential Equations
May 23, 2024



Solving nonlinear partial differential equations (PDEs) with multiple solutions using neural networks has found widespread applications in various fields such as physics, biology, and engineering. However, classical neural network methods for solving nonlinear PDEs, such as Physics-Informed Neural Networks (PINN), Deep Ritz methods, and DeepONet, often encounter challenges when confronted with the presence of multiple solutions inherent in the nonlinear problem. These methods may encounter ill-posedness issues. In this paper, we propose a novel approach called the Newton Informed Neural Operator, which builds upon existing neural network techniques to tackle nonlinearities. Our method combines classical Newton methods, addressing well-posed problems, and efficiently learns multiple solutions in a single learning process while requiring fewer supervised data points compared to existing neural network methods.
Homotopy Relaxation Training Algorithms for Infinite-Width Two-Layer ReLU Neural Networks
Sep 26, 2023In this paper, we present a novel training approach called the Homotopy Relaxation Training Algorithm (HRTA), aimed at accelerating the training process in contrast to traditional methods. Our algorithm incorporates two key mechanisms: one involves building a homotopy activation function that seamlessly connects the linear activation function with the ReLU activation function; the other technique entails relaxing the homotopy parameter to enhance the training refinement process. We have conducted an in-depth analysis of this novel method within the context of the neural tangent kernel (NTK), revealing significantly improved convergence rates. Our experimental results, especially when considering networks with larger widths, validate the theoretical conclusions. This proposed HRTA exhibits the potential for other activation functions and deep neural networks.
HomPINNs: homotopy physics-informed neural networks for solving the inverse problems of nonlinear differential equations with multiple solutions
Apr 06, 2023



Due to the complex behavior arising from non-uniqueness, symmetry, and bifurcations in the solution space, solving inverse problems of nonlinear differential equations (DEs) with multiple solutions is a challenging task. To address this issue, we propose homotopy physics-informed neural networks (HomPINNs), a novel framework that leverages homotopy continuation and neural networks (NNs) to solve inverse problems. The proposed framework begins with the use of a NN to simultaneously approximate known observations and conform to the constraints of DEs. By utilizing the homotopy continuation method, the approximation traces the observations to identify multiple solutions and solve the inverse problem. The experiments involve testing the performance of the proposed method on one-dimensional DEs and applying it to solve a two-dimensional Gray-Scott simulation. Our findings demonstrate that the proposed method is scalable and adaptable, providing an effective solution for solving DEs with multiple solutions and unknown parameters. Moreover, it has significant potential for various applications in scientific computing, such as modeling complex systems and solving inverse problems in physics, chemistry, biology, etc.
Stability Preserving Data-driven Models With Latent Dynamics
Apr 20, 2022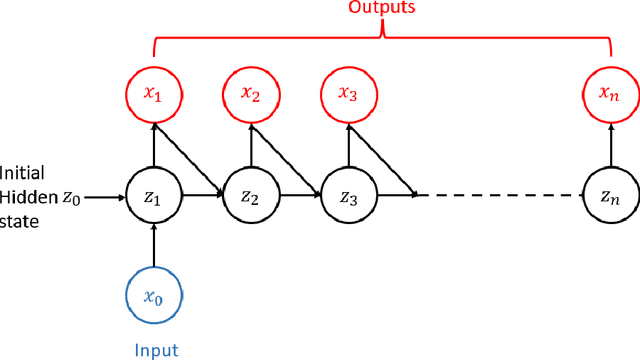
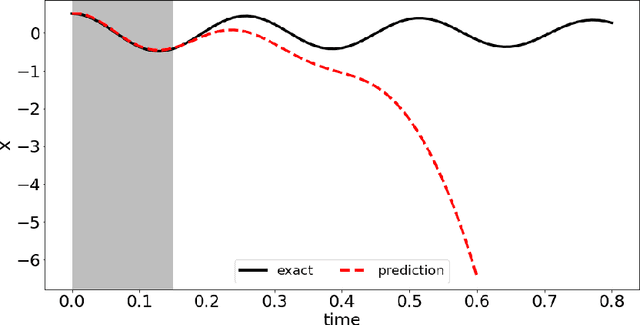
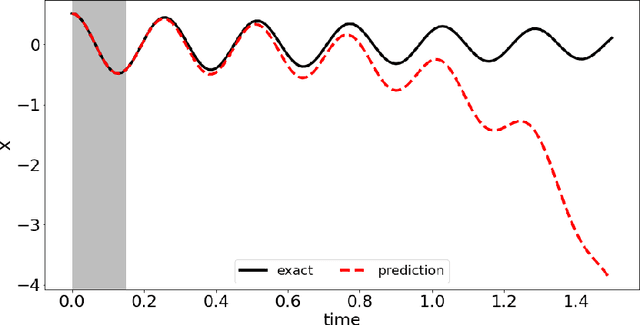
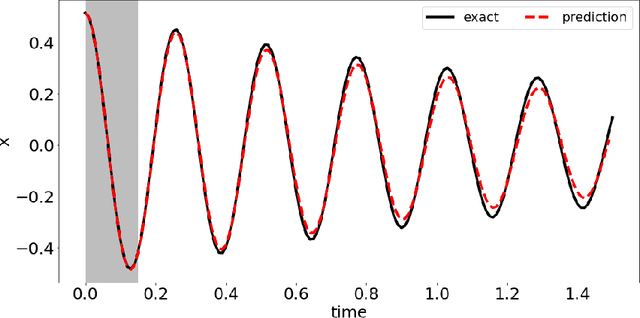
In this paper, we introduce a data-driven modeling approach for dynamics problems with latent variables. The state-space of the proposed model includes artificial latent variables, in addition to observed variables that can be fitted to a given data set. We present a model framework where the stability of the coupled dynamics can be easily enforced. The model is implemented by recurrent cells and trained using backpropagation through time. Numerical examples using benchmark tests from order reduction problems demonstrate the stability of the model and the efficiency of the recurrent cell implementation. As applications, two fluid-structure interaction problems are considered to illustrate the accuracy and predictive capability of the model.
A Weight Initialization Based on the Linear Product Structure for Neural Networks
Sep 01, 2021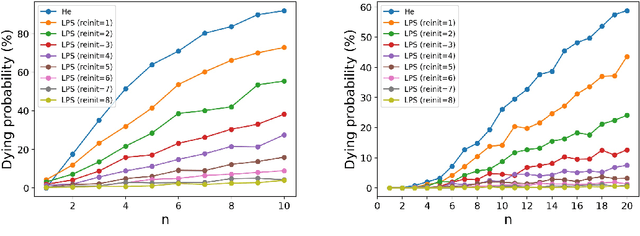

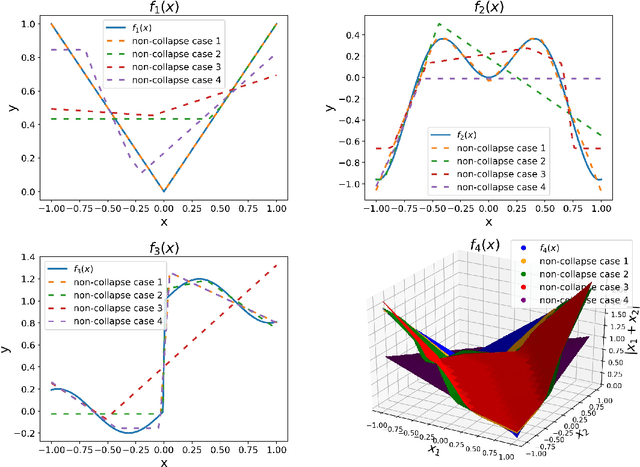
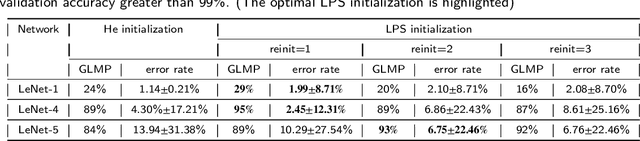
Weight initialization plays an important role in training neural networks and also affects tremendous deep learning applications. Various weight initialization strategies have already been developed for different activation functions with different neural networks. These initialization algorithms are based on minimizing the variance of the parameters between layers and might still fail when neural networks are deep, e.g., dying ReLU. To address this challenge, we study neural networks from a nonlinear computation point of view and propose a novel weight initialization strategy that is based on the linear product structure (LPS) of neural networks. The proposed strategy is derived from the polynomial approximation of activation functions by using theories of numerical algebraic geometry to guarantee to find all the local minima. We also provide a theoretical analysis that the LPS initialization has a lower probability of dying ReLU comparing to other existing initialization strategies. Finally, we test the LPS initialization algorithm on both fully connected neural networks and convolutional neural networks to show its feasibility, efficiency, and robustness on public datasets.