 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossNER: Evaluating Cross-Domain Named Entity Recognition
Dec 13, 2020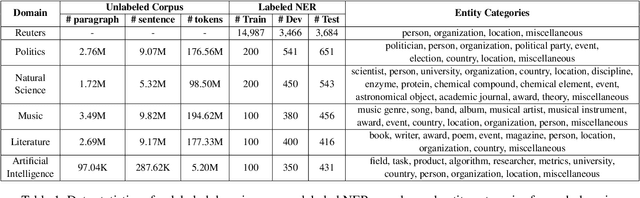
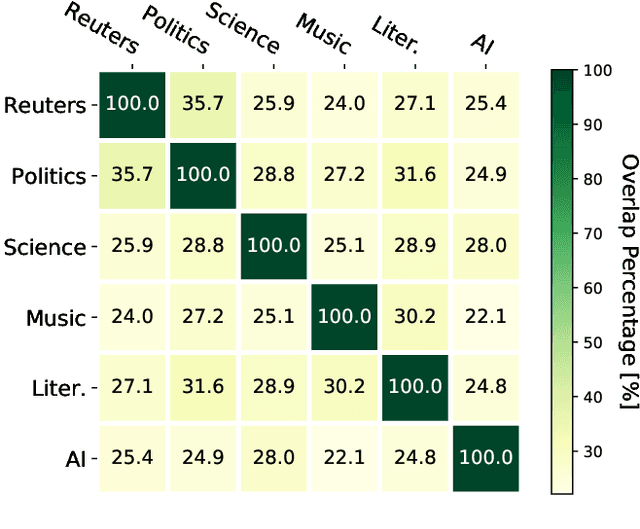
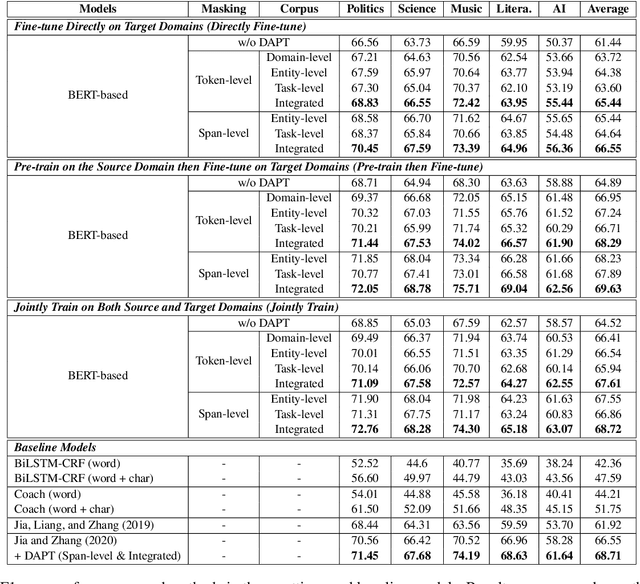
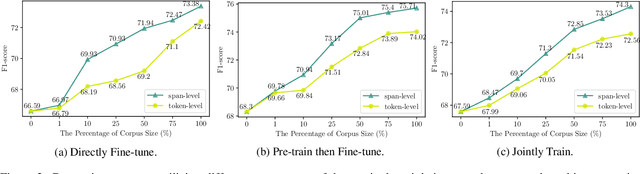
Cross-domain named entity recognition (NER) models are able to cope with the scarcity issue of NER samples in target domains. However, most of the existing NER benchmarks lack domain-specialized entity types or do not focus on a certain domain, leading to a less effective cross-domain evaluation. To address these obstacles, we introduce a cross-domain NER dataset (CrossNER), a fully-labeled collection of NER data spanning over five diverse domains with specialized entity categories for different domains. Additionally, we also provide a domain-related corpus since using it to continue pre-training language models (domain-adaptive pre-training) is effective for the domain adaptation. We then conduct comprehensive experiments to explore the effectiveness of leveraging different levels of the domain corpus and pre-training strategies to do domain-adaptive pre-training for the cross-domain task. Results show that focusing on the fractional corpus containing domain-specialized entities and utilizing a more challenging pre-training strategy in domain-adaptive pre-training are beneficial for the NER domain adaptation, and our proposed method can consistently outperform existing cross-domain NER baselines. Nevertheless, experiments also illustrate the challenge of this cross-domain NER task. We hope that our dataset and baselines will catalyze research in the NER domain adaptation area. The code and data are available at https://github.com/zliucr/CrossNER.
Dimsum @LaySumm 20: BART-based Approach for Scientific Document Summarization
Oct 19, 2020
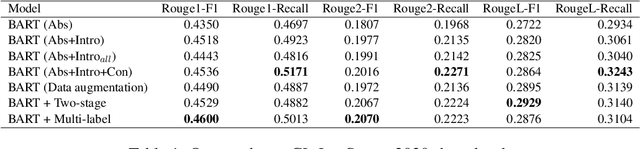
Lay summarization aims to generate lay summaries of scientific papers automatically. It is an essential task that can increase the relevance of science for all of society. In this paper, we build a lay summary generation system based on the BART model. We leverage sentence labels as extra supervision signals to improve the performance of lay summarization. In the CL-LaySumm 2020 shared task, our model achieves 46.00\% Rouge1-F1 score.
Multi-hop Question Generation with Graph Convolutional Network
Oct 19, 2020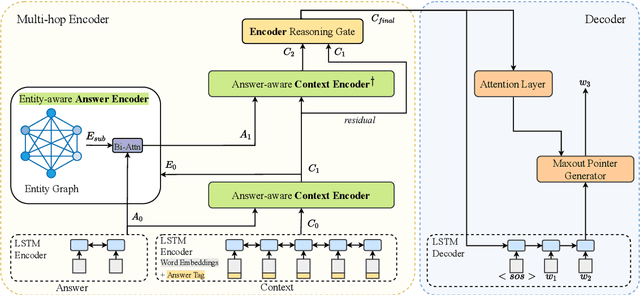
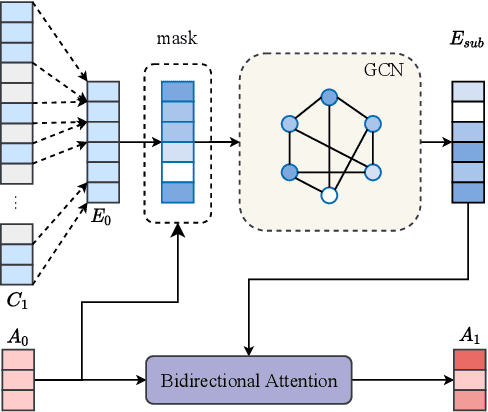
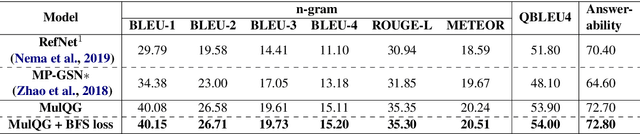
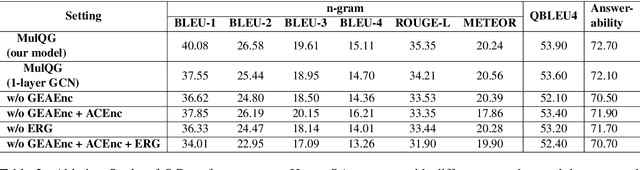
Multi-hop Question Generation (QG) aims to generate answer-related questions by aggregating and reasoning over multiple scattered evidence from different paragraphs. It is a more challenging yet under-explored task compared to conventional single-hop QG, where the questions are generated from the sentence containing the answer or nearby sentences in the same paragraph without complex reasoning. To address the additional challenges in multi-hop QG, we propose Multi-Hop Encoding Fusion Network for Question Generation (MulQG), which does context encoding in multiple hops with Graph Convolutional Network and encoding fusion via an Encoder Reasoning Gate. To the best of our knowledge, we are the first to tackle the challenge of multi-hop reasoning over paragraphs without any sentence-level information. Empirical results on HotpotQA dataset demonstrate the effectiveness of our method, in comparison with baselines on automatic evaluation metrics. Moreover, from the human evaluation, our proposed model is able to generate fluent questions with high completeness and outperforms the strongest baseline by 20.8% in the multi-hop evaluation. The code is publicly available at https://github.com/HLTCHKUST/MulQG}{https://github.com/HLTCHKUST/MulQG .
Modality-Transferable Emotion Embeddings for Low-Resource Multimodal Emotion Recognition
Oct 07, 2020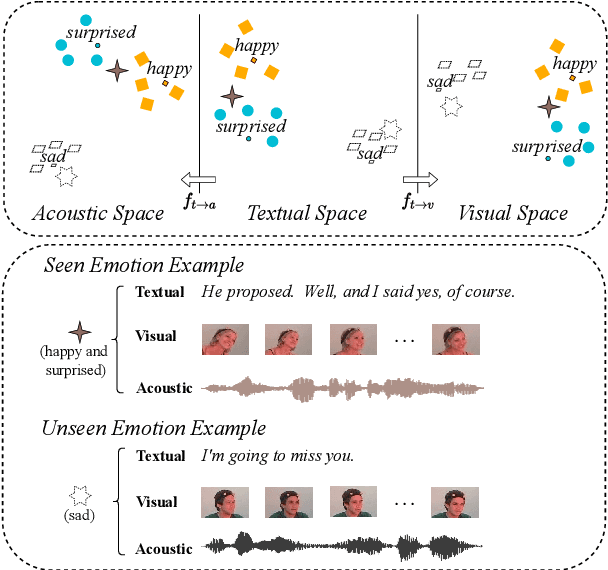

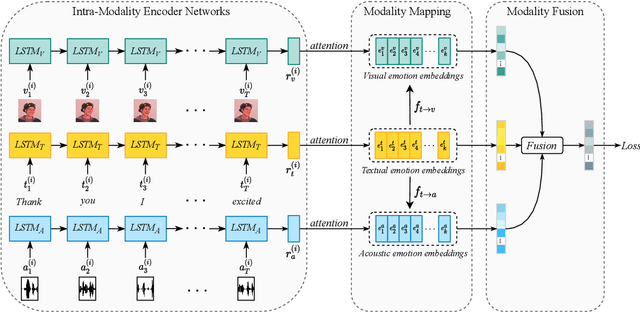
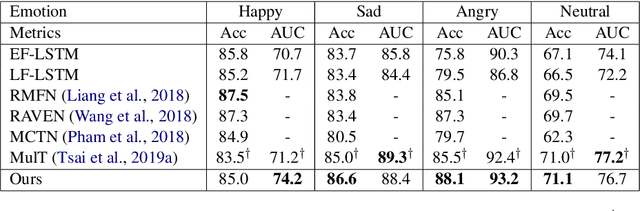
Despite the recent achievements made in the multi-modal emotion recognition task, two problems still exist and have not been well investigated: 1) the relationship between different emotion categories are not utilized, which leads to sub-optimal performance; and 2) current models fail to cope well with low-resource emotions, especially for unseen emotions. In this paper, we propose a modality-transferable model with emotion embeddings to tackle the aforementioned issues. We use pre-trained word embeddings to represent emotion categories for textual data. Then, two mapping functions are learned to transfer these embeddings into visual and acoustic spaces. For each modality, the model calculates the representation distance between the input sequence and target emotions and makes predictions based on the distances. By doing so, our model can directly adapt to the unseen emotions in any modality since we have their pre-trained embeddings and modality mapping functions. Experiments show that our model achieves state-of-the-art performance on most of the emotion categories. In addition, our model also outperforms existing baselines in the zero-shot and few-shot scenarios for unseen emotions.
Kungfupanda at SemEval-2020 Task 12: BERT-Based Multi-Task Learning for Offensive Language Detection
Apr 28, 2020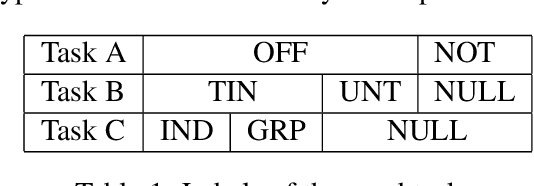
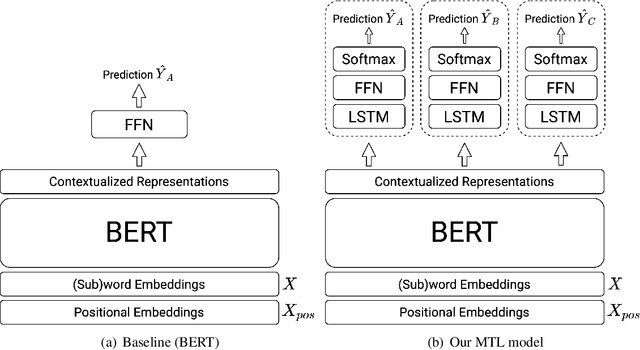
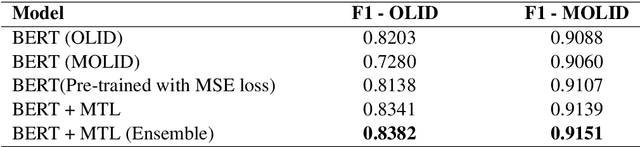
Nowadays, offensive content in social media has become a serious problem, and automatically detecting offensive language is an essential task. In this paper, we build an offensive language detection system, which combines multi-task learning with BERT-based models. Using a pre-trained language model such as BERT, we can effectively learn the representations for noisy text in social media. Besides, to boost the performance of offensive language detection, we leverage the supervision signals from other related tasks. In the OffensEval-2020 competition, our model achieves 91.51% F1 score in English Sub-task A, which is comparable to the first place (92.23%F1). An empirical analysis is provided to explain the effectiveness of our approaches.