 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
DuMLP-Pin: A Dual-MLP-dot-product Permutation-invariant Network for Set Feature Extraction
Mar 08, 2022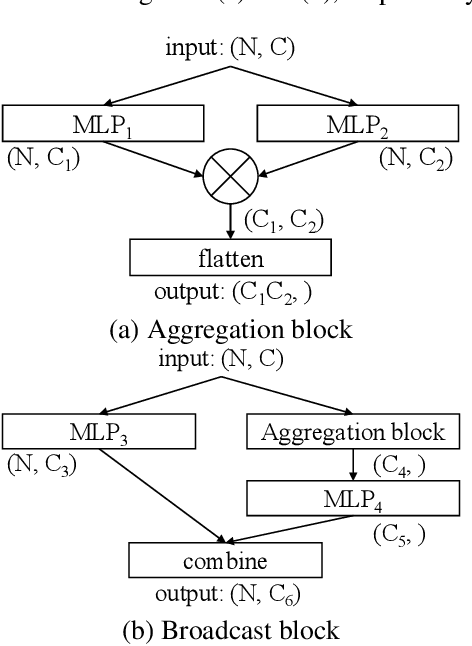
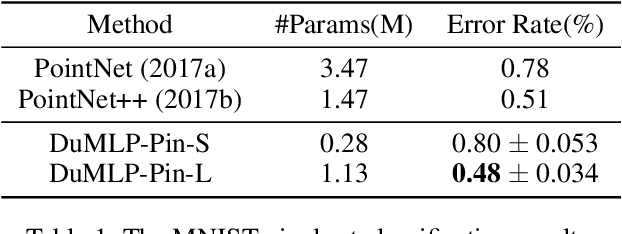
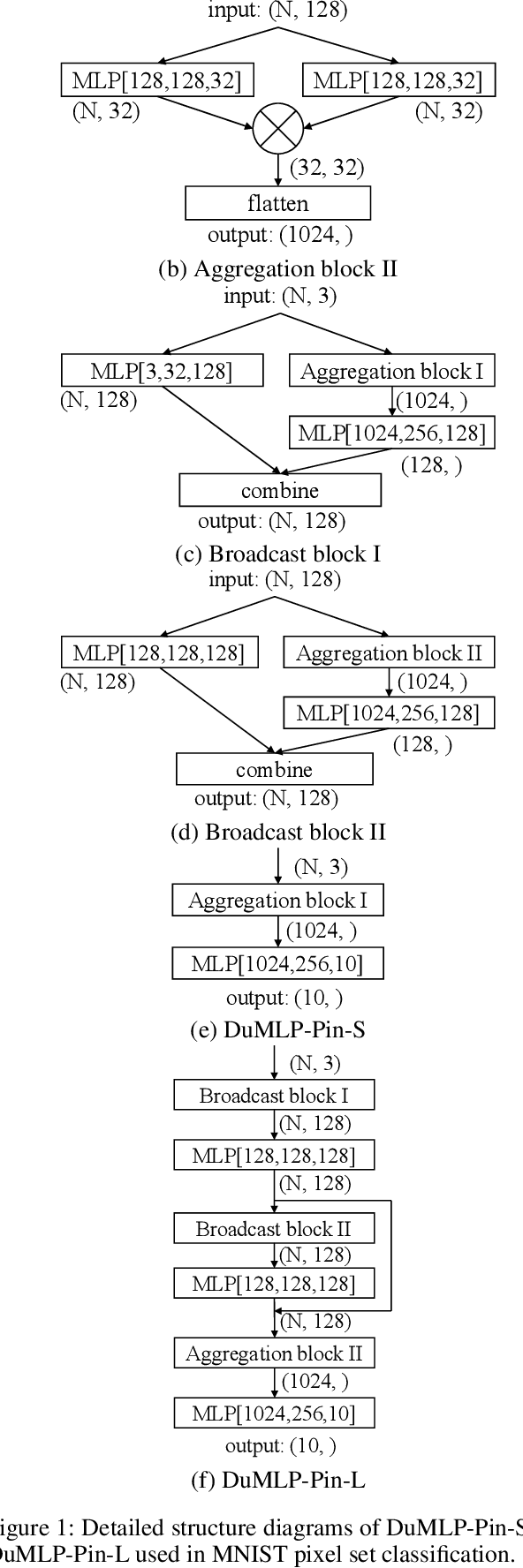
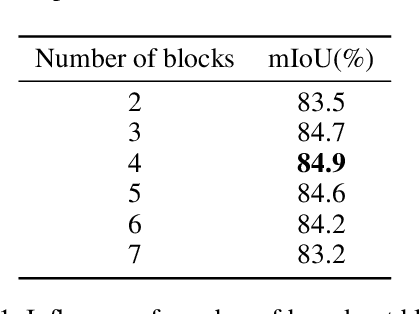
Existing permutation-invariant methods can be divided into two categories according to the aggregation scope, i.e. global aggregation and local one. Although the global aggregation methods, e. g., PointNet and Deep Sets, get involved in simpler structures, their performance is poorer than the local aggregation ones like PointNet++ and Point Transformer. It remains an open problem whether there exists a global aggregation method with a simple structure, competitive performance, and even much fewer parameters. In this paper, we propose a novel global aggregation permutation-invariant network based on dual MLP dot-product, called DuMLP-Pin, which is capable of being employed to extract features for set inputs, including unordered or unstructured pixel, attribute, and point cloud data sets. We strictly prove that any permutation-invariant function implemented by DuMLP-Pin can be decomposed into two or more permutation-equivariant ones in a dot-product way as the cardinality of the given input set is greater than a threshold. We also show that the DuMLP-Pin can be viewed as Deep Sets with strong constraints under certain conditions. The performance of DuMLP-Pin is evaluated on several different tasks with diverse data sets. The experimental results demonstrate that our DuMLP-Pin achieves the best results on the two classification problems for pixel sets and attribute sets. On both the point cloud classification and the part segmentation, the accuracy of DuMLP-Pin is very close to the so-far best-performing local aggregation method with only a 1-2% difference, while the number of required parameters is significantly reduced by more than 85% in classification and 69% in segmentation, respectively. The code is publicly available on https://github.com/JaronTHU/DuMLP-Pin.