 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo: Informativity-Driven Acceleration Plug-In for Vision-Language Models
Dec 12, 2023



Vision-Language Large Models (VLMs) have become primary backbone of AI, due to the impressive performance. However, their expensive computation costs, i.e., throughput and delay, impede potentials in real-world scenarios. To achieve acceleration for VLMs, most existing methods focus on the model perspective: pruning, distillation, quantification, but completely overlook the data-perspective redundancy. To fill the overlook, this paper pioneers the severity of data redundancy, and designs one plug-and-play Turbo module guided by information degree to prune inefficient tokens from visual or textual data. In pursuit of efficiency-performance trade-offs, information degree takes two key factors into consideration: mutual redundancy and semantic value. Concretely, the former evaluates the data duplication between sequential tokens; while the latter evaluates each token by its contribution to the overall semantics. As a result, tokens with high information degree carry less redundancy and stronger semantics. For VLMs' calculation, Turbo works as a user-friendly plug-in that sorts data referring to information degree, utilizing only top-level ones to save costs. Its advantages are multifaceted, e.g., being generally compatible to various VLMs across understanding and generation, simple use without retraining and trivial engineering efforts. On multiple public VLMs benchmarks, we conduct extensive experiments to reveal the gratifying acceleration of Turbo, under negligible performance drop.
Enhancing Cross-domain Click-Through Rate Prediction via Explicit Feature Augmentation
Nov 30, 2023



Cross-domain CTR (CDCTR) prediction is an important research topic that studies how to leverage meaningful data from a related domain to help CTR prediction in target domain. Most existing CDCTR works design implicit ways to transfer knowledge across domains such as parameter-sharing that regularizes the model training in target domain. More effectively, recent researchers propose explicit techniques to extract user interest knowledge and transfer this knowledge to target domain. However, the proposed method mainly faces two issues: 1) it usually requires a super domain, i.e. an extremely large source domain, to cover most users or items of target domain, and 2) the extracted user interest knowledge is static no matter what the context is in target domain. These limitations motivate us to develop a more flexible and efficient technique to explicitly transfer knowledge. In this work, we propose a cross-domain augmentation network (CDAnet) being able to perform explicit knowledge transfer between two domains. Specifically, CDAnet contains a designed translation network and an augmentation network which are trained sequentially. The translation network computes latent features from two domains and learns meaningful cross-domain knowledge of each input in target domain by using a designed cross-supervised feature translator. Later the augmentation network employs the explicit cross-domain knowledge as augmented information to boost the target domain CTR prediction. Through extensive experiments on two public benchmarks and one industrial production dataset, we show CDAnet can learn meaningful translated features and largely improve the performance of CTR prediction. CDAnet has been conducted online A/B test in image2product retrieval at Taobao app, bringing an absolute 0.11 point CTR improvement, a relative 0.64% deal growth and a relative 1.26% GMV increase.
Forgedit: Text Guided Image Editing via Learning and Forgetting
Sep 19, 2023



Text guided image editing on real images given only the image and the target text prompt as inputs, is a very general and challenging problem, which requires the editing model to reason by itself which part of the image should be edited, to preserve the characteristics of original image, and also to perform complicated non-rigid editing. Previous fine-tuning based solutions are time-consuming and vulnerable to overfitting, limiting their editing capabilities. To tackle these issues, we design a novel text guided image editing method, Forgedit. First, we propose a novel fine-tuning framework which learns to reconstruct the given image in less than one minute by vision language joint learning. Then we introduce vector subtraction and vector projection to explore the proper text embedding for editing. We also find a general property of UNet structures in Diffusion Models and inspired by such a finding, we design forgetting strategies to diminish the fatal overfitting issues and significantly boost the editing abilities of Diffusion Models. Our method, Forgedit, implemented with Stable Diffusion, achieves new state-of-the-art results on the challenging text guided image editing benchmark TEdBench, surpassing the previous SOTA method Imagic with Imagen, in terms of both CLIP score and LPIPS score. Codes are available at https://github.com/witcherofresearch/Forgedit.
Cross-domain Augmentation Networks for Click-Through Rate Prediction
May 09, 2023



Data sparsity is an important issue for click-through rate (CTR) prediction, particularly when user-item interactions is too sparse to learn a reliable model. Recently, many works on cross-domain CTR (CDCTR) prediction have been developed in an effort to leverage meaningful data from a related domain. However, most existing CDCTR works have an impractical limitation that requires homogeneous inputs (\textit{i.e.} shared feature fields) across domains, and CDCTR with heterogeneous inputs (\textit{i.e.} varying feature fields) across domains has not been widely explored but is an urgent and important research problem. In this work, we propose a cross-domain augmentation network (CDAnet) being able to perform knowledge transfer between two domains with \textit{heterogeneous inputs}. Specifically, CDAnet contains a designed translation network and an augmentation network which are trained sequentially. The translation network is able to compute features from two domains with heterogeneous inputs separately by designing two independent branches, and then learn meaningful cross-domain knowledge using a designed cross-supervised feature translator. Later the augmentation network encodes the learned cross-domain knowledge via feature translation performed in the latent space and fine-tune the model for final CTR prediction. Through extensive experiments on two public benchmarks and one industrial production dataset, we show CDAnet can learn meaningful translated features and largely improve the performance of CTR prediction. CDAnet has been conducted online A/B test in image2product retrieval at Taobao app over 20days, bringing an absolute \textbf{0.11 point} CTR improvement and a relative \textbf{1.26\%} GMV increase.
Mixer: Image to Multi-Modal Retrieval Learning for Industrial Application
May 06, 2023



Cross-modal retrieval, where the query is an image and the doc is an item with both image and text description, is ubiquitous in e-commerce platforms and content-sharing social media. However, little research attention has been paid to this important application. This type of retrieval task is challenging due to the facts: 1)~domain gap exists between query and doc. 2)~multi-modality alignment and fusion. 3)~skewed training data and noisy labels collected from user behaviors. 4)~huge number of queries and timely responses while the large-scale candidate docs exist. To this end, we propose a novel scalable and efficient image query to multi-modal retrieval learning paradigm called Mixer, which adaptively integrates multi-modality data, mines skewed and noisy data more efficiently and scalable to high traffic. The Mixer consists of three key ingredients: First, for query and doc image, a shared encoder network followed by separate transformation networks are utilized to account for their domain gap. Second, in the multi-modal doc, images and text are not equally informative. So we design a concept-aware modality fusion module, which extracts high-level concepts from the text by a text-to-image attention mechanism. Lastly, but most importantly, we turn to a new data organization and training paradigm for single-modal to multi-modal retrieval: large-scale classification learning which treats single-modal query and multi-modal doc as equivalent samples of certain classes. Besides, the data organization follows a weakly-supervised manner, which can deal with skewed data and noisy labels inherited in the industrial systems. Learning such a large number of categories for real-world multi-modality data is non-trivial and we design a specific learning strategy for it. The proposed Mixer achieves SOTA performance on public datasets from industrial retrieval systems.
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022

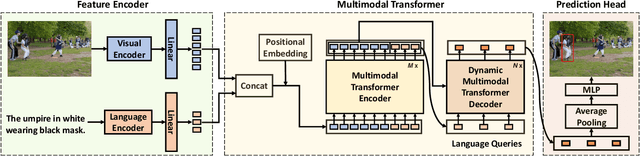
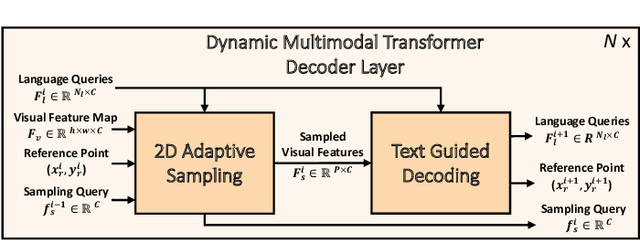
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.
Cross-Architecture Self-supervised Video Representation Learning
May 26, 2022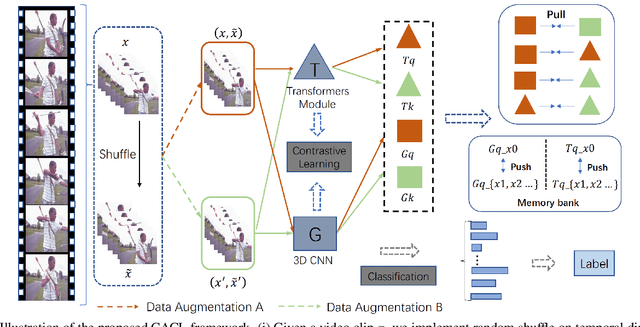
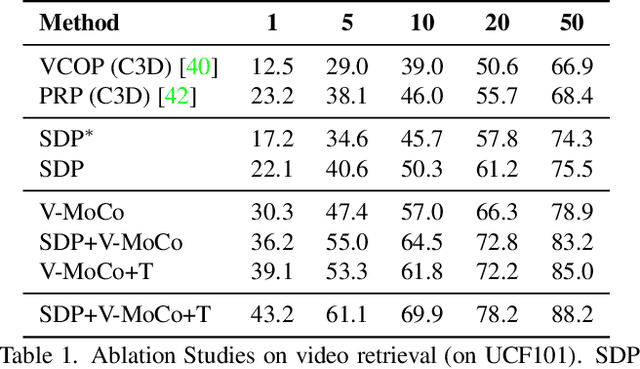
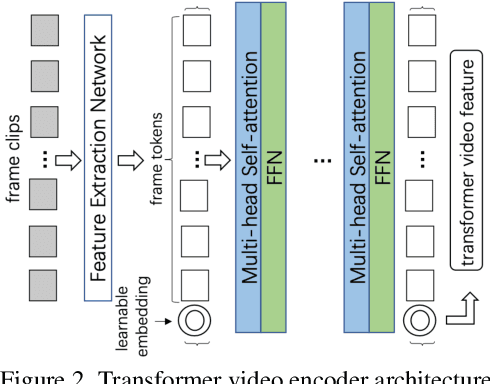
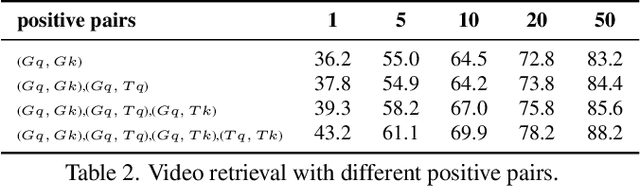
In this paper, we present a new cross-architecture contrastive learning (CACL) framework for self-supervised video representation learning. CACL consists of a 3D CNN and a video transformer which are used in parallel to generate diverse positive pairs for contrastive learning. This allows the model to learn strong representations from such diverse yet meaningful pairs. Furthermore, we introduce a temporal self-supervised learning module able to predict an Edit distance explicitly between two video sequences in the temporal order. This enables the model to learn a rich temporal representation that compensates strongly to the video-level representation learned by the CACL. We evaluate our method on the tasks of video retrieval and action recognition on UCF101 and HMDB51 datasets, where our method achieves excellent performance, surpassing the state-of-the-art methods such as VideoMoCo and MoCo+BE by a large margin. The code is made available at https://github.com/guoshengcv/CACL.
InsCLR: Improving Instance Retrieval with Self-Supervision
Dec 02, 2021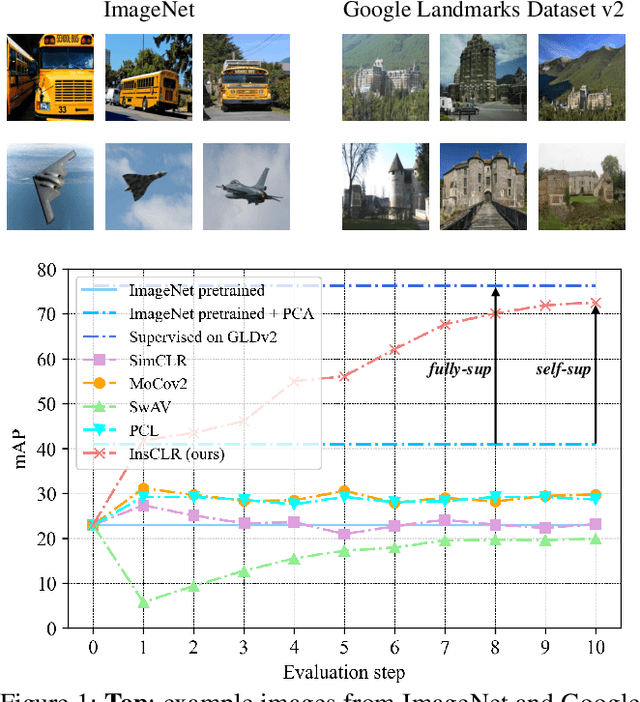
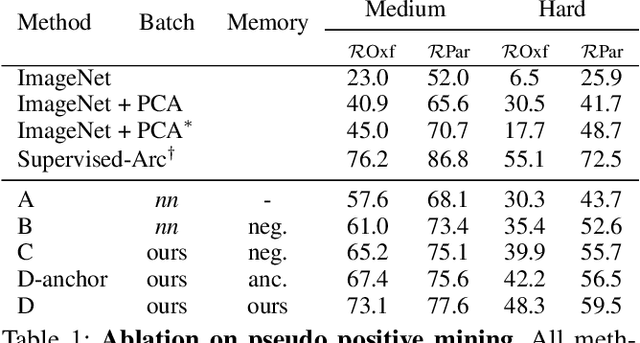
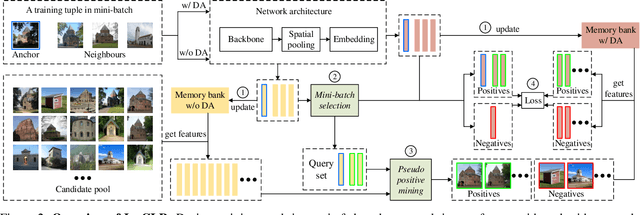
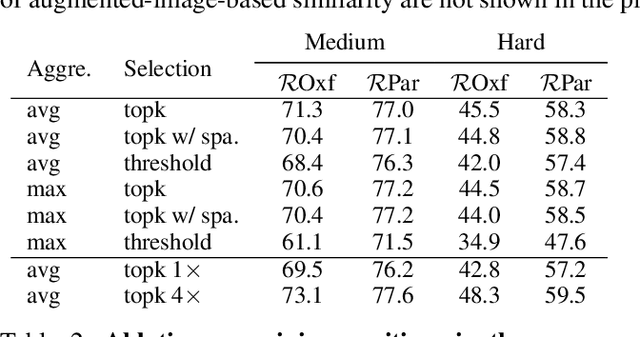
This work aims at improving instance retrieval with self-supervision. We find that fine-tuning using the recently developed self-supervised (SSL) learning methods, such as SimCLR and MoCo, fails to improve the performance of instance retrieval. In this work, we identify that the learnt representations for instance retrieval should be invariant to large variations in viewpoint and background etc., whereas self-augmented positives applied by the current SSL methods can not provide strong enough signals for learning robust instance-level representations. To overcome this problem, we propose InsCLR, a new SSL method that builds on the \textit{instance-level} contrast, to learn the intra-class invariance by dynamically mining meaningful pseudo positive samples from both mini-batches and a memory bank during training. Extensive experiments demonstrate that InsCLR achieves similar or even better performance than the state-of-the-art SSL methods on instance retrieval. Code is available at https://github.com/zeludeng/insclr.
End-to-End Dense Video Grounding via Parallel Regression
Sep 23, 2021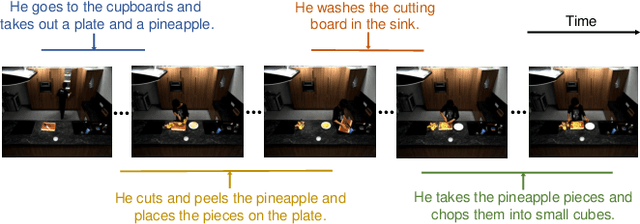



Video grounding aims to localize the corresponding video moment in an untrimmed video given a language query. Existing methods often address this task in an indirect way, by casting it as a proposal-and-match or fusion-and-detection problem. Solving these surrogate problems often requires sophisticated label assignment during training and hand-crafted removal of near-duplicate results. Meanwhile, existing works typically focus on sparse video grounding with a single sentence as input, which could result in ambiguous localization due to its unclear description. In this paper, we tackle a new problem of dense video grounding, by simultaneously localizing multiple moments with a paragraph as input. From a perspective on video grounding as language conditioned regression, we present an end-to-end parallel decoding paradigm by re-purposing a Transformer-alike architecture (PRVG). The key design in our PRVG is to use languages as queries, and directly regress the moment boundaries based on language-modulated visual representations. Thanks to its simplicity in design, our PRVG framework can be applied in different testing schemes (sparse or dense grounding) and allows for efficient inference without any post-processing technique. In addition, we devise a robust proposal-level attention loss to guide the training of PRVG, which is invariant to moment duration and contributes to model convergence. We perform experiments on two video grounding benchmarks of ActivityNet Captions and TACoS, demonstrating that our PRVG can significantly outperform previous methods. We also perform in-depth studies to investigate the effectiveness of parallel regression paradigm on video grounding.
TOOD: Task-aligned One-stage Object Detection
Aug 28, 2021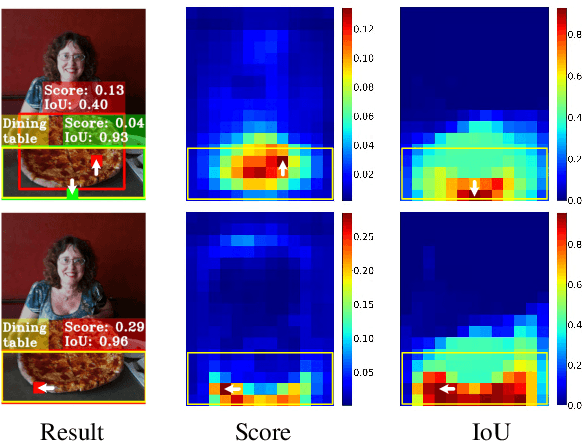
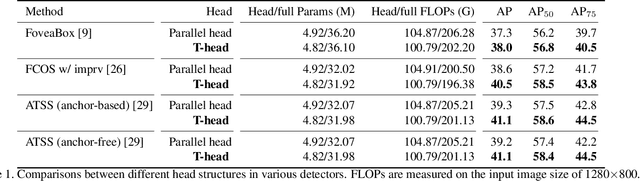
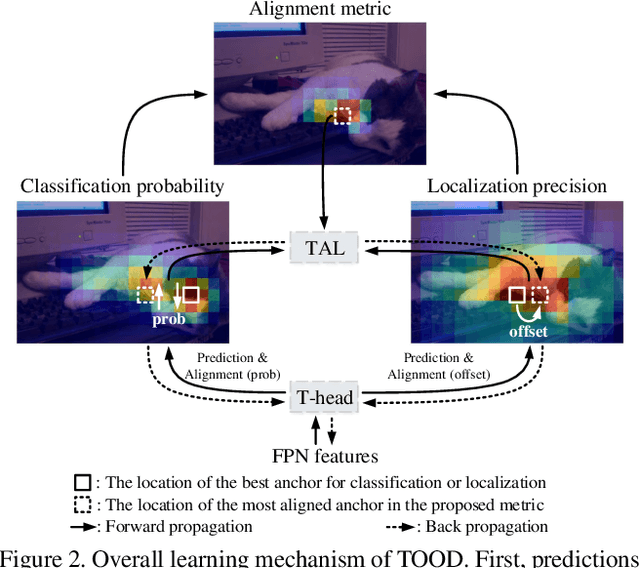
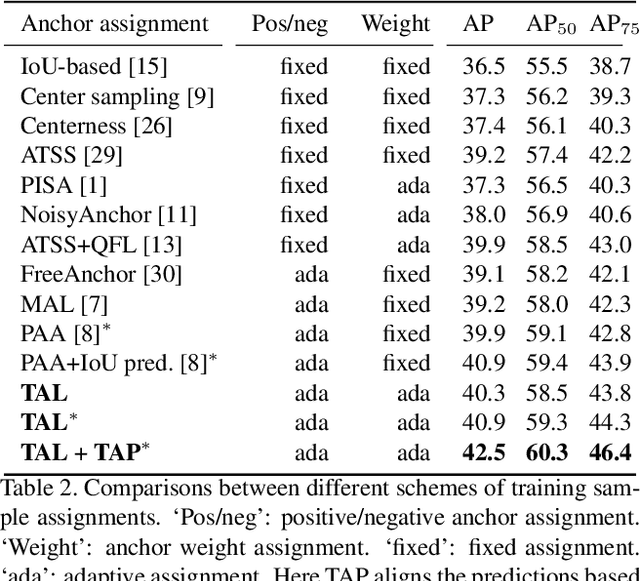
One-stage object detection is commonly implemented by optimizing two sub-tasks: object classification and localization, using heads with two parallel branches, which might lead to a certain level of spatial misalignment in predictions between the two tasks. In this work, we propose a Task-aligned One-stage Object Detection (TOOD) that explicitly aligns the two tasks in a learning-based manner. First, we design a novel Task-aligned Head (T-Head) which offers a better balance between learning task-interactive and task-specific features, as well as a greater flexibility to learn the alignment via a task-aligned predictor. Second, we propose Task Alignment Learning (TAL) to explicitly pull closer (or even unify) the optimal anchors for the two tasks during training via a designed sample assignment scheme and a task-aligned loss. Extensive experiments are conducted on MS-COCO, where TOOD achieves a 51.1 AP at single-model single-scale testing. This surpasses the recent one-stage detectors by a large margin, such as ATSS (47.7 AP), GFL (48.2 AP), and PAA (49.0 AP), with fewer parameters and FLOPs. Qualitative results also demonstrate the effectiveness of TOOD for better aligning the tasks of object classification and localization. Code is available at https://github.com/fcjian/TOOD.