 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Video-Avatar 1.5 Technical Report
May 26, 2026Despite advances in audio-driven video generation, achieving commercial-grade stability remains challenging. We present LongCat-Video-Avatar 1.5, an upgraded open-source framework prioritizing systematic engineering and production-readiness over architectural novelty. By upgrading the audio encoder to Whisper Large and meticulously scaling our training recipes, v1.5 achieves accurate lip-synchronization, full-body temporal stability, and robust long-video generation with strict identity consistency. Through rigorous data curation and RLHF Training, the model readily generalizes to stylized domains such as anime and animals, and natively handles complex real-world conditions, such as multi-person interactions and object handling. Furthermore, addressing the practical demands of industrial deployment, we employ advanced step distillation to accelerate inference to an optimal 8 NFE, achieving a favorable trade-off between serving efficiency and visual fidelity. The superiority of our approach is validated through extensive quantitative metrics and a rigorous human evaluation conducted on a comprehensive benchmark of over 500 diverse test cases. Results show that v1.5 achieves competitive or superior performance compared to leading closed-source systems (e.g., HeyGen, OmniHuman 1.5, Kling Avatar 2.0) across human-likeness ratings and expert-level quality assessments on our benchmark. With its open-source release, LongCat-Video-Avatar 1.5 narrows the gap between academic research prototypes and commercial-grade deployment.
Atrial Fibrillation Detection and ECG Classification based on CNN-BiLSTM
Nov 12, 2020
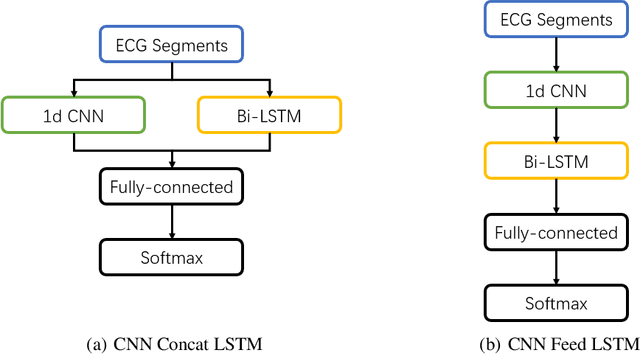
It is challenging to visually detect heart disease from the electrocardiographic (ECG) signals. Implementing an automated ECG signal detection system can help diagnosis arrhythmia in order to improve the accuracy of diagnosis. In this paper, we proposed, implemented, and compared an automated system using two different frameworks of the combination of convolutional neural network (CNN) and long-short term memory (LSTM) for classifying normal sinus signals, atrial fibrillation, and other noisy signals. The dataset we used is from the MIT-BIT Arrhythmia Physionet. Our approach demonstrated that the cascade of two deep learning network has higher performance than the concatenation of them, achieving a weighted f1 score of 0.82. The experimental results have successfully validated that the cascade of CNN and LSTM can achieve satisfactory performance on discriminating ECG signals.