 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedTopo: Topology-Informed Representation Alignment in Federated Learning under Non-I.I.D. Conditions
Nov 16, 2025Current federated-learning models deteriorate under heterogeneous (non-I.I.D.) client data, as their feature representations diverge and pixel- or patch-level objectives fail to capture the global topology which is essential for high-dimensional visual tasks. We propose FedTopo, a framework that integrates Topological-Guided Block Screening (TGBS) and Topological Embedding (TE) to leverage topological information, yielding coherently aligned cross-client representations by Topological Alignment Loss (TAL). First, Topology-Guided Block Screening (TGBS) automatically selects the most topology-informative block, i.e., the one with maximal topological separability, whose persistence-based signatures best distinguish within- versus between-class pairs, ensuring that subsequent analysis focuses on topology-rich features. Next, this block yields a compact Topological Embedding, which quantifies the topological information for each client. Finally, a Topological Alignment Loss (TAL) guides clients to maintain topological consistency with the global model during optimization, reducing representation drift across rounds. Experiments on Fashion-MNIST, CIFAR-10, and CIFAR-100 under four non-I.I.D. partitions show that FedTopo accelerates convergence and improves accuracy over strong baselines.
FedDEAP: Adaptive Dual-Prompt Tuning for Multi-Domain Federated Learning
Oct 21, 2025Federated learning (FL) enables multiple clients to collaboratively train machine learning models without exposing local data, balancing performance and privacy. However, domain shift and label heterogeneity across clients often hinder the generalization of the aggregated global model. Recently, large-scale vision-language models like CLIP have shown strong zero-shot classification capabilities, raising the question of how to effectively fine-tune CLIP across domains in a federated setting. In this work, we propose an adaptive federated prompt tuning framework, FedDEAP, to enhance CLIP's generalization in multi-domain scenarios. Our method includes the following three key components: (1) To mitigate the loss of domain-specific information caused by label-supervised tuning, we disentangle semantic and domain-specific features in images by using semantic and domain transformation networks with unbiased mappings; (2) To preserve domain-specific knowledge during global prompt aggregation, we introduce a dual-prompt design with a global semantic prompt and a local domain prompt to balance shared and personalized information; (3) To maximize the inclusion of semantic and domain information from images in the generated text features, we align textual and visual representations under the two learned transformations to preserve semantic and domain consistency. Theoretical analysis and extensive experiments on four datasets demonstrate the effectiveness of our method in enhancing the generalization of CLIP for federated image recognition across multiple domains.
Using LLMs for Automated Privacy Policy Analysis: Prompt Engineering, Fine-Tuning and Explainability
Mar 16, 2025



Privacy policies are widely used by digital services and often required for legal purposes. Many machine learning based classifiers have been developed to automate detection of different concepts in a given privacy policy, which can help facilitate other automated tasks such as producing a more reader-friendly summary and detecting legal compliance issues. Despite the successful applications of large language models (LLMs) to many NLP tasks in various domains, there is very little work studying the use of LLMs for automated privacy policy analysis, therefore, if and how LLMs can help automate privacy policy analysis remains under-explored. To fill this research gap, we conducted a comprehensive evaluation of LLM-based privacy policy concept classifiers, employing both prompt engineering and LoRA (low-rank adaptation) fine-tuning, on four state-of-the-art (SOTA) privacy policy corpora and taxonomies. Our experimental results demonstrated that combining prompt engineering and fine-tuning can make LLM-based classifiers outperform other SOTA methods, \emph{significantly} and \emph{consistently} across privacy policy corpora/taxonomies and concepts. Furthermore, we evaluated the explainability of the LLM-based classifiers using three metrics: completeness, logicality, and comprehensibility. For all three metrics, a score exceeding 91.1\% was observed in our evaluation, indicating that LLMs are not only useful to improve the classification performance, but also to enhance the explainability of detection results.
"I know myself better, but not really greatly": Using LLMs to Detect and Explain LLM-Generated Texts
Feb 18, 2025Large language models (LLMs) have demonstrated impressive capabilities in generating human-like texts, but the potential misuse of such LLM-generated texts raises the need to distinguish between human-generated and LLM-generated content. This paper explores the detection and explanation capabilities of LLM-based detectors of LLM-generated texts, in the context of a binary classification task (human-generated texts vs LLM-generated texts) and a ternary classification task (human-generated texts, LLM-generated texts, and undecided). By evaluating on six close/open-source LLMs with different sizes, our findings reveal that while self-detection consistently outperforms cross-detection, i.e., LLMs can detect texts generated by themselves more accurately than those generated by other LLMs, the performance of self-detection is still far from ideal, indicating that further improvements are needed. We also show that extending the binary to the ternary classification task with a new class "Undecided" can enhance both detection accuracy and explanation quality, with improvements being statistically significant and consistent across all LLMs. We finally conducted comprehensive qualitative and quantitative analyses on the explanation errors, which are categorized into three types: reliance on inaccurate features (the most frequent error), hallucinations, and incorrect reasoning. These findings with our human-annotated dataset emphasize the need for further research into improving both self-detection and self-explanation, particularly to address overfitting issues that may hinder generalization.
PassTSL: Modeling Human-Created Passwords through Two-Stage Learning
Jul 19, 2024Textual passwords are still the most widely used user authentication mechanism. Due to the close connections between textual passwords and natural languages, advanced technologies in natural language processing (NLP) and machine learning (ML) could be used to model passwords for different purposes such as studying human password-creation behaviors and developing more advanced password cracking methods for informing better defence mechanisms. In this paper, we propose PassTSL (modeling human-created Passwords through Two-Stage Learning), inspired by the popular pretraining-finetuning framework in NLP and deep learning (DL). We report how different pretraining settings affected PassTSL and proved its effectiveness by applying it to six large leaked password databases. Experimental results showed that it outperforms five state-of-the-art (SOTA) password cracking methods on password guessing by a significant margin ranging from 4.11% to 64.69% at the maximum point. Based on PassTSL, we also implemented a password strength meter (PSM), and our experiments showed that it was able to estimate password strength more accurately, causing fewer unsafe errors (overestimating the password strength) than two other SOTA PSMs when they produce the same rate of safe errors (underestimating the password strength): a neural-network based method and zxcvbn. Furthermore, we explored multiple finetuning settings, and our evaluations showed that, even a small amount of additional training data, e.g., only 0.1% of the pretrained data, can lead to over 3% improvement in password guessing on average. We also proposed a heuristic approach to selecting finetuning passwords based on JS (Jensen-Shannon) divergence and experimental results validated its usefulness. In summary, our contributions demonstrate the potential and feasibility of applying advanced NLP and ML methods to password modeling and cracking.
Detecting Machine-Generated Texts: Not Just "AI vs Humans" and Explainability is Complicated
Jun 26, 2024



As LLMs rapidly advance, increasing concerns arise regarding risks about actual authorship of texts we see online and in real world. The task of distinguishing LLM-authored texts is complicated by the nuanced and overlapping behaviors of both machines and humans. In this paper, we challenge the current practice of considering LLM-generated text detection a binary classification task of differentiating human from AI. Instead, we introduce a novel ternary text classification scheme, adding an "undecided" category for texts that could be attributed to either source, and we show that this new category is crucial to understand how to make the detection result more explainable to lay users. This research shifts the paradigm from merely classifying to explaining machine-generated texts, emphasizing need for detectors to provide clear and understandable explanations to users. Our study involves creating four new datasets comprised of texts from various LLMs and human authors. Based on new datasets, we performed binary classification tests to ascertain the most effective SOTA detection methods and identified SOTA LLMs capable of producing harder-to-detect texts. We constructed a new dataset of texts generated by two top-performing LLMs and human authors, and asked three human annotators to produce ternary labels with explanation notes. This dataset was used to investigate how three top-performing SOTA detectors behave in new ternary classification context. Our results highlight why "undecided" category is much needed from the viewpoint of explainability. Additionally, we conducted an analysis of explainability of the three best-performing detectors and the explanation notes of the human annotators, revealing insights about the complexity of explainable detection of machine-generated texts. Finally, we propose guidelines for developing future detection systems with improved explanatory power.
Federated Semi-supervised Learning for Medical Image Segmentation with intra-client and inter-client Consistency
Mar 19, 2024



Medical image segmentation plays a vital role in clinic disease diagnosis and medical image analysis. However, labeling medical images for segmentation task is tough due to the indispensable domain expertise of radiologists. Furthermore, considering the privacy and sensitivity of medical images, it is impractical to build a centralized segmentation dataset from different medical institutions. Federated learning aims to train a shared model of isolated clients without local data exchange which aligns well with the scarcity and privacy characteristics of medical data. To solve the problem of labeling hard, many advanced semi-supervised methods have been proposed in a centralized data setting. As for federated learning, how to conduct semi-supervised learning under this distributed scenario is worth investigating. In this work, we propose a novel federated semi-supervised learning framework for medical image segmentation. The intra-client and inter-client consistency learning are introduced to smooth predictions at the data level and avoid confirmation bias of local models. They are achieved with the assistance of a Variational Autoencoder (VAE) trained collaboratively by clients. The added VAE model plays three roles: 1) extracting latent low-dimensional features of all labeled and unlabeled data; 2) performing a novel type of data augmentation in calculating intra-client consistency loss; 3) utilizing the generative ability of itself to conduct inter-client consistency distillation. The proposed framework is compared with other federated semi-supervised or self-supervised learning methods. The experimental results illustrate that our method outperforms the state-of-the-art method while avoiding a lot of computation and communication overhead.
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
Nov 16, 2023



Mis- and disinformation online have become a major societal problem as major sources of online harms of different kinds. One common form of mis- and disinformation is out-of-context (OOC) information, where different pieces of information are falsely associated, e.g., a real image combined with a false textual caption or a misleading textual description. Although some past studies have attempted to defend against OOC mis- and disinformation through external evidence, they tend to disregard the role of different pieces of evidence with different stances. Motivated by the intuition that the stance of evidence represents a bias towards different detection results, we propose a stance extraction network (SEN) that can extract the stances of different pieces of multi-modal evidence in a unified framework. Moreover, we introduce a support-refutation score calculated based on the co-occurrence relations of named entities into the textual SEN. Extensive experiments on a public large-scale dataset demonstrated that our proposed method outperformed the state-of-the-art baselines, with the best model achieving a performance gain of 3.2% in accuracy.
SE#PCFG: Semantically Enhanced PCFG for Password Analysis and Cracking
Jun 12, 2023



Much research has been done on user-generated textual passwords. Surprisingly, semantic information in such passwords remain underinvestigated, with passwords created by English- and/or Chinese-speaking users being more studied with limited semantics. This paper fills this gap by proposing a general framework based on semantically enhanced PCFG (probabilistic context-free grammars) named SE#PCFG. It allowed us to consider 43 types of semantic information, the richest set considered so far, for semantic password analysis. Applying SE#PCFG to 17 large leaked password databases of user speaking four languages (English, Chinese, German and French), we demonstrate its usefulness and report a wide range of new insights about password semantics at different levels such as cross-website password correlations. Furthermore, based on SE#PCFG and a new systematic smoothing method, we proposed the Semantically Enhanced Password Cracking Architecture (SEPCA). To compare the performance of SEPCA against three state-of-the-art (SOTA) benchmarks in terms of the password coverage rate: two other PCFG variants and FLA. Our experimental results showed that SEPCA outperformed all the three benchmarks consistently and significantly across 52 test cases, by up to 21.53%, 52.55% and 7.86%, respectively, at the user level (with duplicate passwords). At the level of unique passwords, SEPCA also beats the three benchmarks by up to 33.32%, 86.19% and 10.46%, respectively. The results demonstrated the power of SEPCA as a new password cracking framework.
Scale Invariant Domain Generalization Image Recapture Detection
Oct 07, 2021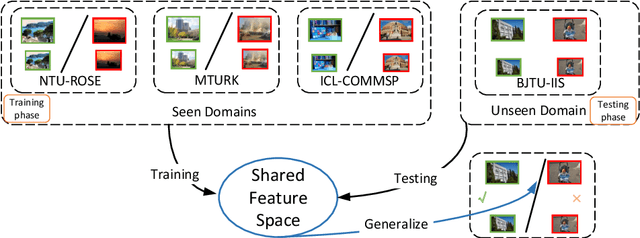

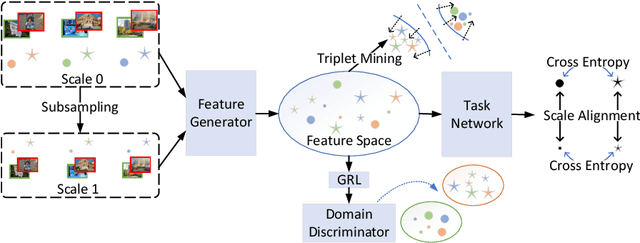
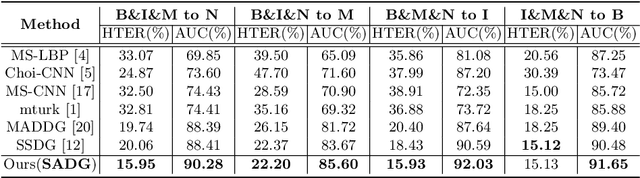
Recapturing and rebroadcasting of images are common attack methods in insurance frauds and face identification spoofing, and an increasing number of detection techniques were introduced to handle this problem. However, most of them ignored the domain generalization scenario and scale variances, with an inferior performance on domain shift situations, and normally were exacerbated by intra-domain and inter-domain scale variances. In this paper, we propose a scale alignment domain generalization framework (SADG) to address these challenges. First, an adversarial domain discriminator is exploited to minimize the discrepancies of image representation distributions among different domains. Meanwhile, we exploit triplet loss as a local constraint to achieve a clearer decision boundary. Moreover, a scale alignment loss is introduced as a global relationship regularization to force the image representations of the same class across different scales to be undistinguishable. Experimental results on four databases and comparison with state-of-the-art approaches show that better performance can be achieved using our framework.