 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtBank: Artistic Style Transfer with Pre-trained Diffusion Model and Implicit Style Prompt Bank
Dec 11, 2023



Artistic style transfer aims to repaint the content image with the learned artistic style. Existing artistic style transfer methods can be divided into two categories: small model-based approaches and pre-trained large-scale model-based approaches. Small model-based approaches can preserve the content strucuture, but fail to produce highly realistic stylized images and introduce artifacts and disharmonious patterns; Pre-trained large-scale model-based approaches can generate highly realistic stylized images but struggle with preserving the content structure. To address the above issues, we propose ArtBank, a novel artistic style transfer framework, to generate highly realistic stylized images while preserving the content structure of the content images. Specifically, to sufficiently dig out the knowledge embedded in pre-trained large-scale models, an Implicit Style Prompt Bank (ISPB), a set of trainable parameter matrices, is designed to learn and store knowledge from the collection of artworks and behave as a visual prompt to guide pre-trained large-scale models to generate highly realistic stylized images while preserving content structure. Besides, to accelerate training the above ISPB, we propose a novel Spatial-Statistical-based self-Attention Module (SSAM). The qualitative and quantitative experiments demonstrate the superiority of our proposed method over state-of-the-art artistic style transfer methods.
Multi-Resolution Active Learning of Fourier Neural Operators
Oct 08, 2023



Fourier Neural Operator (FNO) is a popular operator learning framework, which not only achieves the state-of-the-art performance in many tasks, but also is highly efficient in training and prediction. However, collecting training data for the FNO is a costly bottleneck in practice, because it often demands expensive physical simulations. To overcome this problem, we propose Multi-Resolution Active learning of FNO (MRA-FNO), which can dynamically select the input functions and resolutions to lower the data cost as much as possible while optimizing the learning efficiency. Specifically, we propose a probabilistic multi-resolution FNO and use ensemble Monte-Carlo to develop an effective posterior inference algorithm. To conduct active learning, we maximize a utility-cost ratio as the acquisition function to acquire new examples and resolutions at each step. We use moment matching and the matrix determinant lemma to enable tractable, efficient utility computation. Furthermore, we develop a cost annealing framework to avoid over-penalizing high-resolution queries at the early stage. The over-penalization is severe when the cost difference is significant between the resolutions, which renders active learning often stuck at low-resolution queries and inferior performance. Our method overcomes this problem and applies to general multi-fidelity active learning and optimization problems. We have shown the advantage of our method in several benchmark operator learning tasks.
StyleDiffusion: Controllable Disentangled Style Transfer via Diffusion Models
Aug 15, 2023



Content and style (C-S) disentanglement is a fundamental problem and critical challenge of style transfer. Existing approaches based on explicit definitions (e.g., Gram matrix) or implicit learning (e.g., GANs) are neither interpretable nor easy to control, resulting in entangled representations and less satisfying results. In this paper, we propose a new C-S disentangled framework for style transfer without using previous assumptions. The key insight is to explicitly extract the content information and implicitly learn the complementary style information, yielding interpretable and controllable C-S disentanglement and style transfer. A simple yet effective CLIP-based style disentanglement loss coordinated with a style reconstruction prior is introduced to disentangle C-S in the CLIP image space. By further leveraging the powerful style removal and generative ability of diffusion models, our framework achieves superior results than state of the art and flexible C-S disentanglement and trade-off control. Our work provides new insights into the C-S disentanglement in style transfer and demonstrates the potential of diffusion models for learning well-disentangled C-S characteristics.
VGOS: Voxel Grid Optimization for View Synthesis from Sparse Inputs
Apr 26, 2023



Neural Radiance Fields (NeRF) has shown great success in novel view synthesis due to its state-of-the-art quality and flexibility. However, NeRF requires dense input views (tens to hundreds) and a long training time (hours to days) for a single scene to generate high-fidelity images. Although using the voxel grids to represent the radiance field can significantly accelerate the optimization process, we observe that for sparse inputs, the voxel grids are more prone to overfitting to the training views and will have holes and floaters, which leads to artifacts. In this paper, we propose VGOS, an approach for fast (3-5 minutes) radiance field reconstruction from sparse inputs (3-10 views) to address these issues. To improve the performance of voxel-based radiance field in sparse input scenarios, we propose two methods: (a) We introduce an incremental voxel training strategy, which prevents overfitting by suppressing the optimization of peripheral voxels in the early stage of reconstruction. (b) We use several regularization techniques to smooth the voxels, which avoids degenerate solutions. Experiments demonstrate that VGOS achieves state-of-the-art performance for sparse inputs with super-fast convergence. Code will be available at https://github.com/SJoJoK/VGOS.
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Mar 23, 2023



This paper presents a new adversarial training framework for image inpainting with segmentation confusion adversarial training (SCAT) and contrastive learning. SCAT plays an adversarial game between an inpainting generator and a segmentation network, which provides pixel-level local training signals and can adapt to images with free-form holes. By combining SCAT with standard global adversarial training, the new adversarial training framework exhibits the following three advantages simultaneously: (1) the global consistency of the repaired image, (2) the local fine texture details of the repaired image, and (3) the flexibility of handling images with free-form holes. Moreover, we propose the textural and semantic contrastive learning losses to stabilize and improve our inpainting model's training by exploiting the feature representation space of the discriminator, in which the inpainting images are pulled closer to the ground truth images but pushed farther from the corrupted images. The proposed contrastive losses better guide the repaired images to move from the corrupted image data points to the real image data points in the feature representation space, resulting in more realistic completed images. We conduct extensive experiments on two benchmark datasets, demonstrating our model's effectiveness and superiority both qualitatively and quantitatively.
MicroAST: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer
Nov 28, 2022



Arbitrary style transfer (AST) transfers arbitrary artistic styles onto content images. Despite the recent rapid progress, existing AST methods are either incapable or too slow to run at ultra-resolutions (e.g., 4K) with limited resources, which heavily hinders their further applications. In this paper, we tackle this dilemma by learning a straightforward and lightweight model, dubbed MicroAST. The key insight is to completely abandon the use of cumbersome pre-trained Deep Convolutional Neural Networks (e.g., VGG) at inference. Instead, we design two micro encoders (content and style encoders) and one micro decoder for style transfer. The content encoder aims at extracting the main structure of the content image. The style encoder, coupled with a modulator, encodes the style image into learnable dual-modulation signals that modulate both intermediate features and convolutional filters of the decoder, thus injecting more sophisticated and flexible style signals to guide the stylizations. In addition, to boost the ability of the style encoder to extract more distinct and representative style signals, we also introduce a new style signal contrastive loss in our model. Compared to the state of the art, our MicroAST not only produces visually superior results but also is 5-73 times smaller and 6-18 times faster, for the first time enabling super-fast (about 0.5 seconds) AST at 4K ultra-resolutions. Code is available at https://github.com/EndyWon/MicroAST.
AesUST: Towards Aesthetic-Enhanced Universal Style Transfer
Aug 27, 2022

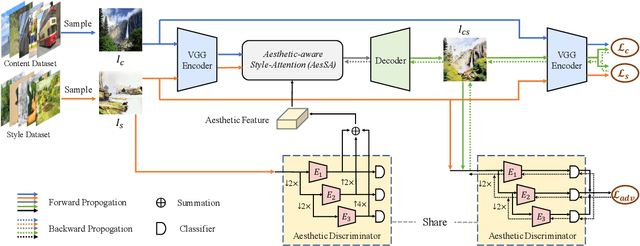
Recent studies have shown remarkable success in universal style transfer which transfers arbitrary visual styles to content images. However, existing approaches suffer from the aesthetic-unrealistic problem that introduces disharmonious patterns and evident artifacts, making the results easy to spot from real paintings. To address this limitation, we propose AesUST, a novel Aesthetic-enhanced Universal Style Transfer approach that can generate aesthetically more realistic and pleasing results for arbitrary styles. Specifically, our approach introduces an aesthetic discriminator to learn the universal human-delightful aesthetic features from a large corpus of artist-created paintings. Then, the aesthetic features are incorporated to enhance the style transfer process via a novel Aesthetic-aware Style-Attention (AesSA) module. Such an AesSA module enables our AesUST to efficiently and flexibly integrate the style patterns according to the global aesthetic channel distribution of the style image and the local semantic spatial distribution of the content image. Moreover, we also develop a new two-stage transfer training strategy with two aesthetic regularizations to train our model more effectively, further improving stylization performance. Extensive experiments and user studies demonstrate that our approach synthesizes aesthetically more harmonious and realistic results than state of the art, greatly narrowing the disparity with real artist-created paintings. Our code is available at https://github.com/EndyWon/AesUST.
E-LMC: Extended Linear Model of Coregionalization for Predictions of Spatial Fields
Mar 01, 2022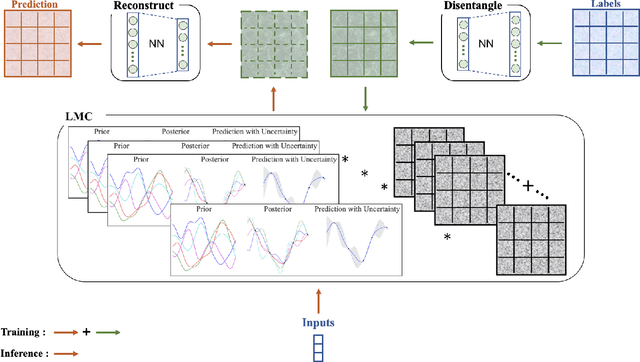
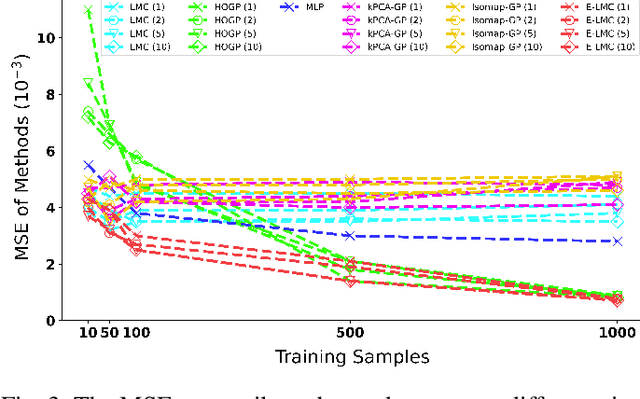
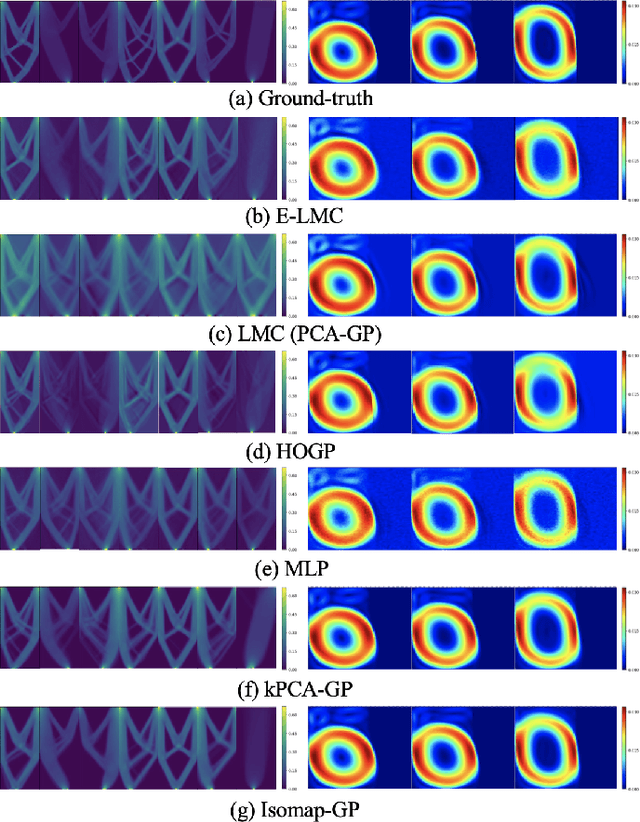
Physical simulations based on partial differential equations typically generate spatial fields results, which are utilized to calculate specific properties of a system for engineering design and optimization. Due to the intensive computational burden of the simulations, a surrogate model mapping the low-dimensional inputs to the spatial fields are commonly built based on a relatively small dataset. To resolve the challenge of predicting the whole spatial field, the popular linear model of coregionalization (LMC) can disentangle complicated correlations within the high-dimensional spatial field outputs and deliver accurate predictions. However, LMC fails if the spatial field cannot be well approximated by a linear combination of base functions with latent processes. In this paper, we extend LMC by introducing an invertible neural network to linearize the highly complex and nonlinear spatial fields such that the LMC can easily generalize to nonlinear problems while preserving the traceability and scalability. Several real-world applications demonstrate that E-LMC can exploit spatial correlations effectively, showing a maximum improvement of about 40% over the original LMC and outperforming the other state-of-the-art spatial field models.
Texture Reformer: Towards Fast and Universal Interactive Texture Transfer
Dec 06, 2021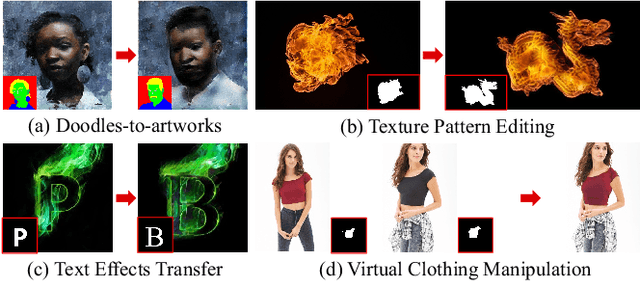
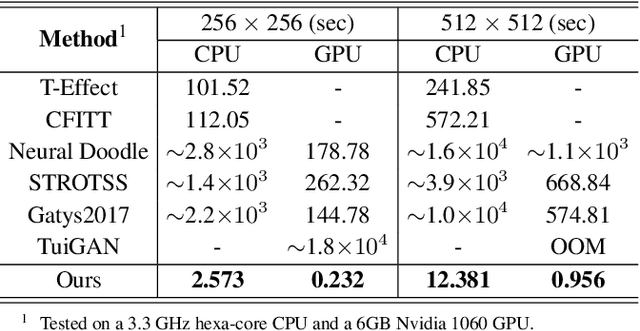
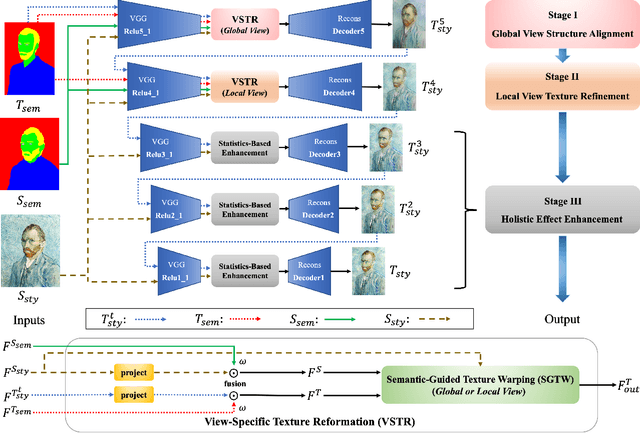
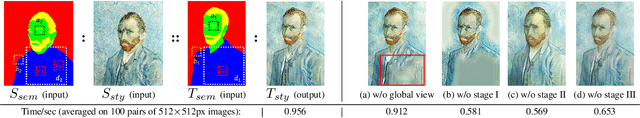
In this paper, we present the texture reformer, a fast and universal neural-based framework for interactive texture transfer with user-specified guidance. The challenges lie in three aspects: 1) the diversity of tasks, 2) the simplicity of guidance maps, and 3) the execution efficiency. To address these challenges, our key idea is to use a novel feed-forward multi-view and multi-stage synthesis procedure consisting of I) a global view structure alignment stage, II) a local view texture refinement stage, and III) a holistic effect enhancement stage to synthesize high-quality results with coherent structures and fine texture details in a coarse-to-fine fashion. In addition, we also introduce a novel learning-free view-specific texture reformation (VSTR) operation with a new semantic map guidance strategy to achieve more accurate semantic-guided and structure-preserved texture transfer. The experimental results on a variety of application scenarios demonstrate the effectiveness and superiority of our framework. And compared with the state-of-the-art interactive texture transfer algorithms, it not only achieves higher quality results but, more remarkably, also is 2-5 orders of magnitude faster. Code is available at https://github.com/EndyWon/Texture-Reformer.
Diversified Patch-based Style Transfer with Shifted Style Normalization
Jan 16, 2021
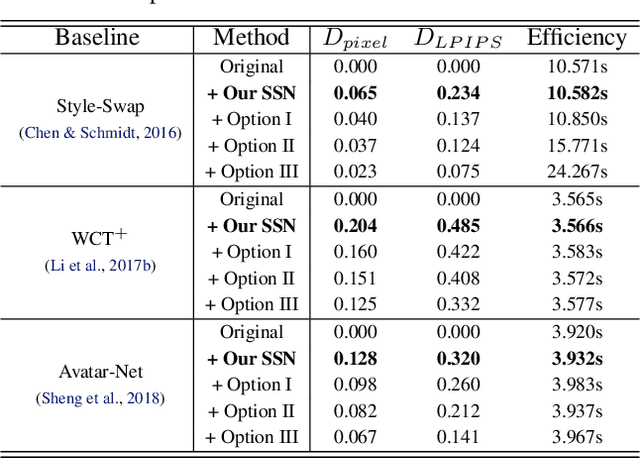
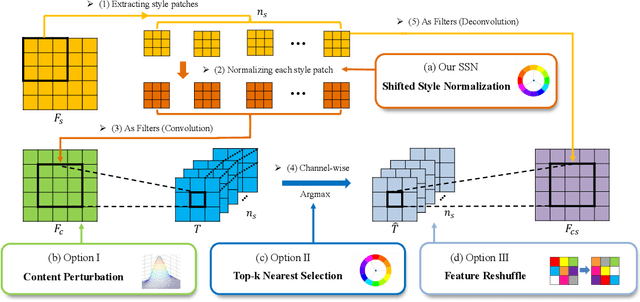
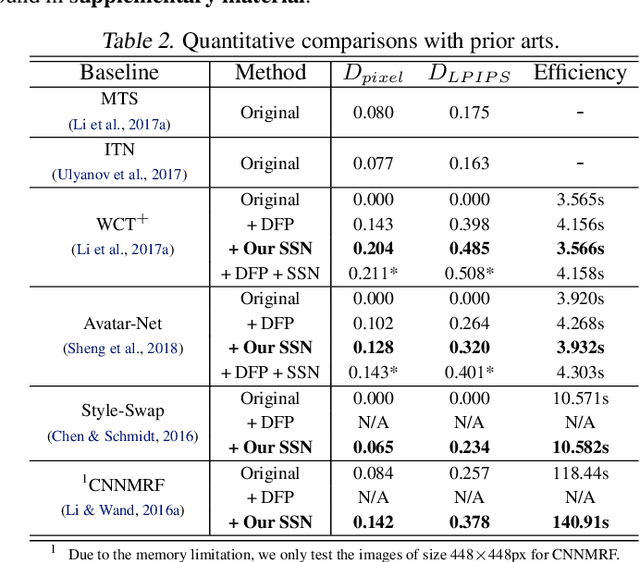
Gram-based and patch-based approaches are two important research lines of image style transfer. Recent diversified Gram-based methods have been able to produce multiple and diverse reasonable solutions for the same content and style inputs. However, as another popular research interest, the diversity of patch-based methods remains challenging due to the stereotyped style swapping process based on nearest patch matching. To resolve this dilemma, in this paper, we dive into the core style swapping process of patch-based style transfer and explore possible ways to diversify it. What stands out is an operation called shifted style normalization (SSN), the most effective and efficient way to empower existing patch-based methods to generate diverse results for arbitrary styles. The key insight is to use an important intuition that neural patches with higher activation values could contribute more to diversity. Theoretical analyses and extensive experiments are conducted to demonstrate the effectiveness of our method, and compared with other possible options and state-of-the-art algorithms, it shows remarkable superiority in both diversity and efficiency.