 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient Multi-agent Communication: An Information Bottleneck Approach
Nov 16, 2019
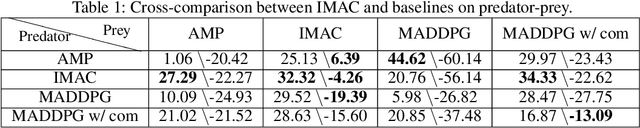
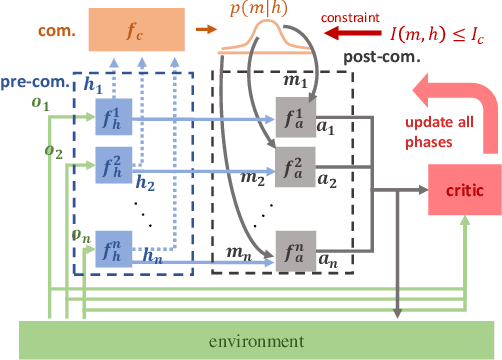
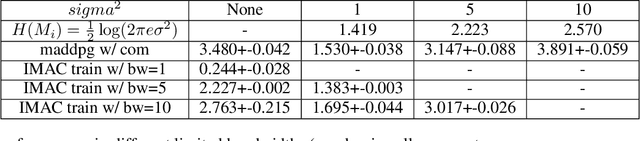
Many real-world multi-agent reinforcement learning applications require agents to communicate, assisted by a communication protocol. These applications face a common and critical issue of communication's limited bandwidth that constrains agents' ability to cooperate successfully. In this paper, rather than proposing a fixed communication protocol, we develop an Informative Multi-Agent Communication (IMAC) method to learn efficient communication protocols. Our contributions are threefold. First, we notice a fact that a limited bandwidth translates into a constraint on the communicated message entropy, thus paving the way of controlling the bandwidth. Second, we introduce a customized batch-norm layer, which controls the messages' entropy to simulate the limited bandwidth constraint. Third, we apply the information bottleneck method to discover the optimal communication protocol, which can satisfy a bandwidth constraint via training with the prior distribution in the method. To demonstrate the efficacy of our method, we conduct extensive experiments in various cooperative and competitive multi-agent tasks across two dimensions: the number of agents and different bandwidths. We show that IMAC converges fast, and leads to efficient communication among agents under the limited-bandwidth constraint as compared to many baseline methods.
Multi-label Detection and Classification of Red Blood Cells in Microscopic Images
Oct 07, 2019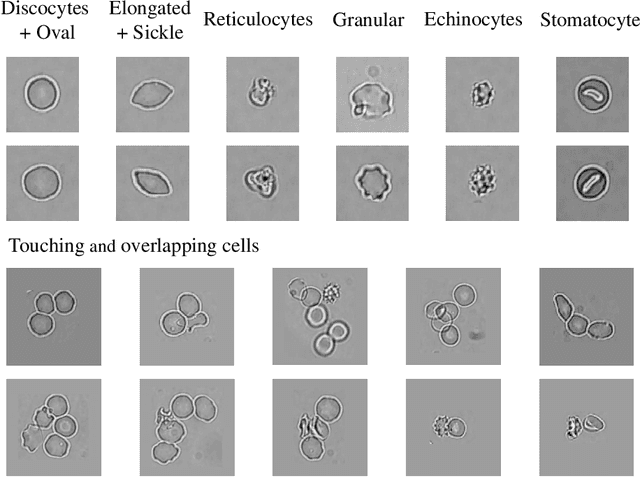
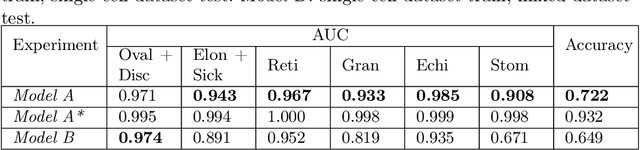
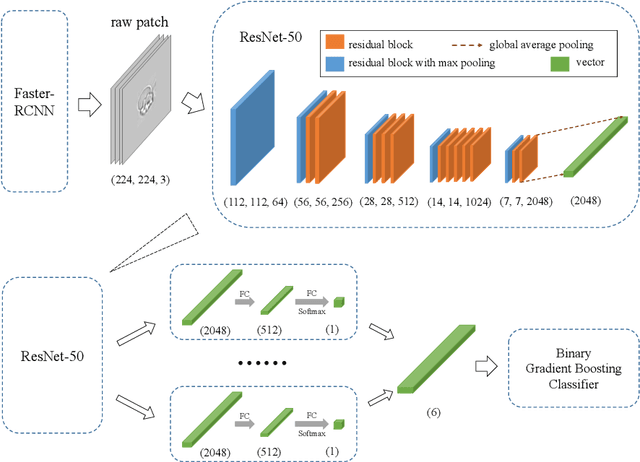

Cell detection and cell type classification from biomedical images play an important role for high-throughput imaging and various clinical application. While classification of single cell sample can be performed with standard computer vision and machine learning methods, analysis of multi-label samples (region containing congregating cells) is more challenging, as separation of individual cells can be difficult (e.g. touching cells) or even impossible (e.g. overlapping cells). As multi-instance images are common in analyzing Red Blood Cell (RBC) for Sickle Cell Disease (SCD) diagnosis, we develop and implement a multi-instance cell detection and classification framework to address this challenge. The framework firstly trains a region proposal model based on Region-based Convolutional Network (RCNN) to obtain bounding-boxes of regions potentially containing single or multiple cells from input microscopic images, which are extracted as image patches. High-level image features are then calculated from image patches through a pre-trained Convolutional Neural Network (CNN) with ResNet-50 structure. Using these image features inputs, six networks are then trained to make multi-label prediction of whether a given patch contains cells belonging to a specific cell type. As the six networks are trained with image patches consisting of both individual cells and touching/overlapping cells, they can effectively recognize cell types that are presented in multi-instance image samples. Finally, for the purpose of SCD testing, we train another machine learning classifier to predict whether the given image patch contains abnormal cell type based on outputs from the six networks. Testing result of the proposed framework shows that it can achieve good performance in automatic cell detection and classification.
Predicting Alzheimer's Disease by Hierarchical Graph Convolution from Positron Emission Tomography Imaging
Oct 01, 2019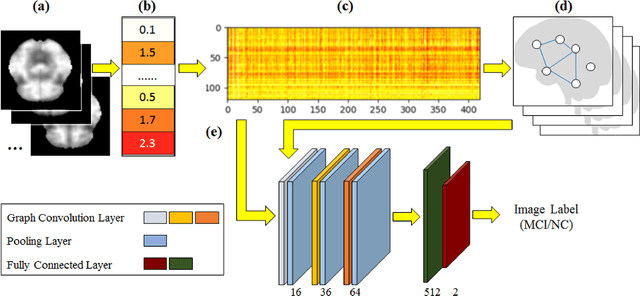
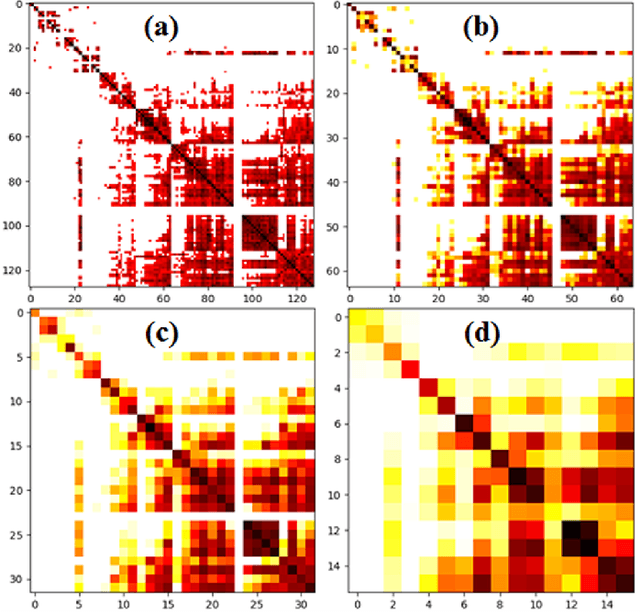
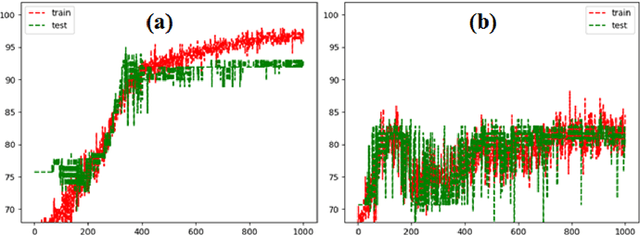
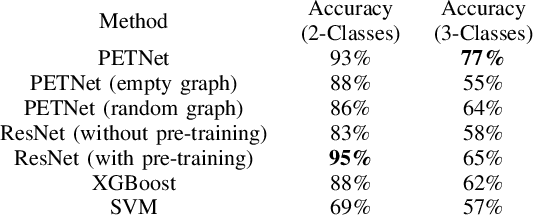
Imaging-based early diagnosis of Alzheimer Disease (AD) has become an effective approach, especially by using nuclear medicine imaging techniques such as Positron Emission Topography (PET). In various literature it has been found that PET images can be better modeled as signals (e.g. uptake of florbetapir) defined on a network (non-Euclidean) structure which is governed by its underlying graph patterns of pathological progression and metabolic connectivity. In order to effectively apply deep learning framework for PET image analysis to overcome its limitation on Euclidean grid, we develop a solution for 3D PET image representation and analysis under a generalized, graph-based CNN architecture (PETNet), which analyzes PET signals defined on a group-wise inferred graph structure. Computations in PETNet are defined in non-Euclidean, graph (network) domain, as it performs feature extraction by convolution operations on spectral-filtered signals on the graph and pooling operations based on hierarchical graph clustering. Effectiveness of the PETNet is evaluated on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, which shows improved performance over both deep learning and other machine learning-based methods.
Coherent Multi-Sentence Video Description with Variable Level of Detail
Mar 24, 2014
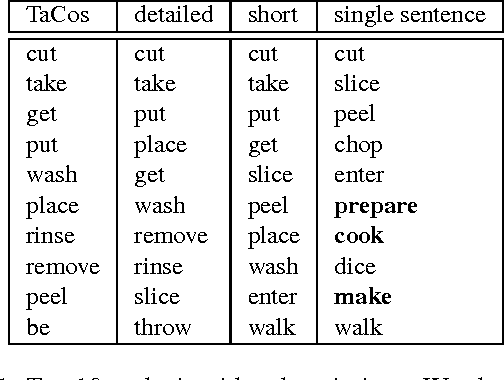
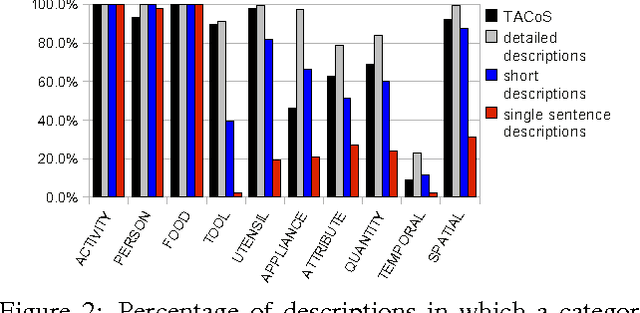
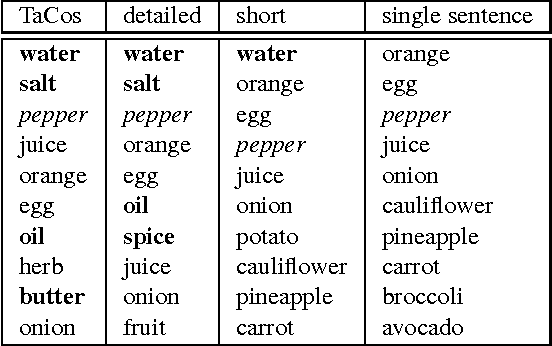
Humans can easily describe what they see in a coherent way and at varying level of detail. However, existing approaches for automatic video description are mainly focused on single sentence generation and produce descriptions at a fixed level of detail. In this paper, we address both of these limitations: for a variable level of detail we produce coherent multi-sentence descriptions of complex videos. We follow a two-step approach where we first learn to predict a semantic representation (SR) from video and then generate natural language descriptions from the SR. To produce consistent multi-sentence descriptions, we model across-sentence consistency at the level of the SR by enforcing a consistent topic. We also contribute both to the visual recognition of objects proposing a hand-centric approach as well as to the robust generation of sentences using a word lattice. Human judges rate our multi-sentence descriptions as more readable, correct, and relevant than related work. To understand the difference between more detailed and shorter descriptions, we collect and analyze a video description corpus of three levels of detail.