 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Apr 24, 2026Evaluating LLM-generated business ideas is often harder to scale than generating them. Unlike standard NLP benchmarks, business idea evaluation relies on multi-dimensional criteria such as feasibility, novelty, differentiation, user need, and market size, and expert judgments often disagree. This paper studies a methodological question raised by such disagreement: should an automatic judge approximate an aggregate consensus, or model evaluators individually? We introduce PBIG-DATA, a dataset of approximately 3,000 individual scores across 300 patent-grounded product ideas, provided by domain experts on six business-oriented dimensions: specificity, technical validity, innovativeness, competitive advantage, need validity, and market size. Analyses show substantial expert disagreement on fine-grained ordinal scores, while agreement is higher under coarse selection, suggesting structured heterogeneity rather than random noise. We then compare three judge configurations: a rubric-only zero-shot judge, an aggregate judge conditioned on mixed evaluator histories, and a personalized judge conditioned on the target evaluator's scoring history. Across dimensions and model sizes, personalized judges align more closely with the corresponding evaluator than aggregate judges, and evaluator agreement correlates with similarity of judge-generated reasoning only under personalized conditioning. These results indicate that pooled labels can be a fragile target in pluralistic evaluation settings and motivate evaluator-conditioned judge designs for business idea assessment.
STAYKATE: Hybrid In-Context Example Selection Combining Representativeness Sampling and Retrieval-based Approach -- A Case Study on Science Domains
Dec 28, 2024Large language models (LLMs) demonstrate the ability to learn in-context, offering a potential solution for scientific information extraction, which often contends with challenges such as insufficient training data and the high cost of annotation processes. Given that the selection of in-context examples can significantly impact performance, it is crucial to design a proper method to sample the efficient ones. In this paper, we propose STAYKATE, a static-dynamic hybrid selection method that combines the principles of representativeness sampling from active learning with the prevalent retrieval-based approach. The results across three domain-specific datasets indicate that STAYKATE outperforms both the traditional supervised methods and existing selection methods. The enhancement in performance is particularly pronounced for entity types that other methods pose challenges.
Unbiased Learning for the Causal Effect of Recommendation
Aug 20, 2020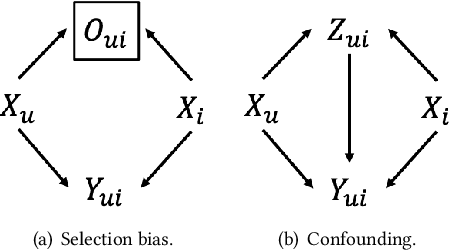
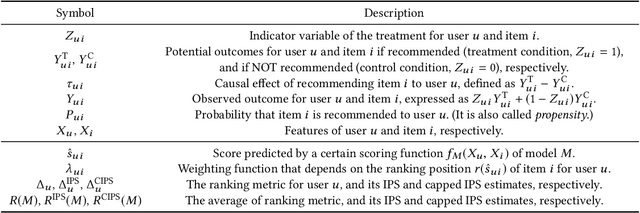
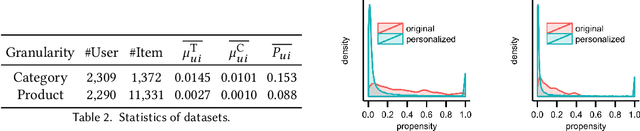
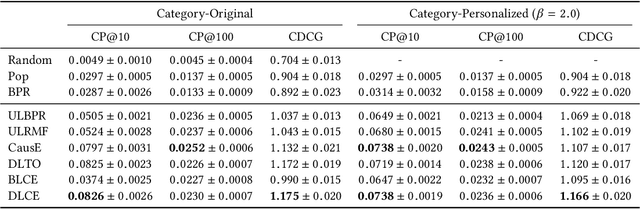
Increasing users' positive interactions, such as purchases or clicks, is an important objective of recommender systems. Recommenders typically aim to select items that users will interact with. If the recommended items are purchased, an increase in sales is expected. However, the items could have been purchased even without recommendation. Thus, we want to recommend items that results in purchases caused by recommendation. This can be formulated as a ranking problem in terms of the causal effect. Despite its importance, this problem has not been well explored in the related research. It is challenging because the ground truth of causal effect is unobservable, and estimating the causal effect is prone to the bias arising from currently deployed recommenders. This paper proposes an unbiased learning framework for the causal effect of recommendation. Based on the inverse propensity scoring technique, the proposed framework first constructs unbiased estimators for ranking metrics. Then, it conducts empirical risk minimization on the estimators with propensity capping, which reduces variance under finite training samples. Based on the framework, we develop an unbiased learning method for the causal effect extension of a ranking metric. We theoretically analyze the unbiasedness of the proposed method and empirically demonstrate that the proposed method outperforms other biased learning methods in various settings.
Submodular Bandit Problem Under Multiple Constraints
Jun 03, 2020


The linear submodular bandit problem was proposed to simultaneously address diversified retrieval and online learning in a recommender system. If there is no uncertainty, this problem is equivalent to a submodular maximization problem under a cardinality constraint. However, in some situations, recommendation lists should satisfy additional constraints such as budget constraints, other than a cardinality constraint. Thus, motivated by diversified retrieval considering budget constraints, we introduce a submodular bandit problem under the intersection of $l$ knapsacks and a $k$-system constraint. Here $k$-system constraints form a very general class of constraints including cardinality constraints and the intersection of $k$ matroid constraints. To solve this problem, we propose a non-greedy algorithm that adaptively focuses on a standard or modified upper-confidence bound. We provide a high-probability upper bound of an approximation regret, where the approximation ratio matches that of a fast offline algorithm. Moreover, we perform experiments under various combinations of constraints using a synthetic and two real-world datasets and demonstrate that our proposed methods outperform the existing baselines.