 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Apr 24, 2026Evaluating LLM-generated business ideas is often harder to scale than generating them. Unlike standard NLP benchmarks, business idea evaluation relies on multi-dimensional criteria such as feasibility, novelty, differentiation, user need, and market size, and expert judgments often disagree. This paper studies a methodological question raised by such disagreement: should an automatic judge approximate an aggregate consensus, or model evaluators individually? We introduce PBIG-DATA, a dataset of approximately 3,000 individual scores across 300 patent-grounded product ideas, provided by domain experts on six business-oriented dimensions: specificity, technical validity, innovativeness, competitive advantage, need validity, and market size. Analyses show substantial expert disagreement on fine-grained ordinal scores, while agreement is higher under coarse selection, suggesting structured heterogeneity rather than random noise. We then compare three judge configurations: a rubric-only zero-shot judge, an aggregate judge conditioned on mixed evaluator histories, and a personalized judge conditioned on the target evaluator's scoring history. Across dimensions and model sizes, personalized judges align more closely with the corresponding evaluator than aggregate judges, and evaluator agreement correlates with similarity of judge-generated reasoning only under personalized conditioning. These results indicate that pooled labels can be a fragile target in pluralistic evaluation settings and motivate evaluator-conditioned judge designs for business idea assessment.
Pretraining and Updating Language- and Domain-specific Large Language Model: A Case Study in Japanese Business Domain
Apr 12, 2024



Several previous studies have considered language- and domain-specific large language models (LLMs) as separate topics. This study explores the combination of a non-English language and a high-demand industry domain, focusing on a Japanese business-specific LLM. This type of a model requires expertise in the business domain, strong language skills, and regular updates of its knowledge. We trained a 13-billion-parameter LLM from scratch using a new dataset of business texts and patents, and continually pretrained it with the latest business documents. Further we propose a new benchmark for Japanese business domain question answering (QA) and evaluate our models on it. The results show that our pretrained model improves QA accuracy without losing general knowledge, and that continual pretraining enhances adaptation to new information. Our pretrained model and business domain benchmark are publicly available.
Training Generative Question-Answering on Synthetic Data Obtained from an Instruct-tuned Model
Oct 13, 2023



This paper presents a simple and cost-effective method for synthesizing data to train question-answering systems. For training, fine-tuning GPT models is a common practice in resource-rich languages like English, however, it becomes challenging for non-English languages due to the scarcity of sufficient question-answer (QA) pairs. Existing approaches use question and answer generators trained on human-authored QA pairs, which involves substantial human expenses. In contrast, we use an instruct-tuned model to generate QA pairs in a zero-shot or few-shot manner. We conduct experiments to compare various strategies for obtaining QA pairs from the instruct-tuned model. The results demonstrate that a model trained on our proposed synthetic data achieves comparable performance to a model trained on manually curated datasets, without incurring human costs.
Fully Neural Network based Model for General Temporal Point Processes
May 23, 2019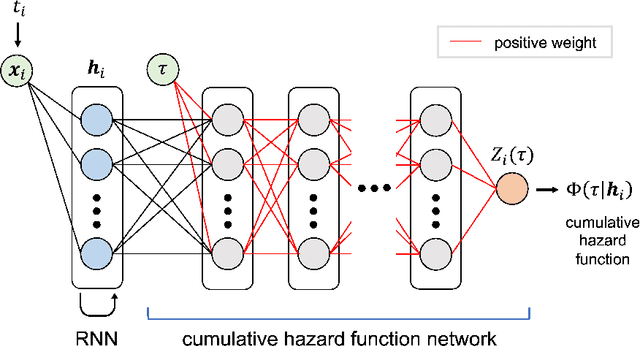
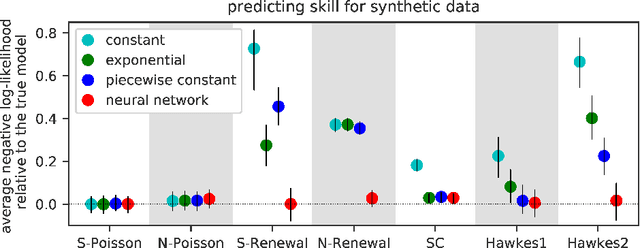
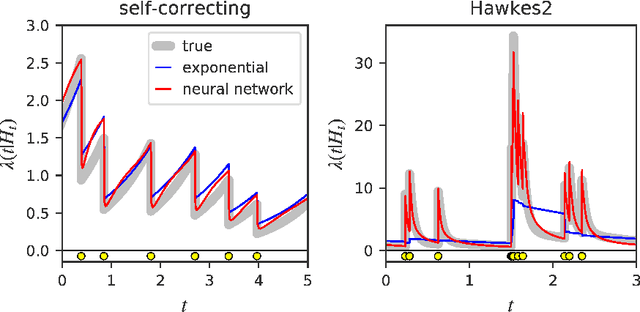
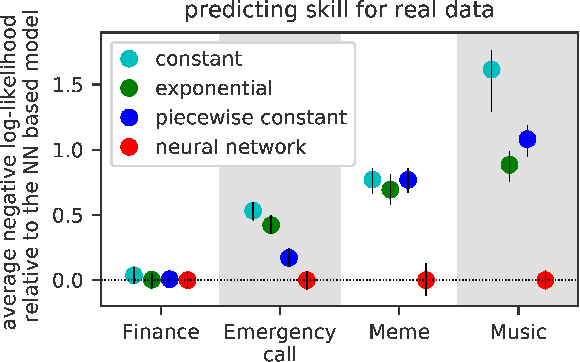
A temporal point process is a mathematical model for a time series of discrete events, which covers various applications. Recently, recurrent neural network (RNN) based models have been developed for point processes and have been found effective. RNN based models usually assume a specific functional form for the time course of the intensity function of a point process (e.g., exponentially decreasing or increasing with the time since the most recent event). However, such an assumption can restrict the expressive power of the model. We herein propose a novel RNN based model in which the time course of the intensity function is represented in a general manner. In our approach, we first model the integral of the intensity function using a feedforward neural network and then obtain the intensity function as its derivative. This approach enables us to both obtain a flexible model of the intensity function and exactly evaluate the log-likelihood function, which contains the integral of the intensity function, without any numerical approximations. Our model achieves competitive or superior performances compared to the previous state-of-the-art methods for both synthetic and real datasets.