 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOME-KGQA: A Benchmark Dataset for Multimodal Knowledge Graph Question Answering on Household Daily Activities
May 10, 2026Large Language Models (LLMs) provide flexible natural language processing capabilities, while knowledge graphs (KGs) offer explicit and structured knowledge. Integrating these two in a complementary manner enables the development of reliable and verifiable AI systems. In particular, knowledge graph question answering (KGQA) has attracted attention as a means to reduce LLM hallucinations and to leverage knowledge beyond the training data. However, existing KGQA benchmark datasets are biased toward encyclopedic knowledge, limited to a single modality, and lack fine-grained spatiotemporal data, which limits their applicability to real-world scenarios targeted by Embodied AI. We introduce HOME-KGQA, a novel KGQA benchmark dataset built on a multimodal KG of daily household activities. HOME-KGQA consists of complex, multi-hop natural language questions paired with graph database query languages. Compared to existing benchmarks, it includes more challenging questions that involve multi-level spatiotemporal reasoning, multimodal grounding, and aggregate functions. Experimental results show that the LLM-based KGQA methods fail to achieve performance comparable to that on existing datasets when evaluated on HOME-KGQA. This highlights significant challenges that should be addressed for the real-world deployment of KGQA systems. Our dataset is available at https://github.com/aistairc/home-kgqa
Why Expert Alignment Is Hard: Evidence from Subjective Evaluation
May 06, 2026Aligning large language models with expert judgment is especially difficult in subjective evaluation tasks, where experts may disagree, rely on tacit criteria, and change their judgments over time. In this paper, we study expert alignment as a way to understand this difficulty. Using expert evaluations and follow-up questionnaires, we examine how different forms of expert information affect alignment and what this reveals about subjective judgment. Our findings show four consistent patterns. First, alignment difficulty varies substantially across experts, suggesting that expert evaluation styles differ widely in their distance from a model's prior behavior. Second, explicit criteria and reasoning do not always improve alignment, indicating that expert judgment is not fully captured by verbalized rules. Third, editing is sensitive to both the number and the identity of examples, with small numbers of edits providing useful but unstable gains. Fourth, alignment difficulty differs across evaluation dimensions: dimensions grounded more directly in proposal content are easier to align, while dimensions requiring external knowledge or value-based judgment remain harder. Taken together, these results suggest that expert alignment is difficult not only because of model limitations, but also because subjective evaluation is inherently heterogeneous, partly tacit, dimension-dependent, and temporally unstable.
Aggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Apr 24, 2026Evaluating LLM-generated business ideas is often harder to scale than generating them. Unlike standard NLP benchmarks, business idea evaluation relies on multi-dimensional criteria such as feasibility, novelty, differentiation, user need, and market size, and expert judgments often disagree. This paper studies a methodological question raised by such disagreement: should an automatic judge approximate an aggregate consensus, or model evaluators individually? We introduce PBIG-DATA, a dataset of approximately 3,000 individual scores across 300 patent-grounded product ideas, provided by domain experts on six business-oriented dimensions: specificity, technical validity, innovativeness, competitive advantage, need validity, and market size. Analyses show substantial expert disagreement on fine-grained ordinal scores, while agreement is higher under coarse selection, suggesting structured heterogeneity rather than random noise. We then compare three judge configurations: a rubric-only zero-shot judge, an aggregate judge conditioned on mixed evaluator histories, and a personalized judge conditioned on the target evaluator's scoring history. Across dimensions and model sizes, personalized judges align more closely with the corresponding evaluator than aggregate judges, and evaluator agreement correlates with similarity of judge-generated reasoning only under personalized conditioning. These results indicate that pooled labels can be a fragile target in pluralistic evaluation settings and motivate evaluator-conditioned judge designs for business idea assessment.
Multimodal Task Interference: A Benchmark and Analysis of History-Target Mismatch in Multimodal LLMs
Mar 19, 2026Task interference, the performance degradation caused by task switches within a single conversation, has been studied exclusively in text-only settings despite the growing prevalence of multimodal dialogue systems. We introduce a benchmark for evaluating this phenomenon in multimodal LLMs, covering six tasks across text and vision with systematic variation of history-target along three axes: modality mismatch, reasoning mismatch, and answer format mismatch. Experiments on both open-weights and proprietary models reveal that task interference is highly directional: switching from text-only to image-based targets causes severe performance drops, while the reverse transition yields minimal degradation. Interference is further amplified when mismatches co-occur across multiple dimensions, and is driven most strongly by modality differences, followed by answer format, while reasoning requirement shifts cause minimal degradation.
Real-Time Generation of Game Video Commentary with Multimodal LLMs: Pause-Aware Decoding Approaches
Mar 03, 2026Real-time video commentary generation provides textual descriptions of ongoing events in videos. It supports accessibility and engagement in domains such as sports, esports, and livestreaming. Commentary generation involves two essential decisions: what to say and when to say it. While recent prompting-based approaches using multimodal large language models (MLLMs) have shown strong performance in content generation, they largely ignore the timing aspect. We investigate whether in-context prompting alone can support real-time commentary generation that is both semantically relevant and well-timed. We propose two prompting-based decoding strategies: 1) a fixed-interval approach, and 2) a novel dynamic interval-based decoding approach that adjusts the next prediction timing based on the estimated duration of the previous utterance. Both methods enable pause-aware generation without any fine-tuning. Experiments on Japanese and English datasets of racing and fighting games show that the dynamic interval-based decoding can generate commentary more closely aligned with human utterance timing and content using prompting alone. We release a multilingual benchmark dataset, trained models, and implementations to support future research on real-time video commentary generation.
QCoder Benchmark: Bridging Language Generation and Quantum Hardware through Simulator-Based Feedback
Oct 30, 2025Large language models (LLMs) have increasingly been applied to automatic programming code generation. This task can be viewed as a language generation task that bridges natural language, human knowledge, and programming logic. However, it remains underexplored in domains that require interaction with hardware devices, such as quantum programming, where human coders write Python code that is executed on a quantum computer. To address this gap, we introduce QCoder Benchmark, an evaluation framework that assesses LLMs on quantum programming with feedback from simulated hardware devices. Our benchmark offers two key features. First, it supports evaluation using a quantum simulator environment beyond conventional Python execution, allowing feedback of domain-specific metrics such as circuit depth, execution time, and error classification, which can be used to guide better generation. Second, it incorporates human-written code submissions collected from real programming contests, enabling both quantitative comparisons and qualitative analyses of LLM outputs against human-written codes. Our experiments reveal that even advanced models like GPT-4o achieve only around 18.97% accuracy, highlighting the difficulty of the benchmark. In contrast, reasoning-based models such as o3 reach up to 78% accuracy, outperforming averaged success rates of human-written codes (39.98%). We release the QCoder Benchmark dataset and public evaluation API to support further research.
Pretraining and Updating Language- and Domain-specific Large Language Model: A Case Study in Japanese Business Domain
Apr 12, 2024



Several previous studies have considered language- and domain-specific large language models (LLMs) as separate topics. This study explores the combination of a non-English language and a high-demand industry domain, focusing on a Japanese business-specific LLM. This type of a model requires expertise in the business domain, strong language skills, and regular updates of its knowledge. We trained a 13-billion-parameter LLM from scratch using a new dataset of business texts and patents, and continually pretrained it with the latest business documents. Further we propose a new benchmark for Japanese business domain question answering (QA) and evaluate our models on it. The results show that our pretrained model improves QA accuracy without losing general knowledge, and that continual pretraining enhances adaptation to new information. Our pretrained model and business domain benchmark are publicly available.
Prompting for Numerical Sequences: A Case Study on Market Comment Generation
Apr 03, 2024



Large language models (LLMs) have been applied to a wide range of data-to-text generation tasks, including tables, graphs, and time-series numerical data-to-text settings. While research on generating prompts for structured data such as tables and graphs is gaining momentum, in-depth investigations into prompting for time-series numerical data are lacking. Therefore, this study explores various input representations, including sequences of tokens and structured formats such as HTML, LaTeX, and Python-style codes. In our experiments, we focus on the task of Market Comment Generation, which involves taking a numerical sequence of stock prices as input and generating a corresponding market comment. Contrary to our expectations, the results show that prompts resembling programming languages yield better outcomes, whereas those similar to natural languages and longer formats, such as HTML and LaTeX, are less effective. Our findings offer insights into creating effective prompts for tasks that generate text from numerical sequences.
Training Generative Question-Answering on Synthetic Data Obtained from an Instruct-tuned Model
Oct 13, 2023



This paper presents a simple and cost-effective method for synthesizing data to train question-answering systems. For training, fine-tuning GPT models is a common practice in resource-rich languages like English, however, it becomes challenging for non-English languages due to the scarcity of sufficient question-answer (QA) pairs. Existing approaches use question and answer generators trained on human-authored QA pairs, which involves substantial human expenses. In contrast, we use an instruct-tuned model to generate QA pairs in a zero-shot or few-shot manner. We conduct experiments to compare various strategies for obtaining QA pairs from the instruct-tuned model. The results demonstrate that a model trained on our proposed synthetic data achieves comparable performance to a model trained on manually curated datasets, without incurring human costs.
Learning to Select, Track, and Generate for Data-to-Text
Jul 23, 2019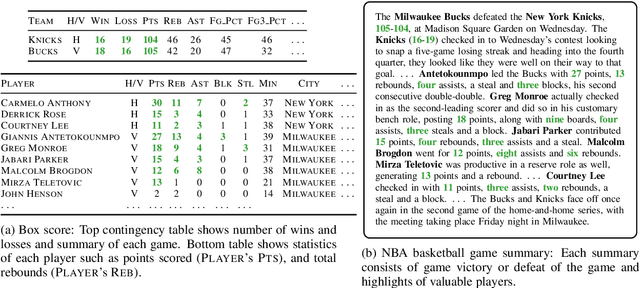

We propose a data-to-text generation model with two modules, one for tracking and the other for text generation. Our tracking module selects and keeps track of salient information and memorizes which record has been mentioned. Our generation module generates a summary conditioned on the state of tracking module. Our model is considered to simulate the human-like writing process that gradually selects the information by determining the intermediate variables while writing the summary. In addition, we also explore the effectiveness of the writer information for generation. Experimental results show that our model outperforms existing models in all evaluation metrics even without writer information. Incorporating writer information further improves the performance, contributing to content planning and surface realization.