 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Multi-scale Consistent Network for Multi-class Fundus Lesion Segmentation
May 31, 2022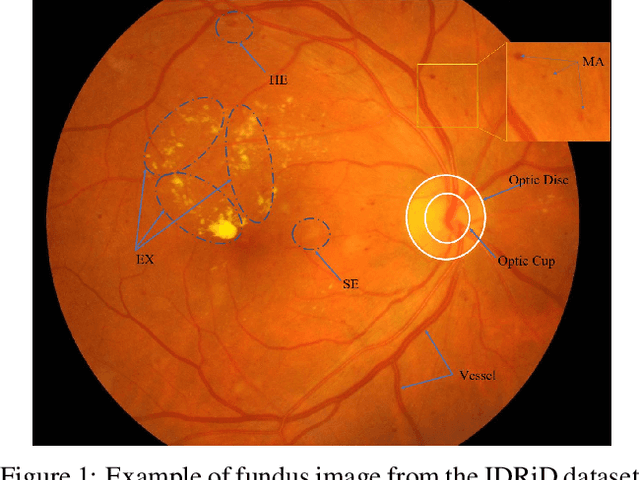
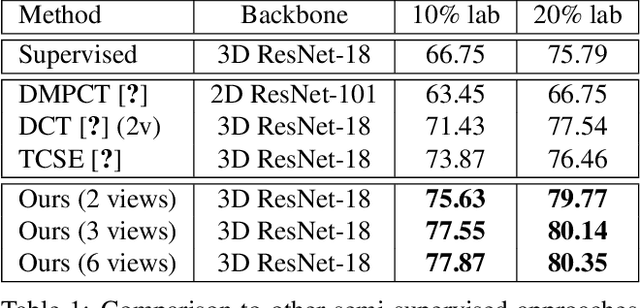
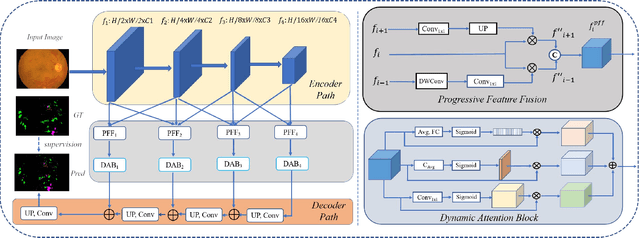
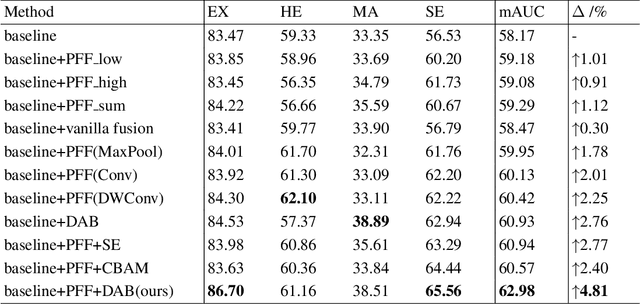
Effectively integrating multi-scale information is of considerable significance for the challenging multi-class segmentation of fundus lesions because different lesions vary significantly in scales and shapes. Several methods have been proposed to successfully handle the multi-scale object segmentation. However, two issues are not considered in previous studies. The first is the lack of interaction between adjacent feature levels, and this will lead to the deviation of high-level features from low-level features and the loss of detailed cues. The second is the conflict between the low-level and high-level features, this occurs because they learn different scales of features, thereby confusing the model and decreasing the accuracy of the final prediction. In this paper, we propose a progressive multi-scale consistent network (PMCNet) that integrates the proposed progressive feature fusion (PFF) block and dynamic attention block (DAB) to address the aforementioned issues. Specifically, PFF block progressively integrates multi-scale features from adjacent encoding layers, facilitating feature learning of each layer by aggregating fine-grained details and high-level semantics. As features at different scales should be consistent, DAB is designed to dynamically learn the attentive cues from the fused features at different scales, thus aiming to smooth the essential conflicts existing in multi-scale features. The two proposed PFF and DAB blocks can be integrated with the off-the-shelf backbone networks to address the two issues of multi-scale and feature inconsistency in the multi-class segmentation of fundus lesions, which will produce better feature representation in the feature space. Experimental results on three public datasets indicate that the proposed method is more effective than recent state-of-the-art methods.
Applications of Deep Learning in Fundus Images: A Review
Jan 25, 2021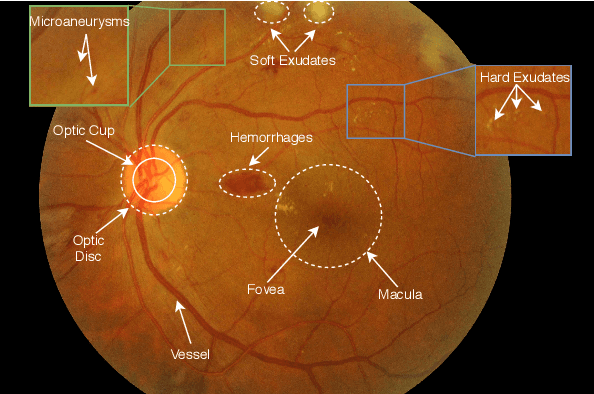
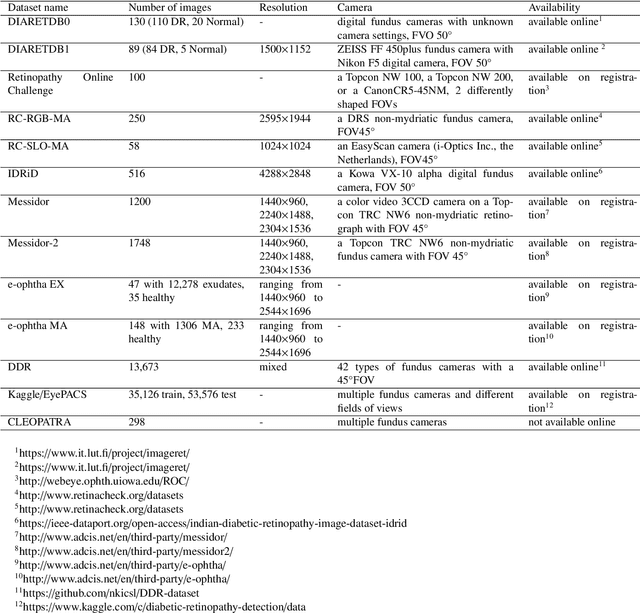
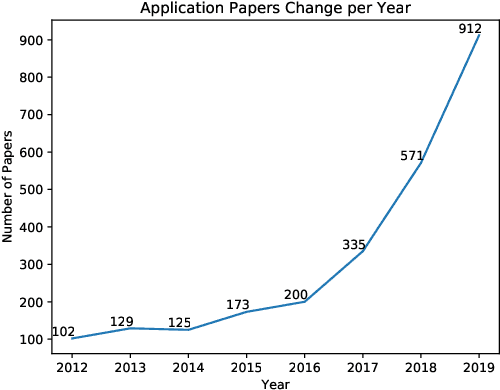
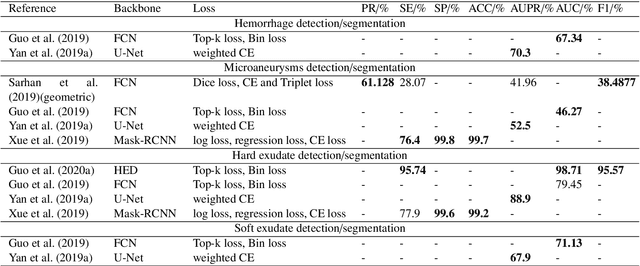
The use of fundus images for the early screening of eye diseases is of great clinical importance. Due to its powerful performance, deep learning is becoming more and more popular in related applications, such as lesion segmentation, biomarkers segmentation, disease diagnosis and image synthesis. Therefore, it is very necessary to summarize the recent developments in deep learning for fundus images with a review paper. In this review, we introduce 143 application papers with a carefully designed hierarchy. Moreover, 33 publicly available datasets are presented. Summaries and analyses are provided for each task. Finally, limitations common to all tasks are revealed and possible solutions are given. We will also release and regularly update the state-of-the-art results and newly-released datasets at https://github.com/nkicsl/Fundus Review to adapt to the rapid development of this field.
Line Art Correlation Matching Network for Automatic Animation Colorization
Apr 14, 2020
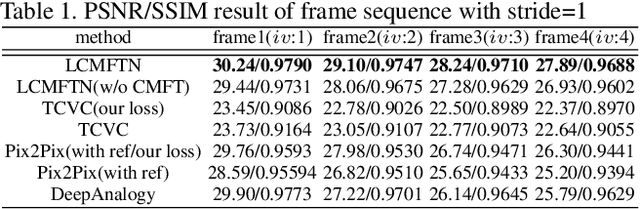
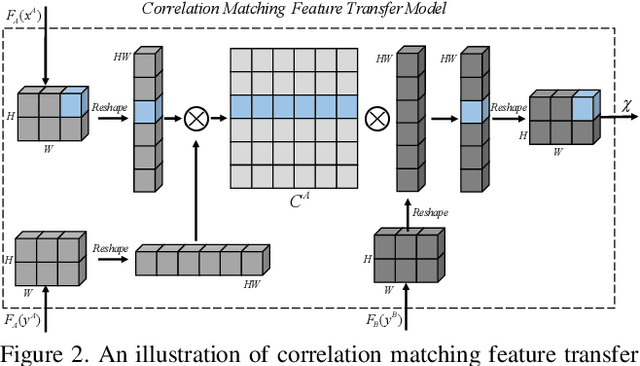
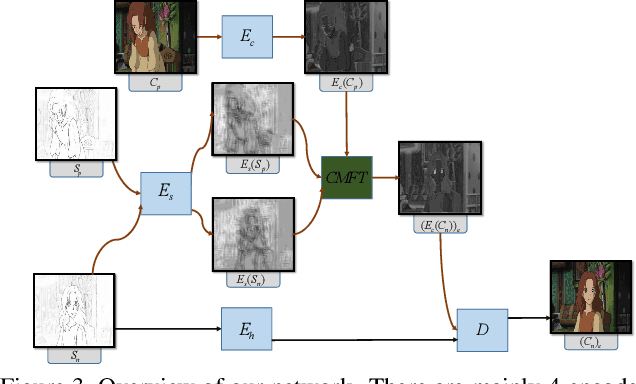
Automatic animation line art colorization is a challenging computer vision problem since line art is a highly sparse and abstracted information and there exists a strict requirement for the color and style consistency between frames. Recently, a lot of GAN(Generative Adversarial Network) based image-to-image transfer method for single line art colorization has emerged. They can generate perceptually appealing result conditioned on line art. However,these methods can not be adopted to the task of animation colorization because of the lack of consideration of in-between frame consistency. Existing methods simply input the previous colored frame as a reference to color the next line art, which will mislead the colorization due to the spatial misalignment of the previous colored frame and the next line art especially at positions where apparent changes happen. To address these challenges, we design a kind of matching model called CM(co-rrelation matching) to align the colored reference in an learnable way and integrate the model into an U-Net structure generator in a coarse-to-fine manner. Extension evaluations shows that CM model can effectively improve the in-between consistency and generating quality expecially when the motion is intense and diverse.