 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Continual Learning for Dynamic Digital Twins over Wireless Networks
Apr 10, 2022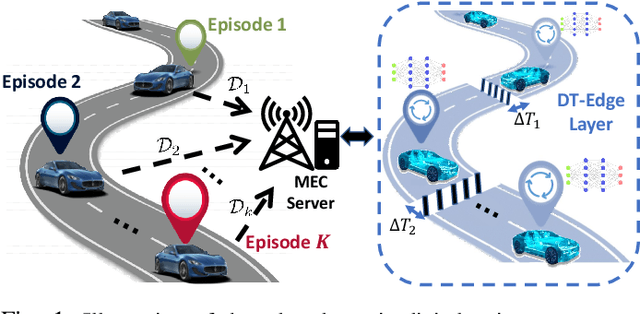
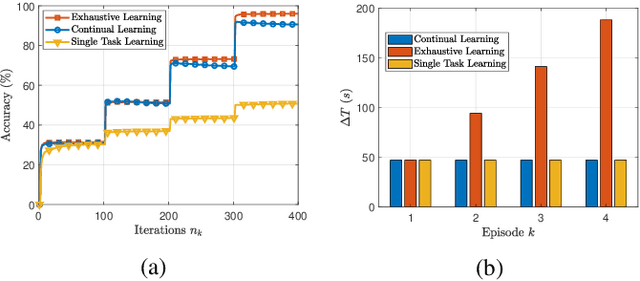
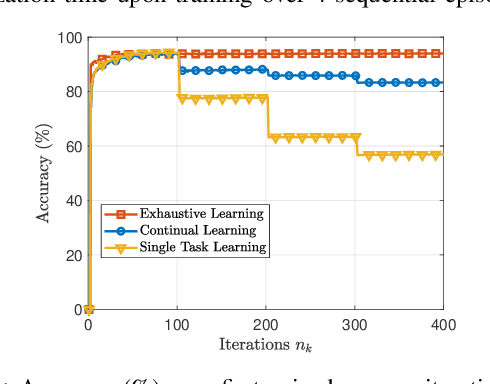
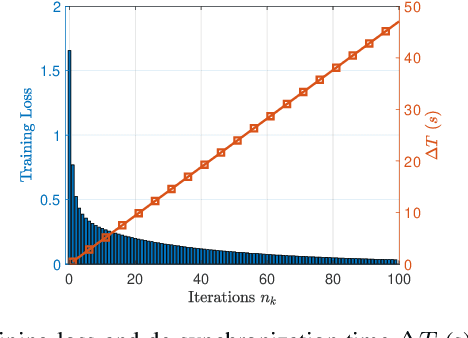
Digital twins (DTs) constitute a critical link between the real-world and the metaverse. To guarantee a robust connection between these two worlds, DTs should maintain accurate representations of the physical applications, while preserving synchronization between real and digital entities. In this paper, a novel edge continual learning framework is proposed to accurately model the evolving affinity between a physical twin (PT) and its corresponding cyber twin (CT) while maintaining their utmost synchronization. In particular, a CT is simulated as a deep neural network (DNN) at the wireless network edge to model an autonomous vehicle traversing an episodically dynamic environment. As the vehicular PT updates its driving policy in each episode, the CT is required to concurrently adapt its DNN model to the PT, which gives rise to a de-synchronization gap. Considering the history-aware nature of DTs, the model update process is posed a dual objective optimization problem whose goal is to jointly minimize the loss function over all encountered episodes and the corresponding de-synchronization time. As the de-synchronization time continues to increase over sequential episodes, an elastic weight consolidation (EWC) technique that regularizes the DT history is proposed to limit de-synchronization time. Furthermore, to address the plasticity-stability tradeoff accompanying the progressive growth of the EWC regularization terms, a modified EWC method that considers fair execution between the historical episodes of the DTs is adopted. Ultimately, the proposed framework achieves a simultaneously accurate and synchronous CT model that is robust to catastrophic forgetting. Simulation results show that the proposed solution can achieve an accuracy of 90 % while guaranteeing a minimal desynchronization time.
3TO: THz-Enabled Throughput and Trajectory Optimization of UAVs in 6G Networks by Proximal Policy Optimization Deep Reinforcement Learning
Feb 07, 2022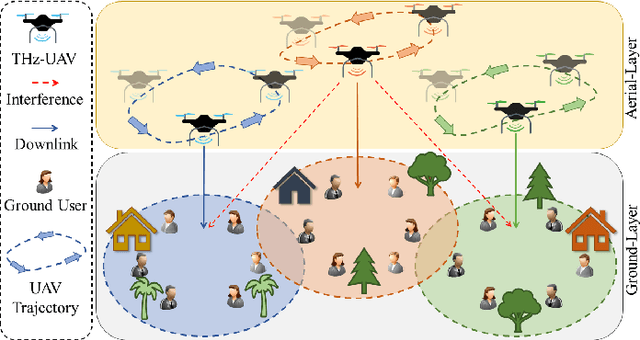
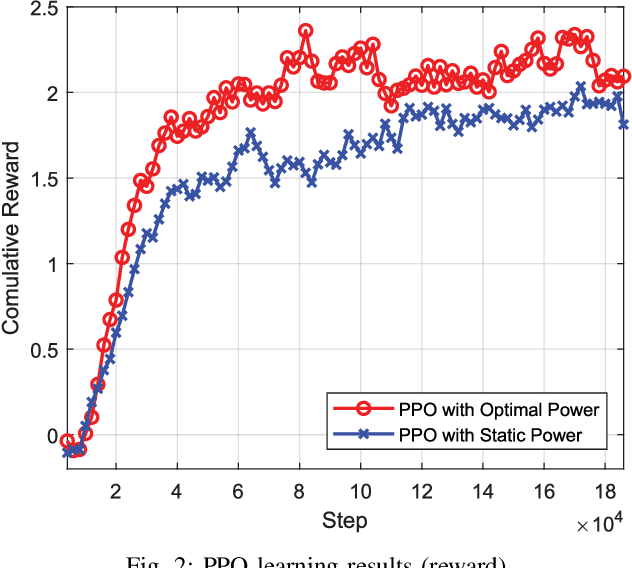
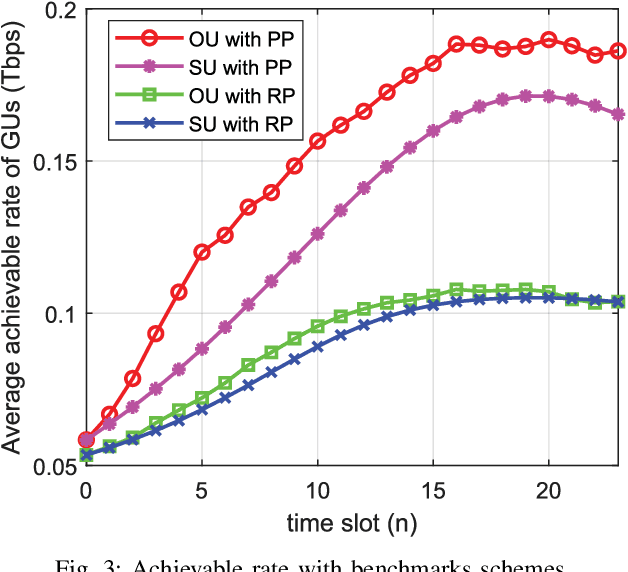
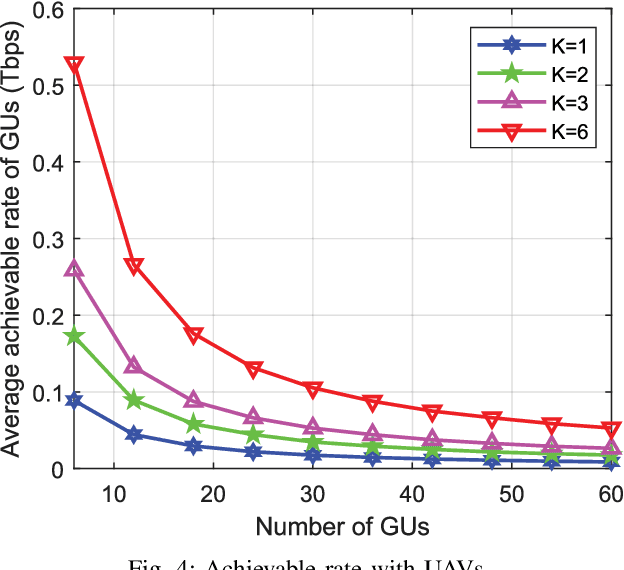
Next-generation networks need to meet ubiquitous and high data-rate demand. Therefore, this paper considers the throughput and trajectory optimization of terahertz (THz)-enabled unmanned aerial vehicles (UAVs) in the sixth-generation (6G) communication networks. In the considered scenario, multiple UAVs must provide on-demand terabits per second (TB/s) services to an urban area along with existing terrestrial networks. However, THz-empowered UAVs pose some new constraints, e.g., dynamic THz-channel conditions for ground users (GUs) association and UAV trajectory optimization to fulfill GU's throughput demands. Thus, a framework is proposed to address these challenges, where a joint UAVs-GUs association, transmit power, and the trajectory optimization problem is studied. The formulated problem is mixed-integer non-linear programming (MINLP), which is NP-hard to solve. Consequently, an iterative algorithm is proposed to solve three sub-problems iteratively, i.e., UAVs-GUs association, transmit power, and trajectory optimization. Simulation results demonstrate that the proposed algorithm increased the throughput by up to 10%, 68.9%, and 69.1% respectively compared to baseline algorithms.
Blue Data Computation Maximization in 6G Space-Air-Sea Non-Terrestrial Networks
Feb 05, 2022Non-terrestrial networks (NTN), encompassing space and air platforms, are a key component of the upcoming sixth-generation (6G) cellular network. Meanwhile, maritime network traffic has grown significantly in recent years due to sea transportation used for national defense, research, recreational activities, domestic and international trade. In this paper, the seamless and reliable demand for communication and computation in maritime wireless networks is investigated. Two types of marine user equipment (UEs), i.e., low-antenna gain and high-antenna gain UEs, are considered. A joint task computation and time allocation problem for weighted sum-rate maximization is formulated as mixed-integer linear programming (MILP). The goal is to design an algorithm that enables the network to efficiently provide backhaul resources to an unmanned aerial vehicle (UAV) and offload HUEs tasks to LEO satellite for blue data (i.e., marine user's data). To solve this MILP, a solution based on the Bender and primal decomposition is proposed. The Bender decomposes MILP into the master problem for binary task decision and subproblem for continuous-time resource allocation. Moreover, primal decomposition deals with a coupling constraint in the subproblem. Finally, numerical results demonstrate that the proposed algorithm provides the maritime UEs coverage demand in polynomial time computational complexity and achieves a near-optimal solution.
Reliable Beam Tracking with Dynamic Beamwidth Adaptation in Terahertz (THz) Communications
Jan 17, 2022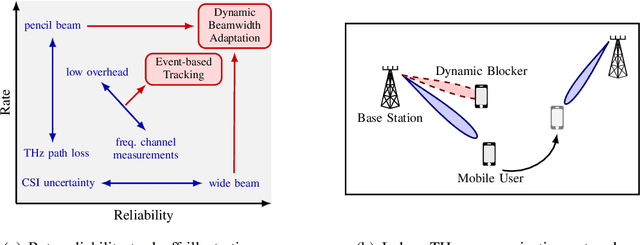
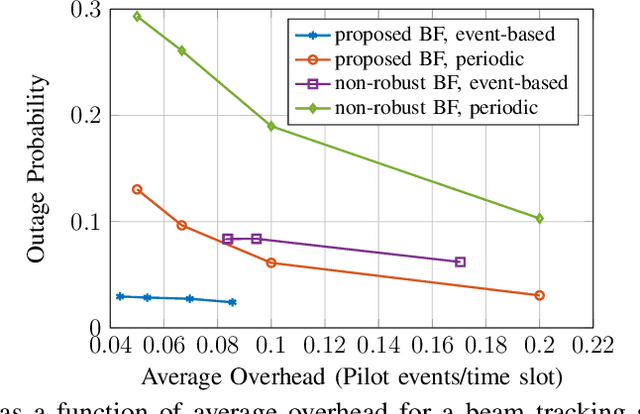
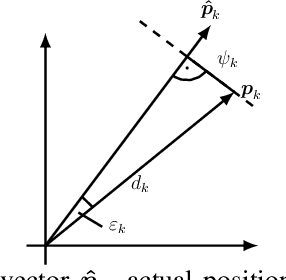
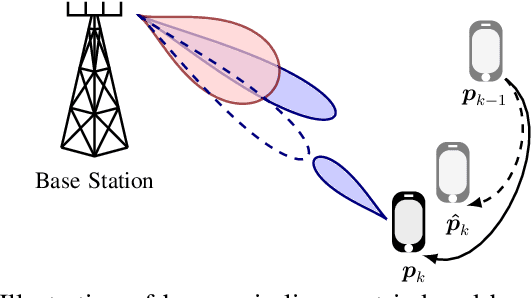
THz communication is regarded as one of the potential key enablers for next-generation wireless systems. While THz frequency bands provide abundant bandwidths and extremely high data rates, the operation at THz bands is mandated by short communication ranges and narrow pencil beams, which are highly susceptible to user mobility and beam misalignment as well as channel blockages. This raises the need for novel beam tracking methods that take into account the tradeoff between enhancing the received signal strength by increasing beam directivity, and increasing the coverage probability by widening the beam. To address these challenges, a multi-objective optimization problem is formulated with the goal of jointly maximizing the ergodic rate and minimizing the outage probability subject to transmit power and average overhead constraints. Then, a novel parameterized beamformer with dynamic beamwidth adaptation is proposed. In addition to the precoder, an event-based beam tracking approach is introduced that enables reacting to outages caused by beam misalignment and dynamic blockage while maintaining a low pilot overhead. Simulation results show that our proposed beamforming scheme improves average rate performance and reduces the amount of communication outages caused by beam misalignment. Moreover, the proposed event-triggered channel estimation approach enables low-overhead yet reliable communication.
Wireless-Enabled Asynchronous Federated Fourier Neural Network for Turbulence Prediction in Urban Air Mobility (UAM)
Dec 26, 2021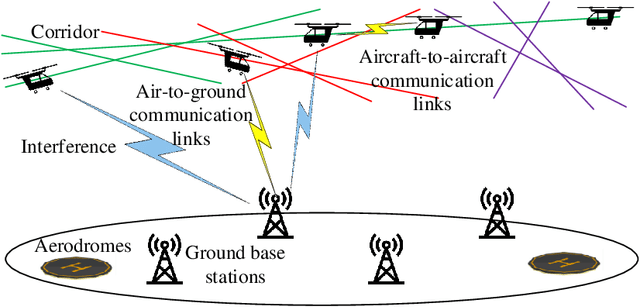
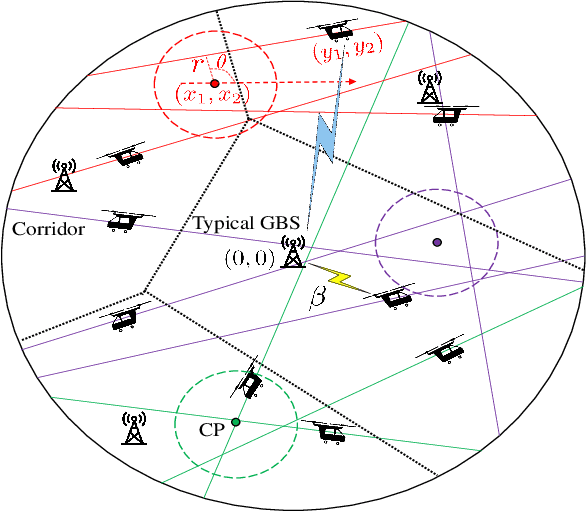
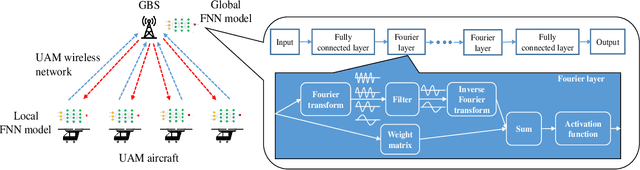

To meet the growing mobility needs in intra-city transportation, the concept of urban air mobility (UAM) has been proposed in which vertical takeoff and landing (VTOL) aircraft are used to provide a ride-hailing service. In UAM, aircraft can operate in designated air spaces known as corridors, that link the aerodromes. A reliable communication network between GBSs and aircraft enables UAM to adequately utilize the airspace and create a fast, efficient, and safe transportation system. In this paper, to characterize the wireless connectivity performance for UAM, a spatial model is proposed. For this setup, the distribution of the distance between an arbitrarily selected GBS and its associated aircraft and the Laplace transform of the interference experienced by the GBS are derived. Using these results, the signal-to-interference ratio (SIR)-based connectivity probability is determined to capture the connectivity performance of the UAM aircraft-to-ground communication network. Then, leveraging these connectivity results, a wireless-enabled asynchronous federated learning (AFL) framework that uses a Fourier neural network is proposed to tackle the challenging problem of turbulence prediction during UAM operations. For this AFL scheme, a staleness-aware global aggregation scheme is introduced to expedite the convergence to the optimal turbulence prediction model used by UAM aircraft. Simulation results validate the theoretical derivations for the UAM wireless connectivity. The results also demonstrate that the proposed AFL framework converges to the optimal turbulence prediction model faster than the synchronous federated learning baselines and a staleness-free AFL approach. Furthermore, the results characterize the performance of wireless connectivity and convergence of the aircraft's turbulence model under different parameter settings, offering useful UAM design guidelines.
Jamming Pattern Recognition over Multi-Channel Networks: A Deep Learning Approach
Dec 19, 2021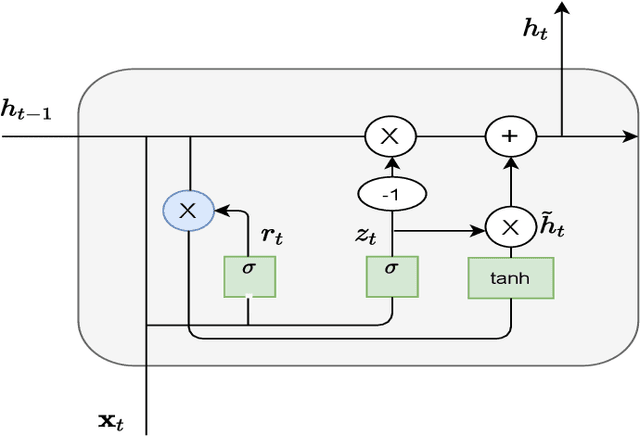
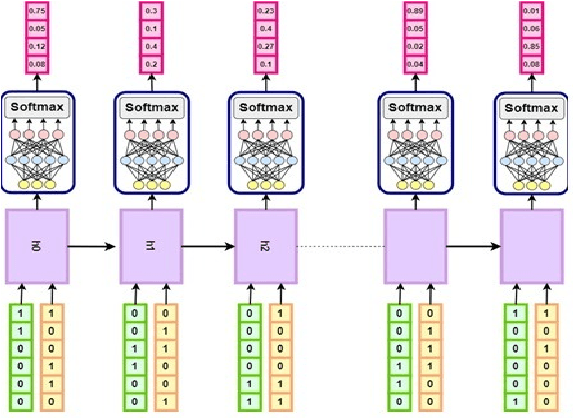
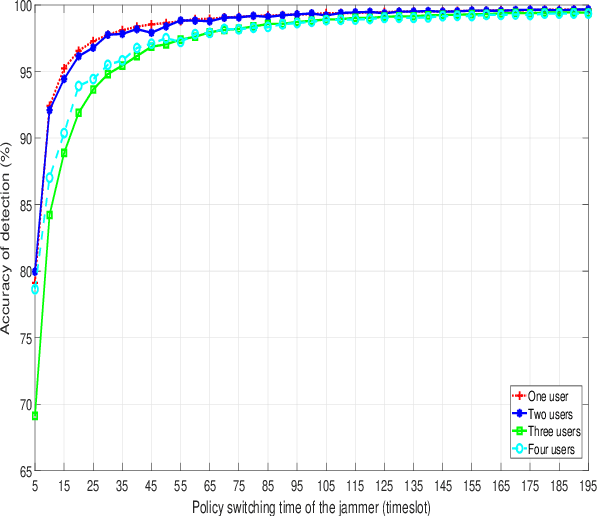
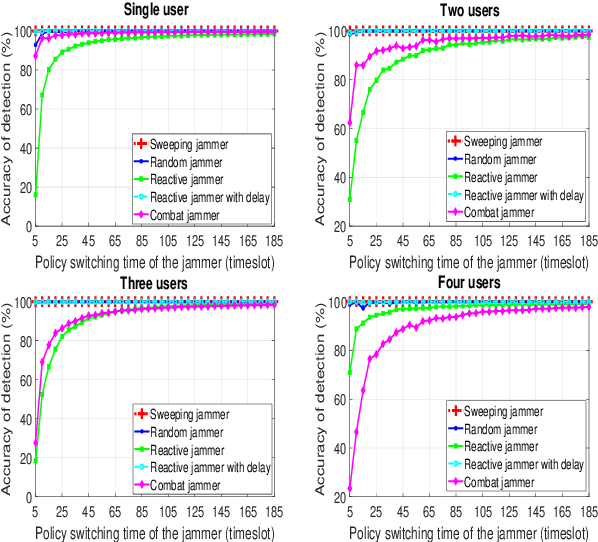
With the advent of intelligent jammers, jamming attacks have become a more severe threat to the performance of wireless systems. An intelligent jammer is able to change its policy to minimize the probability of being traced by legitimate nodes. Thus, an anti-jamming mechanism capable of constantly adjusting to the jamming policy is required to combat such a jammer. Remarkably, existing anti-jamming methods are not applicable here because they mainly focus on mitigating jamming attacks with an invariant jamming policy, and they rarely consider an intelligent jammer as an adversary. Therefore, in this paper, to employ a jamming type recognition technique working alongside an anti-jamming technique is proposed. The proposed recognition method employs a recurrent neural network that takes the jammer's occupied channels as inputs and outputs the jammer type. Under this scheme, the real-time jammer policy is first identified, and, then, the most appropriate countermeasure is chosen. Consequently, any changes to the jammer policy can be instantly detected with the proposed recognition technique allowing for a rapid switch to a new anti-jamming method fitted to the new jamming policy. To evaluate the performance of the proposed recognition method, the accuracy of the detection is derived as a function of the jammer policy switching time. Simulation results show the detection accuracy for all the considered users numbers is greater than 70% when the jammer switches its policy every 5 time slots and the accuracy raises to 90% when the jammer policy switching time is 45.
Joint Sensing and Communication for Situational Awareness in Wireless THz Systems
Nov 28, 2021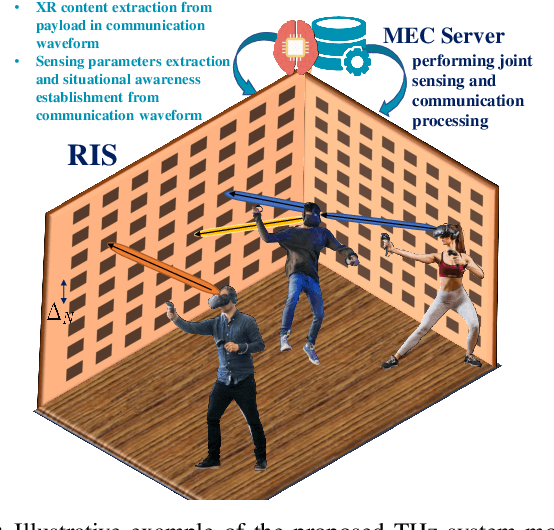
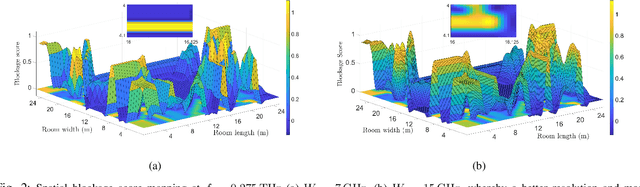
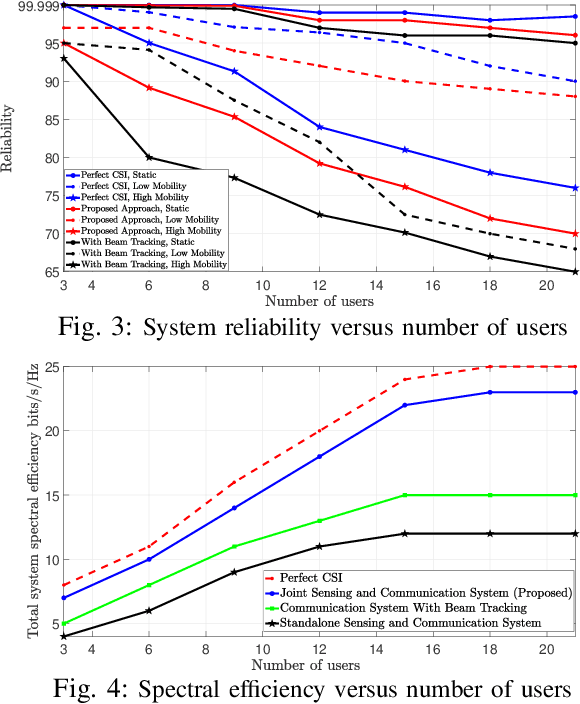
Next-generation wireless systems are rapidly evolving from communication-only systems to multi-modal systems with integrated sensing and communications. In this paper a novel joint sensing and communication framework is proposed for enabling wireless extended reality (XR) at terahertz (THz) bands. To gather rich sensing information and a higher line-of-sight (LoS) availability, THz-operated reconfigurable intelligent surfaces (RISs) acting as base stations are deployed. The sensing parameters are extracted by leveraging THz's quasi-opticality and opportunistically utilizing uplink communication waveforms. This enables the use of the same waveform, spectrum, and hardware for both sensing and communication purposes. The environmental sensing parameters are then derived by exploiting the sparsity of THz channels via tensor decomposition. Hence, a high-resolution indoor mapping is derived so as to characterize the spatial availability of communications and the mobility of users. Simulation results show that in the proposed framework, the resolution and data rate of the overall system are positively correlated, thus allowing a joint optimization between these metrics with no tradeoffs. Results also show that the proposed framework improves the system reliability in static and mobile systems. In particular, the highest reliability gains of 10% in reliability are achieved in a walking speed mobile environment compared to communication only systems with beam tracking.
Semantic-Aware Collaborative Deep Reinforcement Learning Over Wireless Cellular Networks
Nov 23, 2021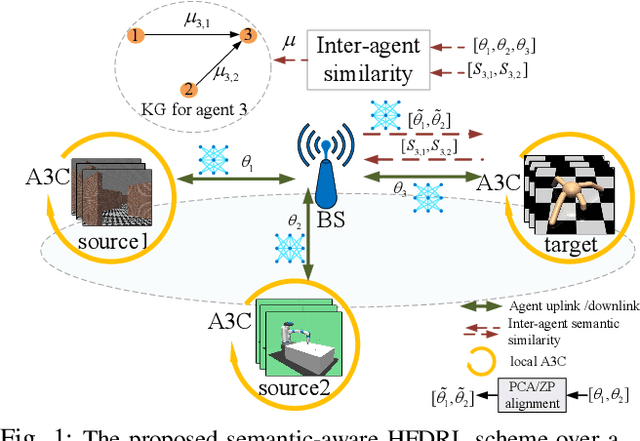
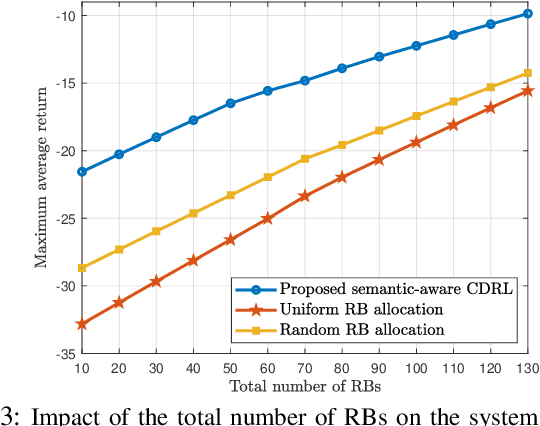
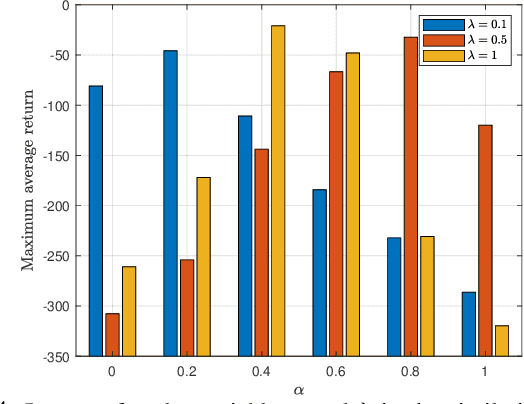
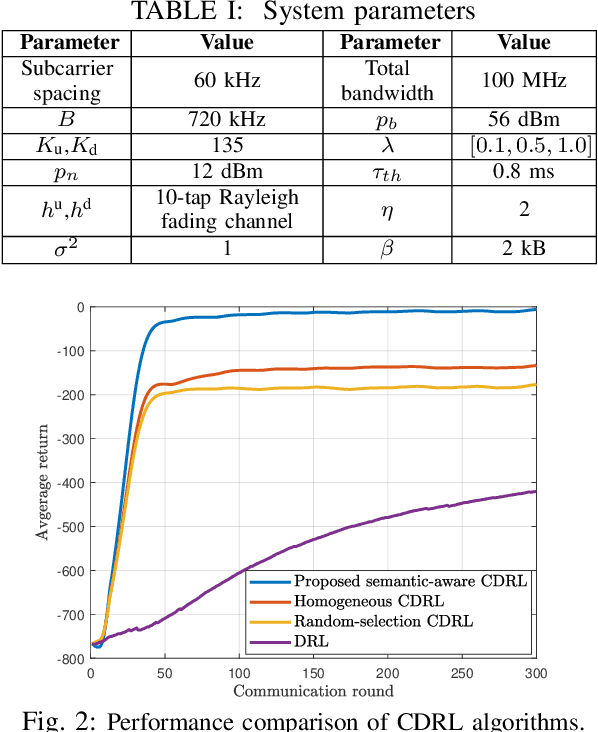
Collaborative deep reinforcement learning (CDRL) algorithms in which multiple agents can coordinate over a wireless network is a promising approach to enable future intelligent and autonomous systems that rely on real-time decision-making in complex dynamic environments. Nonetheless, in practical scenarios, CDRL faces many challenges due to the heterogeneity of agents and their learning tasks, different environments, time constraints of the learning, and resource limitations of wireless networks. To address these challenges, in this paper, a novel semantic-aware CDRL method is proposed to enable a group of heterogeneous untrained agents with semantically-linked DRL tasks to collaborate efficiently across a resource-constrained wireless cellular network. To this end, a new heterogeneous federated DRL (HFDRL) algorithm is proposed to select the best subset of semantically relevant DRL agents for collaboration. The proposed approach then jointly optimizes the training loss and wireless bandwidth allocation for the cooperating selected agents in order to train each agent within the time limit of its real-time task. Simulation results show the superior performance of the proposed algorithm compared to state-of-the-art baselines.
On the Tradeoff between Energy, Precision, and Accuracy in Federated Quantized Neural Networks
Nov 17, 2021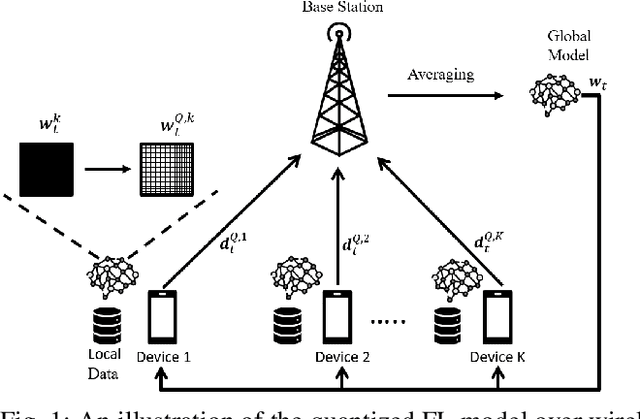
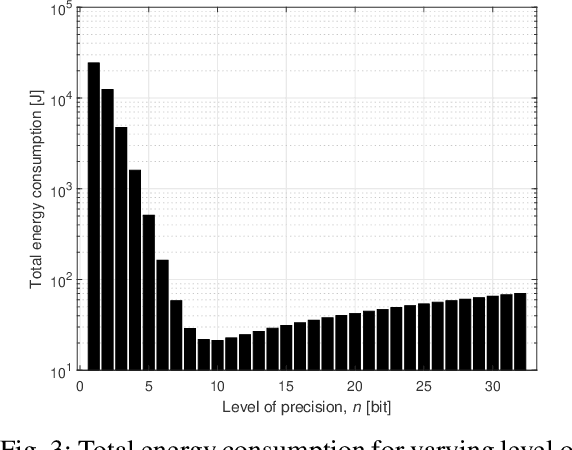
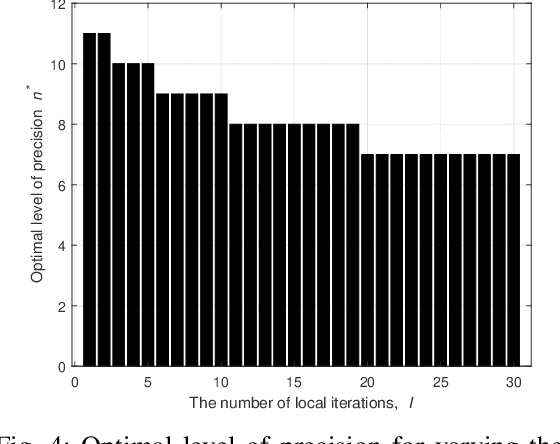
Deploying federated learning (FL) over wireless networks with resource-constrained devices requires balancing between accuracy, energy efficiency, and precision. Prior art on FL often requires devices to train deep neural networks (DNNs) using a 32-bit precision level for data representation to improve accuracy. However, such algorithms are impractical for resource-constrained devices since DNNs could require execution of millions of operations. Thus, training DNNs with a high precision level incurs a high energy cost for FL. In this paper, a quantized FL framework, that represents data with a finite level of precision in both local training and uplink transmission, is proposed. Here, the finite level of precision is captured through the use of quantized neural networks (QNNs) that quantize weights and activations in fixed-precision format. In the considered FL model, each device trains its QNN and transmits a quantized training result to the base station. Energy models for the local training and the transmission with the quantization are rigorously derived. An energy minimization problem is formulated with respect to the level of precision while ensuring convergence. To solve the problem, we first analytically derive the FL convergence rate and use a line search method. Simulation results show that our FL framework can reduce energy consumption by up to 53% compared to a standard FL model. The results also shed light on the tradeoff between precision, energy, and accuracy in FL over wireless networks.
Common Language for Goal-Oriented Semantic Communications: A Curriculum Learning Framework
Nov 15, 2021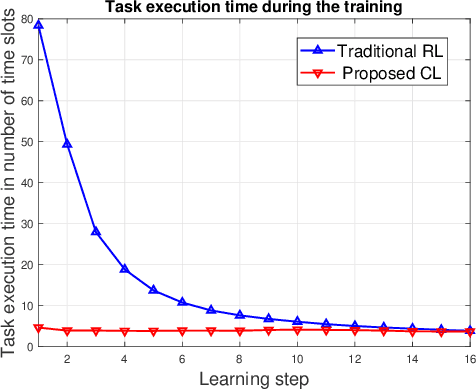
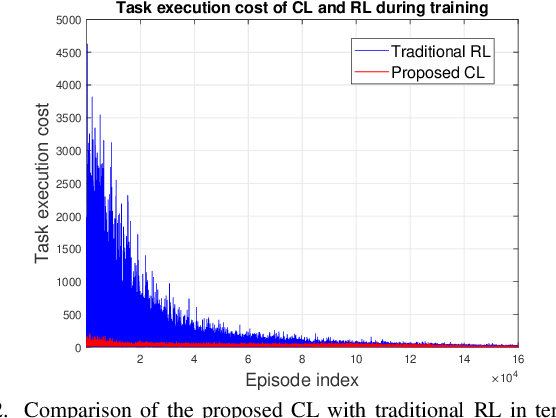
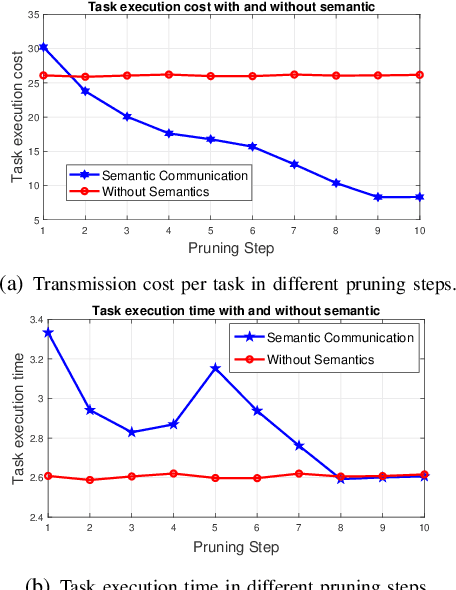
Semantic communications will play a critical role in enabling goal-oriented services over next-generation wireless systems. However, most prior art in this domain is restricted to specific applications (e.g., text or image), and it does not enable goal-oriented communications in which the effectiveness of the transmitted information must be considered along with the semantics so as to execute a certain task. In this paper, a comprehensive semantic communications framework is proposed for enabling goal-oriented task execution. To capture the semantics between a speaker and a listener, a common language is defined using the concept of beliefs to enable the speaker to describe the environment observations to the listener. Then, an optimization problem is posed to choose the minimum set of beliefs that perfectly describes the observation while minimizing the task execution time and transmission cost. A novel top-down framework that combines curriculum learning (CL) and reinforcement learning (RL) is proposed to solve this problem. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution time, and transmission cost during training.