 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyGiantALM: A Compact Audio-Language Model for Intent-Aware Reasoning under Resource Constraints
Jun 07, 2026Current advancements in Audio Reasoning rely on massive Large Audio-Language Models (LALMs), hindering deployment in resource-constrained environments. We introduce TinyGiantALM, a compact 1.5B efficiency-oriented alternative. Instead of brute-force scaling, we propose an Instruction-Aware Feature Refinement framework using a Query-guided Projector and Semantic Gating to filter acoustic signals based on user intent. On the MMAR benchmark, TinyGiantALM achieves 46.4% zero-shot accuracy, significantly outperforming 7B-13B baselines. While a reasoning gap in logical narrative remains versus 30B+ models and certain trade-offs exist in overly dense or spatial scenes, our approach notably surpasses models up to 8x larger in disentangling mixed-modality environments. These findings demonstrate that architectural precision offers a tangible pathway to secure robust perception capabilities on edge-friendly scales.
FSM-Net: An Efficient Frequency-Spatial Network for Real-World Deblurring
May 29, 2026Real-world image deblurring demands both high-fidelity restoration and computational efficiency, a balance existing methods often struggle to achieve. In this paper, we propose FSM-Net (Frequency-Spatial Multi-branch Network), a highly efficient solution that secured 2nd place in the NTIRE 2026 Challenge on Efficient Real-World Deblurring. FSM-Net pioneers a dual-domain approach: a novel Frequency Attention module explicitly recovers high-frequency structural details via FFT, while a Cross-Gated Vision E-Branchformer at the bottleneck captures global dependencies with linear complexity. To ensure robust convergence, we employ a progressive curriculum training strategy guided by a composite loss function (Multi-Scale Charbonnier, Structural Edge, and Frequency). Evaluated on the RSBlur benchmark, FSM-Net achieves an outstanding 33.144 dB PSNR with only 4.94M parameters and 159.35 GMACs (at 1920x1200 resolution). By effectively pushing the Pareto frontier of efficiency and quality, FSM-Net establishes a strong baseline for resource-constrained image restoration.
TinyGiantVLM: A Lightweight Vision-Language Architecture for Spatial Reasoning under Resource Constraints
Aug 25, 2025Reasoning about fine-grained spatial relationships in warehouse-scale environments poses a significant challenge for existing vision-language models (VLMs), which often struggle to comprehend 3D layouts, object arrangements, and multimodal cues in real-world industrial settings. In this paper, we present TinyGiantVLM, a lightweight and modular two-stage framework designed for physical spatial reasoning, distinguishing itself from traditional geographic reasoning in complex logistics scenes. Our approach encodes both global and region-level features from RGB and depth modalities using pretrained visual backbones. To effectively handle the complexity of high-modality inputs and diverse question types, we incorporate a Mixture-of-Experts (MoE) fusion module, which dynamically combines spatial representations to support downstream reasoning tasks and improve convergence. Training is conducted in a two-phase strategy: the first phase focuses on generating free-form answers to enhance spatial reasoning ability, while the second phase uses normalized answers for evaluation. Evaluated on Track 3 of the AI City Challenge 2025, our 64M-parameter base model achieved 5th place on the leaderboard with a score of 66.8861, demonstrating strong performance in bridging visual perception and spatial understanding in industrial environments. We further present an 80M-parameter variant with expanded MoE capacity, which demonstrates improved performance on spatial reasoning tasks.
* Accepted for presentation at the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025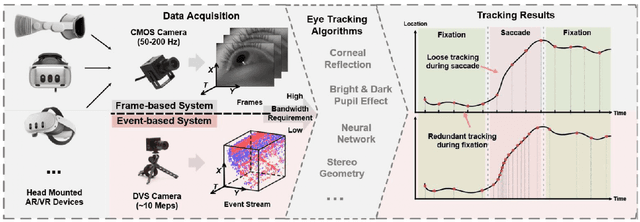
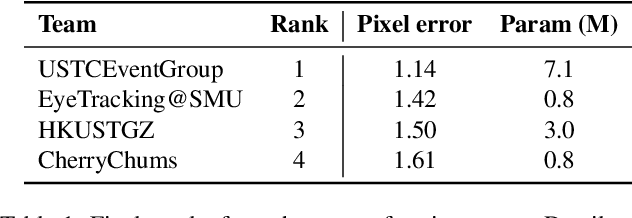

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Dual-Path Enhancements in Event-Based Eye Tracking: Augmented Robustness and Adaptive Temporal Modeling
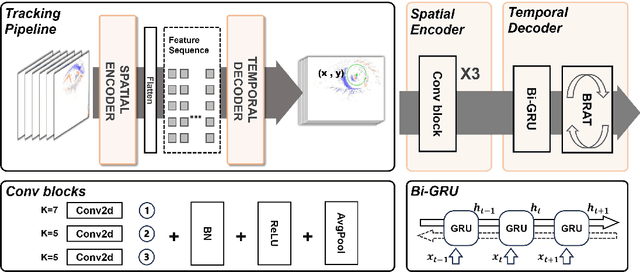
Apr 14, 2025Event-based eye tracking has become a pivotal technology for augmented reality and human-computer interaction. Yet, existing methods struggle with real-world challenges such as abrupt eye movements and environmental noise. Building on the efficiency of the Lightweight Spatiotemporal Network-a causal architecture optimized for edge devices-we introduce two key advancements. First, a robust data augmentation pipeline incorporating temporal shift, spatial flip, and event deletion improves model resilience, reducing Euclidean distance error by 12% (1.61 vs. 1.70 baseline) on challenging samples. Second, we propose KnightPupil, a hybrid architecture combining an EfficientNet-B3 backbone for spatial feature extraction, a bidirectional GRU for contextual temporal modeling, and a Linear Time-Varying State-Space Module to adapt to sparse inputs and noise dynamically. Evaluated on the 3ET+ benchmark, our framework achieved 1.61 Euclidean distance on the private test set of the Event-based Eye Tracking Challenge at CVPR 2025, demonstrating its effectiveness for practical deployment in AR/VR systems while providing a foundation for future innovations in neuromorphic vision.